JRaft框架学习笔记
Posted Shi Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JRaft框架学习笔记相关的知识,希望对你有一定的参考价值。
一、Raft算法回顾
1.1、Raft简介
Raft是基于日志复制的一致性算法。
Raft效果等同于Paxos,但实现不同,raft比Paxos更容易理解。
Raft有三个关键性的一致性元素:
1)Leader选举(Leader Selection)
2)日志复制(Log Replication)
3)安全(Safety)
一致性算法用于允许一组Server如一个整体般工作,能自动让他的成本在失败后恢复正常。在raft之前,一致性算法主要是paxos,但paxos难于理解,raft应运而生。
假如一个raft集群包括5台服务器,能最多容忍2台服务器不可用,而集群正常。在任意时间,集群中的每台服务器一定会处于以下三种状态之一:Leader、Candidate、Follower。
在正常情况下,只有一个服务器是Leader,剩下的服务器是 Follower。Follower 是被动的:它们不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。Leader来处理所有来自客户端的请求(如果一个客户端与 Follower 进行通信,Follower 会将信息发送 Leader)。Candidate 是用来选取一个新的 Leader 的。
1.2、复制状态机
一致性算法是在复制状态机(Replicated State Machine)的背景下提出来的。一组 Server 的状态机通过使用相同状态的副本,并且即使有一部分 Server 宕机了它们仍然能够继续运行,这可在分布式系统中解决容错问题。
复制状态机架构图:
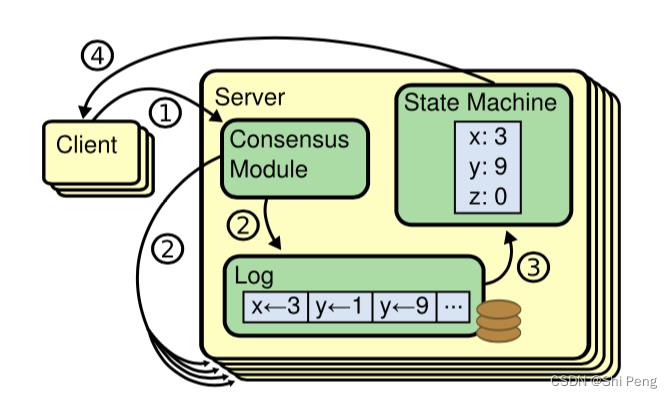
1、复制状态机通过日志实现
1)每台机器一份日志
2)每个日志条目包含一条命令
3)状态机按顺序执行命令
2、应用于实际系统的一致性算法一般有以下特性
1)确保安全性:在网络延迟、分区、丢包、重复和重排序等情况下保证安全(不会返回错误结果)
2)高可用性:集群中超过半数Server可以,集群可正常使用
3)不依赖时序保证一致性:如时钟错误、消息延迟等情况可保证一致性
4)一条命令能够尽可能快的在大多数节点对一轮RPC调用响应时完成:只要多数派Server复制成功即算完成,个别相应慢的Server不会拖累整个集群性能。
3、Paxos 算法的不足
1)算法复杂度高, 较难理解
2)工程复杂度高, 难以在实际环境中实现
1.3、Leader选举
Raft 使用一种心跳机制来触发 Leader 的选举。当服务器启动时,它们会初始化为 Follower。一台服务器会一直保持 Follower 的状态,只要它们能够收到来自 Leader 或者 Candidate 的有效 RPC。Leader 会向所有 Follower 周期性发送心跳(不带有任何日志条目的 AppendEntries RPC)来保证它们的 Leader 地位。如果一个 Follower 在一个周期内没有收到心跳信息,就叫做选举超时,然后它就会认为没有可用的 Leader,并且开始一次选举以选出一个新的 Leader。
