Golang 并发: goroutine and channel
Posted Wallace JW
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Golang 并发: goroutine and channel相关的知识,希望对你有一定的参考价值。
前言
在前面的系列文章中,我们基本已经讲解完了 Golang 的数据类型、流程控制。函数、方法、接口、断言等基本知识点,这些内容其实和其他语言大同小异,除了语法以外并没有什么特别的地方。
那么,Go 语言和其他语言的区别是什么?她独特的魅力到底在哪里呢?答案就是并发。作为为数不多的语言层面就支持多协程的编程语言之一,Go 语言的并发编程简洁而优雅,并且拥有极为出色的性能。
本文会简单介绍进程/线程/协程的基本概念,之后介绍 GO 语言中的并发机制,最后介绍 go/channel/select 关键字的语法,本文只介绍基于消息的并发,关于共享变量的并发会在之后的文章中介绍。
文章目录
进程、线程和协程
首先我们先来简单的了解一些并发中的基本概念,关于并发的优点相信不需要再加赘述了,我们直接开始介绍并发的执行体:进程(process)、进程内的线程(thread)以及线程内的协程(coroutine)。
进程
进程是一个抽象的概念,官方定义是:进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配的最小单位,由程序、数据集合和进程控制块三部分组成。
操作系统通过进程控制块 (PCB,Processing Control Block) 来实现对进程的控制和管理,一个进程常见的基本状态有五种:
- 初始:进程刚被创建,由于其他进程正占有CPU所以得不到执行,只能处于初始状态。
- 就绪:只有处于就绪状态的经过调度才能到执行状态
- 执行:任意时刻处于执行状态的进程只能有一个。
- 等待(阻塞):进程等待某件事件完成
- 停止:进程结束
一个执行中的程序就是一个进程,进程负责独立的功能,占据独立的内存,互不影响,CPU 控制权在不同进程之间交换的机制成为上下文切换 (context switch)。进程之间通过管道、消息队列、信号量机制、共享内存、套接字等方式进行通信。
多进程是在操作系统层面进行并发的基本模式,由于每个进程有自己独立的内存空间,所以相对稳定安全,但是进程的切换开销较大,因此并不是一种良好的并发模型。
线程
为了弥补进程的缺陷,在进程之下又抽象出了线程的概念,一个进程可以有多个线程,多个线程共享进程的内存空间,线程是程序执行流的最小单元,是处理器调度和分派的基本单位,一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。
多线程程序中至少有一个主线程,通常为 main 函数所在的线程,所有线程都是它的子线程,当主线程终止时,资源被释放,所有子线程也同时结束。
跟进程类似,操作系统管理线程的控制块为 TCB(Thread Control Block),在单核处理器中,比较常见的线程调度方式是时间片轮转法来进行抢占式进程调度,一个线程执行一小段时间后,被操作系统暂停,继续执行另外一个线程的一小段,多个线程轮流执行,由于 CPU 的执行效率非常高,时间片非常短,因此效果上来看就是多个线程在同时执行,这种方式叫做并发;在多核处理器中,不同 CPU 处理不同的线程,线程间不互相抢占 CPU 资源,这种方式叫做并行。
协程
在传统程序中,每个请求占用一个线程来完成完整的业务逻辑,系统的吞吐能力取决于每个线程的操作耗时,当某一些线程非常耗时,一直处于阻塞状态,其他线程便会处于空闲状态,降低整个系统的吞吐量。协程是一种用户态的轻量级线程,一个线程可以拥有多个协程,协程对于内核来说是不可见的,由程序自行调度,因此,协程的切换开销远远小于线程。
协程调度切换时,将寄存器上下文和栈保存到内存,在切回来的时候,恢复先前保存的寄存器上下文和栈,基本没有内核切换的开销,可以不加锁的访问全局变量,直接进入上一次调用的状态,上下文切换非常快。
小结
| 进程 | 线程 | 协程 | |
|---|---|---|---|
| 定义 | 操作系统资源分配的最小单位 | 操作系统资源调度的最小单位 | 用户态的轻量级线程,内核不可见 |
| 资源共享 | 有独立的内存空间 | 同一进程间的线程共享内存 | 共享线程的内存,拥有独立的寄存器上下文和栈 |
| 切换开销 | 开销大 | 内核态切换,开销小 | 用户态切换,无需上下文切换,开销极小 |
