[爬虫] demo 以及使用etree示例
Posted 长虹剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[爬虫] demo 以及使用etree示例相关的知识,希望对你有一定的参考价值。
记载一下使用的爬虫代码
主要是活用 etree
文章目录
etree 多跳转解析
from _chj.comm.pic import *
import requests
from lxml import etree
import pandas as pd
import urllib.parse
from requests_html import HTMLSession
session = HTMLSession()
class params:
base_url="https://www.fangpi.net"
sbase_url="https://www.fangpi.net/s/"
fsing="tmp/sing.txt"
furl_out="tmp/sing_url.sh"
dsong = "tmp/songs"
def main():
f1_get_files()
f2_mk_wget()
def f2_mk_wget():
chj_file.mkdir( params.dsong )
exec_cmd( f" bash params.furl_out " )
def f1_get_files():
fp = open(params.furl_out, "w")
for i, line in enumerate( readlines( params.fsing ) ):
arr = line.split()
if len(arr) == 1:
nm, uname = line, None
else:
nm, uname = line.split()
uname = uname.strip()
outurl, nm = get_link( nm.strip(), uname )
if outurl is not None:
#fp.write( f"i outurl nm\\n")
ss = f"wget -c 'outurl' -O params.dsong/i-nm\\n"
fp.write( ss )
def get_link( query_nm, query_uname ):
url = params.sbase_url + urllib.parse.quote( query_nm )
r = requests.get(url)
tree = etree.HTML( r.text )
r.close()
items = tree.xpath(".//table[@class='table']/tbody/tr")
for tr in items:
#tds = tr.xpath(".//td")
nm = tr[0].xpath("./a/text()")[0].strip()
unm = tr[1].text
urlsing = tr[2].xpath("./a/@href")[0]
#print( nm, unm, urlsing )
if nm == query_nm:
if query_uname is None or unm == query_uname:
url_sing = params.base_url + urlsing
href, download = get_sing_url( url_sing )
return href, download
return None, None
#df = pd.read_html(url, encoding='utf-8',header=0)
# 这个会失去链接
def get_sing_url( url ):
r = session.get(url) # 必须要渲染否则不行
r.html.render()
tree = etree.HTML( r.html.html )
r.close()
#print( r.html.html )
a = tree.xpath(".//div[@class='input-group-append']/a[@id='btn-download-mp3']")[0]
href = a.xpath("./@href")[0]
download = a.xpath("./@download")[0]