为了开始选举,一个 Follower 会自增它的当前任期并且转换状态为 Candidate。然后,它会给自己投票并且给集群中的其他服务器发送 RequestVote RPC。一个 Candidate 会一直处于该状态,直到下列三种情形之一发生:
1)它赢得了选举;
2)另一台服务器赢得了选举;
3)一段时间后没有任何一台服务器赢得了选举。
如果一个 Candidate 在一个任期内收到了来自集群中大多数服务器的投票,就会赢得选举。在一个任期内,一台服务器最多能给一个 Candidate 投票,按照先到先服务原则。大多数原则使得在一个任期内最多有一个 Candidate 能赢得选举,一旦有一个 Candidate 赢得了选举,它就会成为 Leader。然后,它会向其他服务器发送心跳信息来建立自己的 Leader 地位,并且组织新的选举。
当一个 Candidate 等待别人的选票时,它有可能会收到来自其他服务器发来的声明其为 Leader 的 AppendEntries RPC。如果这个Leader 的任期(包含在它的 RPC 中)比当前 Candidate 的当前任期要大,则 Candidate 认为该 Leader 合法,并且转换自己的状态为 Follower。如果在这个 RPC 中的任期小于 Candidate 的当前任期,则候选人会拒绝此次 RPC, 继续保持 Candidate 状态。
第三种情形是,一个 Candidate 既没有赢得选举,也没有输掉选举:如果许多 Follower 在同一时刻都成为了 Candidate,选票会被分散,可能没有 Candidate 能获得大多数的选票。当这种情形发生时,每一个 Candidate 都将会超时,并且通过自增任期号和发起另一轮 RequestVote RPC 来开始新的选举。然而,如果没有其它手段来分配选票的话,这种情形可能会无限的重复下去。
Raft 使用随机的选举超时时间来确保第三种情形很少发生,并且能够快速解决。为了防止在一开始是选票就被瓜分,选举超时时间是在一个固定的间隔内随机选出来的(例如150-300ms)。这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其它服务器超时之前赢得选举,并且向其它服务器发送心跳信息。同样的机制被用于选票被瓜分的情况。每一个 Candidate 在开始一次选举的时候会重置一个随机的选举超时时间,等待直到超时后,再进行下一次选举。这能够减小在新的选举中一开始选票就被瓜分的可能性。
1.4、日志复制
一旦选出了 Leader,它就开始接收客户端的请求。每一个客户端请求都包含一条需要被复制状态机(Replicated State Machine)执行的命令。Leader 把这条命令作为新的日志条目加入到它的日志中去,然后并行的向其它服务器发起 AppendEntries RPC,要求其它服务器复制这个条目。当这个条目被安全的复制之后,Leader 会将这个条目应用到它的状态机中并且会向客户端返回执行结果。如果 Follower 崩溃了或者运行缓慢或者是网络丢包了,Leader 会无限的重试 AppendEntries RPC(甚至在它向客户端响应之后),直到有的 Follower 最终存储了所有的日志条目。
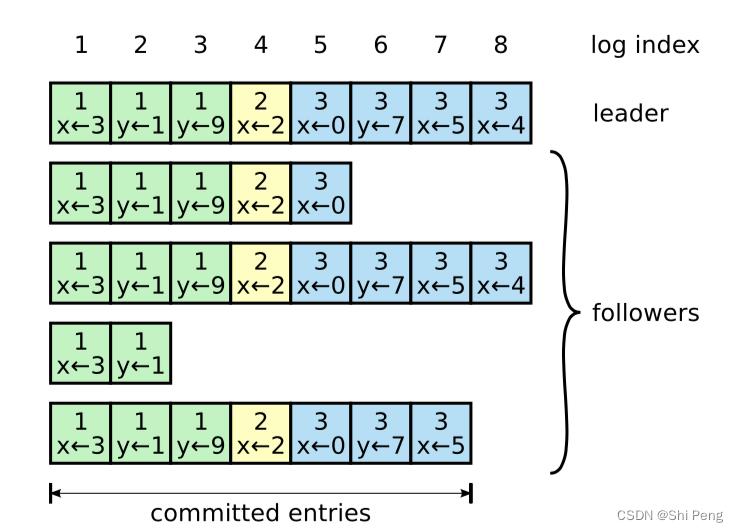