| 数据同步 | 进程间通信 | 用锁等机制确保数据的一致性和可见性 | 控制共享资源不加锁,只需判断状态,效率高 |
| 调用机制 | 同步 | 同步 | 异步 |
Go 并发机制
简单理解了进程线程协程的概念之后,我们来正式的介绍 Go 的并发机制,在 Go 语言中,协程被命名为 goroutine,Go 的并发思想是基于 CSP 模型来实现的,下面先来简单了解一下 CSP 模型。
CSP 模型
CSP 模型是主流的并发模型之一,全称为 顺序通信进程 (Communicating Sequential Processes),核心思想是多个线程之间是独立的个体,在不同的线程中不共享变量,线程间通过channel 来进行通信,形如 Process1 --> Channel --> Process2,两个实体之间是匿名的,这个就实现了实体之间的解耦,R. Pike 的一句名言描述了 CSP 模型的精髓:
Do not communicate by sharing memory; instead, share memory by communicating.
Go 语言其实主要只用到了模型中 Process 和 Channel 两个部分,分别为 goroutine 和 channel,channel 为通信的中间媒介,goroutine 1 需要跟 goroutine 2 通信时,直接把信息放在 channel 里,goroutine 2 自行决定何时去获取信息(有点类似消息队列),两个 goroutine 之间可以有很多个 channel,由于不需要自己处理通信的操作,所以 goroutine 的性能会有所提升。
MPG 模式
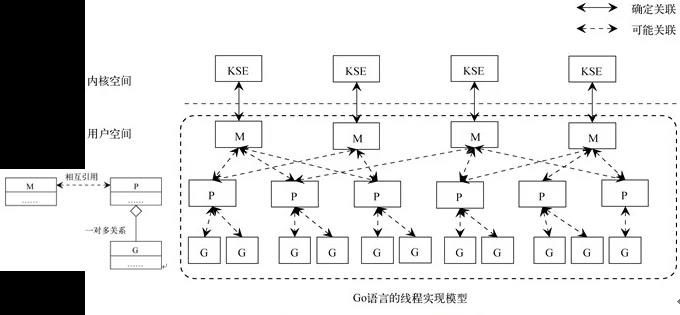
在 go语言中,goroutine 是并发执行的实体,go 的调度器为 MPG 的模式,代表调度的三种重要结构:
M: Machine, 内核中的线程,是操作系统中真正的执行体P: Processor, 调度器,控制 G 在哪一个 M 中执行,只有当 M 与 P 关联后才能执行 Go 代码G: goroutine,程序创建的用户态执行体
简单来讲,就是虽然并发的执行体是 goroutine(G),但是在操作系统中真正的执行体是线程(M),需要由调度器(P)来决定在何时将哪一个 G 放在M 中执行。
具体的调度实现逻辑非常复杂,本文先不做展开,有兴趣的朋友可以先参考《Go 语言设计与实现》中的 6.5 调度器 章节。
Goroutine
说了这么多,终于要开始介绍语法了,Go 语言中的 goroutine 实现无比优雅,想要让哪个函数在 goroutine 中实现,只需要在调用时加上 go 关键字即可。如下:
func Add(x, y int)
z := x + y
fmt.Println(z)
func main()
for i := 0; i < 10; i ++
go Add(i, i)
看起来简洁得让人陶醉不是吗,可惜现实没有那么美好,当我们真正运行的时候,会发现其实没有输出任何东西,这是因为,程序运行从初始化 main 开始,到 main 返回时结束,而 main 作为主协程,不会等待子协程的运行结果,而 main 结束的时候,子协程全部被结束,在这个例子中,因为 main 非常短,所以子协程还没来得及执行,就已经被结束了。
因此,当我们想要看到正确的结果,需要给 main 加一个等待时间,如下:
func main()
for i := 0; i < 10; i ++
go Add(i, i)
time.Sleep(1 * time.Second)
再次执行,可以看到乱序的输出,这也可以看出,i 从 0 到 9 并不是顺序执行而是并发执行。
8
10
14
18
16
6
2
4
0
12
当然了,如果要使用这种加等待时间这种愚蠢的方式,那就完全说不上优雅了,在 go 语言中,我们使用 channel 来解决这个问题。
Channel
Channel 是 Go 语言在语言级别提供的 goroutine 间的通信机制,用于在多个 goroutine 之间传递信息,Channel 是线程安全的,本质是一种队列,先进先出。在 Go 语言中,Channel 是类型相关的,一个 Channel 变量只能传递一种类型的值,我们先来了解一下 Channel 的语法。
创建和关闭
Channel 有三种类型,分别为双向、单向仅接收、单向仅发送:
chan T // 双向 channel,即可以发送 T类型 的数据,也可以接收 T类型 的数据
chan<- T // 单向 channel,只可以用来发送(写入) T类型 的数据
