Pytorch学习笔记:数据读取机制(DataLoader与Dataset)
Posted 路人贾'ω'
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch学习笔记:数据读取机制(DataLoader与Dataset)相关的知识,希望对你有一定的参考价值。
目录
上节回顾:Pytorch学习笔记(1):基本概念、安装、张量操作、逻辑回归
一、 DataLoader
torch.utils.data.Dataloader
功能:DataLoader类位于Pytorch的utils类中,构建可迭代的数据装载器。我们在训练的时候,每一个for循环,每一次iteration,就是从DataLoader中获取一个batch_size大小的数据的。

• dataset:Dataset类,决定数据从哪读取及如何读取
• batchsize:批大小
• num_works:是否多进程读取数据,可以减少数据读取时间,加快训练速度(一般设为4,8,16)
• shuffle:每个epoch是否乱序
• drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
注意:Epoch、Iteration和Batchsize之间的关系
Epoch:所有训练样本都已输入到模型中,称为一个epoch
Iteration:一批样本输入到模型中,称之为一个Iteration
Batchsize:批大小,决定一个Epoch有多少个Iteration
举个栗子:
例 1:样本总数:80 , Batchsize:8
1 Epoch = 10 Iteration
例 2:样本总数 87 , Batchsize:8
1 Epoch = 10 Iteration ——> drop_last = True
1 Epoch = 11 Iteration ——> drop_last = False
具体代码段如下:
dataloader = DataLoader(dogsdset,batch_size=32,num_workers=2)
for imgs , labels in dataloader:
#在数据集上应用深度学习算法二、Dataset
torch.utils.data.Dataset
功能:用来定义数据从哪里读取以及如何读取。Dataset抽象类,所有自定义的Dataset需要继承它,并且复写
__getitem__()
getitem #接收一个索引,返回一个样本

• __init__:在初始化过程中,应该输入数据目录信息和其他允许访问的信息。例如从csv文件加载数据,也可以使用加载文件名列表,其中每个文件名代表一个数据。注意:在该过程中还未加载数据。
• __len__: 该方法用于返回数据集的大小。例如,如果某些目录中有一些图像,则必须实现一种对构成该数据集文件总数进行计数的方法。
• getitem:该方法用于接收一个索引idx,返回一个样本并返回数据集中对应的数据和标签,是数据加载的核心方法。
具体代码段如下:
class DogVSCatDataset(Dataset):
def _init_(self, root_dir, size=(224,224)):
self.files = glob(root_dir)
self.size = size
def _len_(self):
return len(self.files)
def _getitem_(self,idx):
img = np.asarray(Image.open(self.files[idx]).resize(self.size))
label = self.files[idx].split('/')[-2]
return img, label三、数据读取
数据读取包含 3 个方面
- 读取哪些数据:每个 Iteration 读取一个 Batchsize 大小的数据,每个 Iteration 应该读取哪些数据。
- 从哪里读取数据:如何找到硬盘中的数据,应该在哪里设置文件路径参数
- 如何读取数据:不同的文件需要使用不同的读取方法和库。

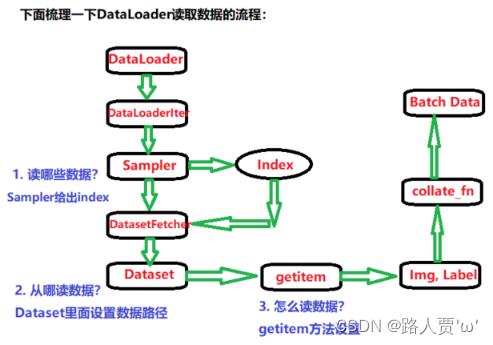
流程解读:
DataLoader的作用就是构建一个数据装载器, 根据我们提供的batch_size的大小, 将数据样本分成一个个的batch去训练模型,而这个分的过程中需要把数据取到,这个就是借助Dataset的getitem方法。
这样也就清楚了,如果我们想使用Pytorch读取数据的话,首先应该自己写一个MyDataset,这个要继承Dataset类并且实现里面的__getitem__(self,idx)方法,在这里面告诉机器怎么去读数据,运算根据每次调用时的idx返回对应元素。 当然这里还有个细节,就是还要覆盖里面的__len__(self)方法,这个是告诉机器一共有多少个样本数据。 要不然机器没法去根据batch_size的个数去确定有多少批数据。这个写起来也很简单,返回总的样本的个数即可。
def __len__(self):
return len(self.data_info)
这样, 机器就可以根据Dataset去硬盘中读取数据,接下来就是用DataLoader构建一个可迭代的数据装载器,传入如何读取数据的机制Dataset,传入batch_size, 就可以返回一批批的数据了。 当然这个装载器具体使用是在模型训练的时候。 当然,由于DataLoader是一个可迭代对象,当我们构建完毕之后,也可以简单的看下里面的数据到底长什么样, 大致代码是:
for x, y in train_loader:
print(x, y)
break
# 这样应该能看到一个批次的数据
以上就是Pytorch读取机制DataLoader和Dataset的原理部分了。
本文参考:
[PyTorch 学习笔记] 2.1 DataLoader 与 DataSet - 知乎 (zhihu.com)
系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)
以上是关于Pytorch学习笔记:数据读取机制(DataLoader与Dataset)的主要内容,如果未能解决你的问题,请参考以下文章