如上图所示,日志由有序编号的日志条目组成。每个日志条目包含它被创建时的任期号(每个方块中的数字),并且包含用于状态机执行的命令。如果一个条目能够被状态机安全执行,就被认为可以提交了。
日志条目中的任期号用来检测在不同服务器上日志的不一致性,每个日志条目也包含一个整数索引来表示它在日志中的位置。
Leader 决定什么时候将日志条目应用到状态机是安全的;这种条目被称为是已提交的(Committed)。Raft 保证可已提交的日志条目是持久化的,并且最终会被所有可用的状态机执行。一旦被 Leader 创建的条目已经复制到了大多数的服务器上,这个条目就称为已提交的。Leader 跟踪记录它所知道的已提交的条目的最大索引值,并且这个索引值会包含在之后的 AppendEntries RPC 中(包括心跳中),为的是让其他服务器都知道这个条目已经提交。一旦一个 Follower 知道了一个日志条目已经是已提交的,它会将该条目应用至本地的状态机(按照日志顺序)。
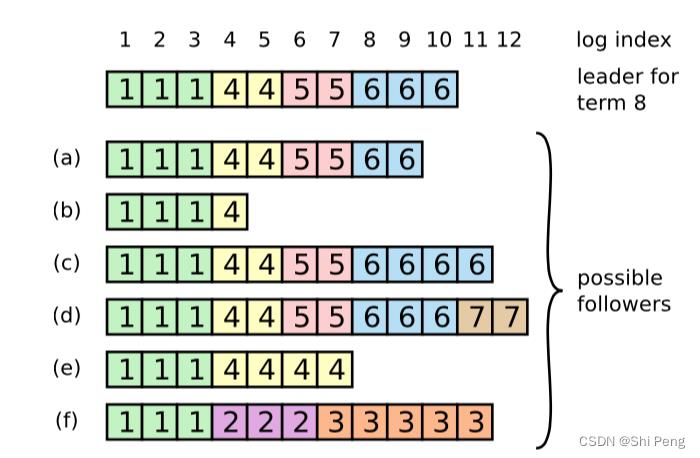
当最上面的 Leader 掌权之后,Follower 日志可能有以下情况(a~f)。一个格子表示一个日志条目;格子中的数字是它的任期。情况如下:
- 一个 Follower 可能会丢失一些条目(a, b)
- 一个 Follower 可能多出来一些未提交的条目(c, d)
- 一个 Follower 或者两种情况都有(e, f)
例如,场景f在如下情况下就会发生:如果一台服务器在任期2时是Leader并且向它的日志中添加了一些条目,然后在将它们提交之前就宕机了,之后它很快重启了,成为了任期3的 Leader,又向它的日志中添加了一些条目,然后在任期2和任期3中的条目提交之前它又宕机了,并且几个任期内都一直处于宕机状态。
在Raft算法中,Leader 通过强制 Follower 复制它的日志来处理日志的不一致。这就意味着,在 Follower 上的冲突日志会被Leader的日志覆盖。
为了使得 Follower 的日志和自己的一致,Leader 需要找到 Follower 与它的日志一致的地方,然后删除 Follower 在该位置之后的条目,然后将自己在该位置之后的条目发送给 Follower。这些操作都在 AppendEntries RPC 进行一致性检查时完成。Leader 给每一个Follower 维护了一个 nextIndex,它表示 Leader 将要发送给该追随者的下一条日志条目的索引。当一个 Leader 开始掌权时,它会将 nextIndex 初始化为它的最新的日志条目索引数+1。如果一个 Follower 的日志和 Leader 的不一致,AppendEntries 一致性检查会在下一次 AppendEntries RPC 时返回失败。在失败之后,Leader 会将 nextIndex 递减然后重试 AppendEntries RPC。最终 nextIndex 会达到一个 Leader 和 Follower 日志一致的地方。这时,AppendEntries 会返回成功,Follower 中冲突的日志条目都被移除了,并且添加所缺少的上了 Leader 的日志条目。一旦 AppendEntries 返回成功,Follower 和 Leader 的日志就一致了,这样的状态会保持到该任期结束。