#print( href, download )
#r = requests.get( href )
return href, download
if __name__ == "__main__":
main()
讲解
先获得list中合适的条目,然后解析获得最终音频的位置
普通网站爬取
先放上整体代码,再讲解
# -*- coding:utf-8 -*
import urllib.request
from lxml import etree
root_url="http://www.itangyuan.com/"
url=f"root_url/book/catalogue/14432108.html"
def main():
# 第一步
html = urllib.request.urlopen(url).read()
tree = etree.HTML(html)
links = tree.xpath(".//div[@class='catalog']/ul/li/a/@href")[2:]
# 第二部
for i, link in enumerate( links ):
link = f"root_urllink"
html = urllib.request.urlopen(link).read()
tree = etree.HTML(html).xpath(".//div[@class='section-main-con']")
if len(tree) == 0: continue
if len(tree) != 1: p("WARNING", link, len(len(tree)))
tree = tree[0]
title = tree.xpath(".//h1/text()")[0]
content = "\\n\\n".join( tree.xpath(".//p/text()")[:-1] )
with open(f"res/i+1:03d.title.txt", "w", encoding='utf-8') as fp:
fp.write(content)
# 下面这个函数忽略
def main2():
with open("虹猫蓝兔七侠传小说.md", "w", encoding="utf-8") as fpout:
for fnm in glob.glob("res/*"):
with open(fnm, encoding="utf-8") as fp:
nm = fnm.split('\\\\')[1].split('.txt')[0]
fpout.write(f"# nm\\n")
fpout.write(fp.read()+"\\n")
if __name__ == '__main__':
main()
讲解
- 分析网页 http://www.itangyuan.com/book/catalogue/14432108.html , 确定每个章节的网址
- 加载每个网址,分析其中一个页面,获得相应的内容
由于这个网页内容比较简单,直接 xpath 索引就全部获得了。
注意事项:
1)每次 xpath 完是个数组,可能应为是通过 class 索引缘故,未详细探索
2)用 utf-8 保存
使用 chrome 分析网站
想爬取一些数据
比如
https://tv.cctv.com/2019/12/31/VIDEOX9ykqMX1J0rlAhEmjeo191231.shtml
chrome 中分析发现一个链接
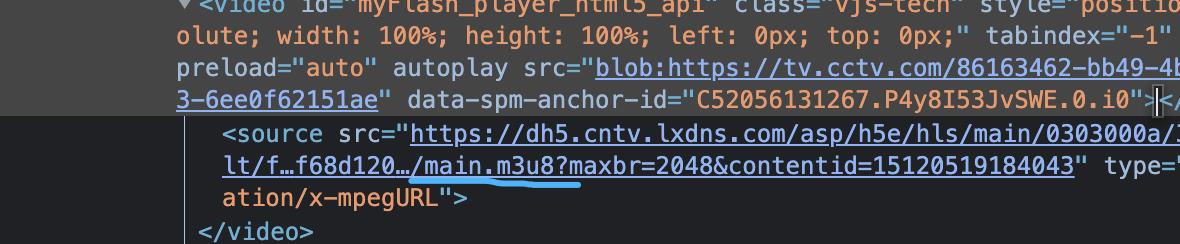
使用 ffmpeg 下载之后发现有问题 ( ffmpeg -i xx.m3u8 -c copy demo.mp4 ), 视频是模糊的
进一步分析网络包
先 clear 一下
刷新一下页面,分析包,然后发现下面那个请求,获得一个本质上是 json 的 url
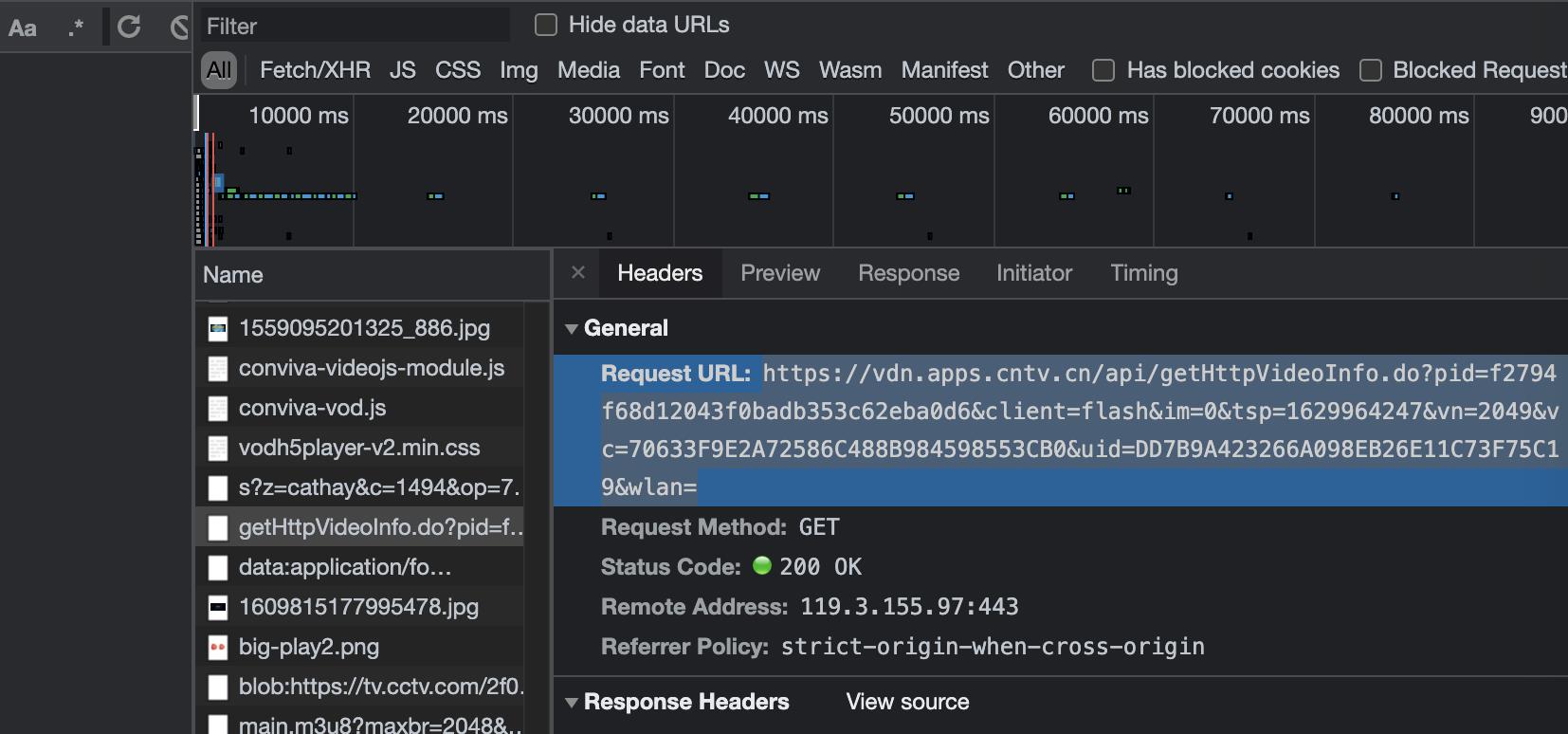
可以在这个 url 中 分析得到

不过chrome 默认是没有装 jsonview插件的可以装一下
小的实例汇总
lyric
divs = tree.xpath(".//div[@label-module='para*']")
for e in divs: print( e.text)
以上是关于[爬虫] demo 以及使用etree示例的主要内容,如果未能解决你的问题,请参考以下文章