<-chan T // 单向 channel,只可以用来接收(读出) T类型 的数据
和 slice 和 map 类似,可以使用 make 来创建 channel 变量,第二个参数代表 channel 的缓存容量(buffer capacity),表示channel 中可以存储的数据大小,可以缺省,表示缓存大小为 0。
var c0 chan int // 仅声明 channel 变量
c1 := make(chan int) // 定义不带 buffer 的 channel
c2 := make(chan int, 100) // 定义 buffer 可以存储 100 个 int 的 channel
// 类似的,使用 cap(c2) 获取带 buffer 的 channel 的容量,用 len(c2) 获取实际存储的元素数量
c2 <- 1
c2 <- 1
fmt.Println(cap(c2)) // 100
fmt.Println(len(c2)) // 2
不再使用的 channel 需要使用 close() 函数关闭,通常使用 defer 关键字在初始化的时候就注明关闭语句,函数返回时自动关闭:
ch := make(chan int)
defer close(ch)
往一个已经被关闭的 channel 中继续发送数据会导致 panic,判断 channel 是否为关闭状态的语法和 map 类似,使用多重返回值的 ok 来判断,ok 为 true 表示开启,false 表示关闭:
x, ok := <-c1
发送和接收
channel 最常用的语法为发送(写入)和接收(读出),语法形式非常形象,使用箭头来表示数据的流向。
Send:把数据发送给 channel,写入到 channel 中
c1 <- value
如果 channel 的 buffer 已满,那么往 channel 中写入数据就会阻塞,直到有其他 goroutine 将 channel 中的数据读取出来。
Receive:从 channel 中接收数据,从 channel 中读出
value = <- ch
如果 channel 是空的,那么从 channel 中读取数据就会阻塞,直到有其他 goroutine 往 channel 中写入数据。
如果是带 buffer 的 channel,也可以用 range 来循环读数:
for i := range c
fmt.Println("received: ", i)
那么让我们加入 channel 来更优雅的实现前面的 Add() 方法
func main()
chs := make([]chan int, 10) // 定义一个包含 10 个 channel 的 slice,分配给下文的 10 个 goroutine
for i := 0; i < 10; i ++
chs[i] = make(chan int) // 初始化 channel 并传入 Add 方法中
go Add(i, i, chs[i])
// 从 10 个 channel 中依次读取数据,在数据被写入之前,这个操作是阻塞的
// 因此会一直等待到有写入数据(也就是对应的 goroutine 已经执行完成)才会被执行
// 当 goroutine 中往 channel 中写入数据的时候相当于通知接收者自己已经完成了
for _, c := range chs
<-c
func Add(x, y int, ch chan int)
z := x + y
fmt.Println(z)
ch <- 1 // goroutine 的 Add() 函数完成后,通过ch <- 1 向对应的 channel 中写入数据
需要注意的是,由于使用的是 10 个无 buffer 的 channel,因此虽然 10 个 goroutine 之间是异步的,但是 sub goroutine 和 main 之间是同步的,main 要等到所有 goroutine 执行完成之后才能执行。
可以形象的想象一下上述代码的执行过程,10 个员工(sub goroutine)在分别做自己的任务,完成后发个消息,然后员工就可以撤了,老板(main goroutine)要一直等到收到 10 个消息的时候,才知道所有工作已经完成,这时候老板才能收工。运行结果如下:
2
6
4
8
12
18
16
0
10
14
select
由于使用 channel 的时候会存在发生阻塞的情况,如果不进行处理,很有可能导致整个 goroutine 锁死,这种情况下代码执行会报错
fatal error: all goroutines are asleep - deadlock!