1.5、安全性
上述描述了 Raft 算法是如何选举和复制日志的。然而,到目前为止描述的机制并不能充分的保证每一个状态机会按照相同的顺序执行相同的指令。例如,一个follower可能会进入不可用状态同时Leader已经提交了若干的日志条目,然后这个Follower可能会被选举为Leader并且覆盖这些日志条目;因此,不同的状态机可能会执行不同的指令序列。
Raft通过在Leader选举时增加一些限制来完善 Raft 算法。这一限制保证了任何的Leader对于给定的任期号,都拥有了之前任期的所有被提交的日志条目。
1.5.1、选举限制
在任何基于Leader的一致性算法中,Leader都必须存储所有已经提交的日志条目。在某些一致性算法中,例如 Viewstamped Replication,某个节点即使是一开始并没有包含所有已经提交的日志条目,它也能被选为Leader。这些算法都包含一些额外的机制来识别丢失的日志条目并把他们传送给新的Leader,要么是在选举阶段要么在之后很快进行。不幸的是,这种方法会导致相当大的额外的机制和复杂性。Raft 使用了一种更加简单的方法,它可以保证所有之前的任期号中已经提交的日志条目在选举的时候都会出现在新的Leader中,不需要传送这些日志条目给Leader。这意味着日志条目的传送是单向的,只从Leader传给跟随者,并且Leader从不会覆盖自身本地日志中已经存在的条目。
Raft 使用投票的方式来阻止一个候选人赢得选举除非这个候选人包含了所有已经提交的日志条目。候选人为了赢得选举必须联系集群中的大部分节点,这意味着每一个已经提交的日志条目在这些服务器节点中肯定存在于至少一个节点上。如果候选人的日志至少和大多数的服务器节点一样新,那么他一定持有了所有已经提交的日志条目。请求投票 RPC 实现了这样的限制: RPC 中包含了候选人的日志信息,然后投票人会拒绝掉那些日志没有自己新的投票请求。
Raft 通过比较两份日志中最后一条日志条目的索引值和任期号定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。如果两份日志最后的条目任期号相同,那么日志比较长的那个就更加新。
1.5.2、提交之前任期内的日志条目
领导者知道一条当前任期内的日志记录是可以被提交的,只要它被存储到了大多数的服务器上。如果一个领导者在提交日志条目之前崩溃了,未来后续的领导者会继续尝试复制这条日志记录。然而,一个领导者不能断定一个之前任期里的日志条目被保存到大多数服务器上的时候就一定已经提交了。下图展示了一种情况,一条已经被存储到大多数节点上的老日志条目,也依然有可能会被未来的领导者覆盖掉。
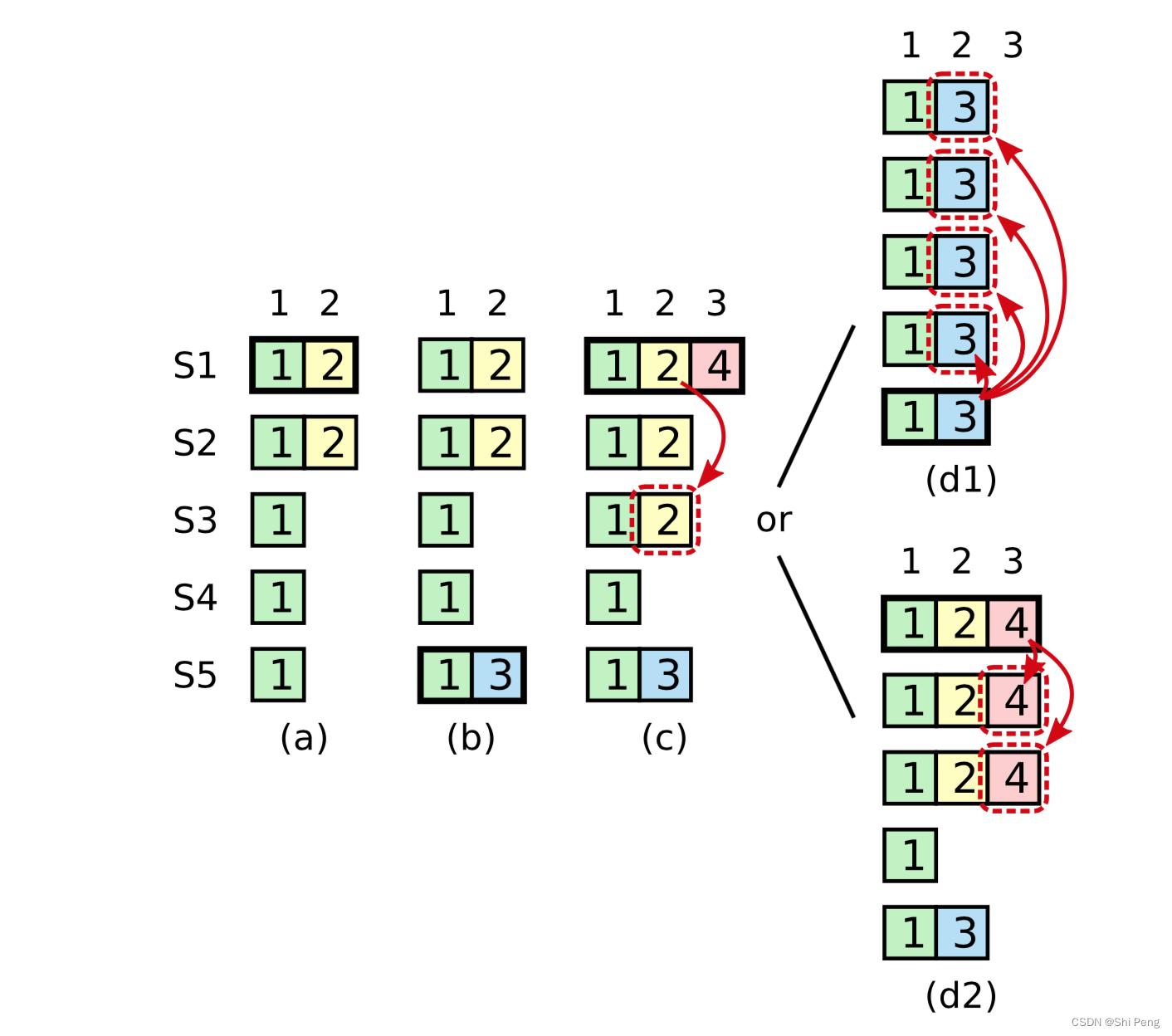
上图的时间序列展示了为什么Leader无法决定对老任期号的日志条目进行提交。在 (a) 中,S1 是领导者,部分的复制了索引位置 2 的日志条目。在 (b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处。然后到 ©,S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。如果 S1 在 (d1) 中又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票),然后覆盖了他们在索引 2 处的日志。反之,如果在崩溃之前,S1 把自己主导的新任期里产生的日志条目复制到了大多数机器上,就如 (d2) 中那样,那么在后面任期里面这些新的日志条目就会被提交(因为 S5 就不可能选举成功)。 这样在同一时刻就同时保证了,之前的所有老的日志条目就会被提交。
为了消除上图里描述的情况,Raft 永远不会通过计算副本数目的方式去提交一个之前任期内的日志条目。只有领导者当前任期里的日志条目通过计算副本数目可以被提交;一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配特性,之前的日志条目也都会被间接的提交。在某些情况下,领导者可以安全的知道一个老的日志条目是否已经被提交(例如,该条目是否存储到所有服务器上),但是 Raft 为了简化问题使用一种更加保守的方法。
当领导者复制之前任期里的日志时,Raft 会为所有日志保留原始的任期号, 这在提交规则上产生了额外的复杂性。在其他的一致性算法中,如果一个新的领导者要重新复制之前的任期里的日志时,它必须使用当前新的任期号。Raft 使用的方法更加容易辨别出日志,因为它可以随着时间和日志的变化对日志维护着同一个任期编号。另外,和其他的算法相比,Raft 中的新领导者只需要发送更少日志条目(其他算法中必须在他们被提交之前发送更多的冗余日志条目来为他们重新编号)。但是,这在实践中可能并不十分重要,因为领导者更换很少。
1.6、Follower和Candidate崩溃
跟随者和候选人崩溃后的处理方式比领导者要简单的多,并且他们的处理方式是相同的。如果跟随者或者候选人崩溃了,那么后续发送给他们的 RPCs 都会失败。Raft 中处理这种失败就是简单的通过无限的重试;如果崩溃的机器重启了,那么这些 RPC 就会完整的成功。如果一个服务器在完成了一个 RPC,但是还没有响应的时候崩溃了,那么在他重新启动之后就会再次收到同样的请求。Raft 的 RPCs 都是幂等的,所以这样重试不会造成任何问题。例如一个跟随者如果收到附加日志请求但是他已经包含了这一日志,那么他就会直接忽略这个新的请求。
1.7、持久化状态和服务重启
Raft 服务器必须持久化足够的信息到稳定存储中来保证服务的安全重启。每一个服务需要持久化当前的任期和投票选择;这是必要的,以防止服务器在相同的任期内投票两次,或者将新领导者的日志条目替换为废弃领导者的日志条目。每一个服务也要在统计日志提交状态之前持久化该日志,这可以防止已经提交的条目在服务器重启时丢失或“未提交”。
其他状态变量在重启之后丢失是安全的,因为他们都可以重新创建。最有趣的示例是 commitIndex,可以在重新启动时将其安全地重新初始化为零。即使每个服务器都同时重新启动,commitIndex 也只会暂时滞后于其真实值。选举领导者并能够提交新条目后,其 commitIndex 将增加,并将快速将该 commitIndex 传播给其关注者。
1.8、时间和可用性
Raft 的要求之一就是安全性不能依赖时间:整个系统不能因为某些事件运行的比预期快一点或者慢一点就产生了错误的结果。但是,可用性(系统可以及时的响应客户端)不可避免的要依赖于时间。例如,如果消息交换比服务器故障间隔时间长,候选人将没有足够长的时间来赢得选举;没有一个稳定的领导人,Raft 将无法工作。