因此使用 channel 时通常都要考虑超时场景,以便在超出设定时间时及时终止任务并返回超时信息,我们可以可以使用 select 语句实现超时处理。
在 go 语言中有 switch 和 select 两种分支结构,二者语法非常相似,select 可以用于监听多个 channnel 的情况,在每个 case 分支条件中都是一个面向 channel 的 IO 操作,如下:
select
case <-c1: // 如果成功从 c1 中读取数据,执行此分支
// dosomething...
case c2 <- 1: // 如果成功写入数据到 c2,执行此分支
// dosomething...
default:
// dosomething...
回到上面提到的阻塞问题,可以这样实现一个最简单的超时机制:
timeout := make(chan bool, 1)
// 在一个 goroutine 中实现一个超时等待函数
go func()
time.Sleep(10e9) // 等待 10s
timeout <- true // 10s 后就把 true 写入 timeout channel
()
select
case <-ch: // 等待从 ch 中读取数据,如果读取到数据,则执行内容
// dosomething...
case <-timeout: // 如果一直没有从 ch 中读取到数据,那么 10s 后,timeout 中被写入数据,从 timeout 读取成功
fmt.Println("timeout")
return
Pipeline
channel 也可以将多个 goroutine 串联在一起,将一个 goroutine 的输出通过管道作为下一个 goroutine 的输入,形成一个类似 linux 中 管道 (pipeline) 的功能,举个例子,我们用 pipeline 来实现一个简单的求平方的功能。
func main()
chNum := make(chan int) // 用来发送原始数字的 channel
chRes := make(chan int) // 用来发送计算结果的 channel
// Counter,用于生成原始数据的 goroutine
go func()
for i := 1; i <= 10; i++
chNum <- i // 每生成一个数字就写入 chNum, 在被读取之前阻塞,被读取后再写入下一个
close(chNum) // 生成 10 个数字后关闭
()
// Calculator,用于计算的 goroutine
go func()
for i := 1; i <= 10; i++
x := <- chNum // 从 chNum 中读取原始数据
chRes <- x * x // 将计算结果接入 chRes
close(chRes) // 计算 10 次后关闭
()
// Printer,用于打印结果
for
if res, ok := <-chRes; ok // 判断 chRes 是否关闭,若关闭代表已经全部打印完, 退出
fmt.Println(res)
else
break
可以看到,由于各个 goroutine 之间是串行的,因此运行结果是有序的
1
4
9
16
25
36
49
64
81
100
总结
本文我们先简单了解了进程、线程和协程的基本概念,然后进一步了解 go 语言的 CSP 并发模型以及 MPG 调度模式,最后在学习 go 语言并发中最重要的go/channel/select 三个关键字的语法。
至此我们已经了解了 go 语言并发最核心的基本知识点,goroutine 和 channel 在实际使用中很容易出现各种各样的阻塞,死锁的问题,因此还是需要在实战中多多使用才能熟练掌握。
以上是关于Golang 并发: goroutine and channel的主要内容,如果未能解决你的问题,请参考以下文章