领导人选举是 Raft 中对时间要求最为关键的方面。Raft 可以选举并维持一个稳定的领导人,只要系统满足下面的时间要求:
广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF)
在这个不等式中,广播时间指的是从一个服务器并行的发送 RPCs 给集群中的其他服务器并接收响应的平均时间;然后平均故障间隔时间就是对于一台服务器而言,两次故障之间的平均时间。广播时间必须比选举超时时间小一个量级,这样领导人才能够发送稳定的心跳消息来阻止跟随者开始进入选举状态;通过随机化选举超时时间的方法,这个不等式也使得选票瓜分的情况变得不可能。选举超时时间应该要比平均故障间隔时间小上几个数量级,这样整个系统才能稳定的运行。当领导人崩溃后,整个系统会大约相当于选举超时的时间里不可用;我们希望这种情况在整个系统的运行中很少出现。
广播时间和平均故障间隔时间是由系统决定的,但是选举超时时间是我们自己选择的。Raft 的 RPCs 需要接收方将信息持久化的保存到稳定存储中去,所以广播时间大约是 0.5 毫秒到 20 毫秒,取决于存储的技术。因此,选举超时时间可能需要在 10 毫秒到 500 毫秒之间。大多数的服务器的平均故障间隔时间都在几个月甚至更长,很容易满足时间的需求。
二、JRaft框架学习
2.1、JRaft简介
JRaft 是一个基于 RAFT 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。 使用 JRaft 你可以专注于自己的业务领域,由 JRaft 负责处理所有与 RAFT 相关的技术难题,并且 JRaft 非常易于使用。
JRaft 是从百度的 C++ braft 移植而来,做了一些优化和改进。
2.2、JRaft设计
设计图:
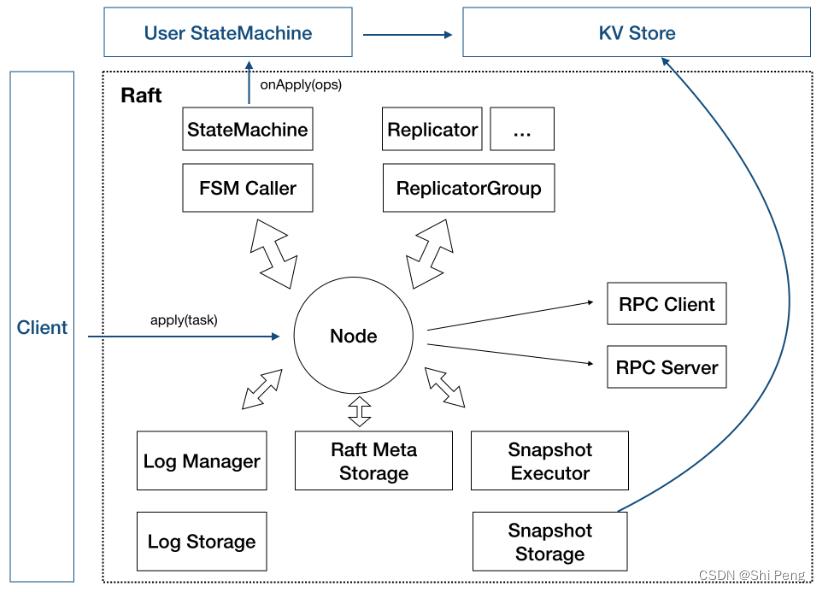
1、Node
Node是Raft 分组中的一个节点,连接封装底层的所有服务。
用户看到的主要服务接口,特别是 apply(task) 用于向 raft group 组成的复制状态机集群提交新任务应用到业务状态机。
2、存储
上图靠下的部分均为存储相关。
1)Log存储
记录 raft 用户提交任务的日志,将日志从 leader 复制到其他节点上。
1)LogStorage:是存储实现,默认实现基于 RocksDB 存储,也可以很容易扩展自己的日志存储实现。
2)LogManager:负责对底层存储的调用,对调用做缓存、批量提交、必要的检查和优化
2)Metadata存储
元信息存储,记录 raft 实现的内部状态,比如当前 term、投票给哪个节点等信息
3)Snapshot 存储
用于存放用户的状态机 snapshot 及元信息,可选。
1)SnapshotStorage 用于 snapshot 存储实现。
2)SnapshotExecutor 用于 snapshot 实际存储、远程安装、复制的管理
3、状态机
FSMCaller主要就是将日志同步到状态机
1)StateMachine:用户核心逻辑的实现,核心是 onApply(Iterator) 方法, 应用通过 Node#apply(task) 提交的日志到业务状态机
2)FSMCaller : 封装对业务 StateMachine 的状态转换的调用以及日志的写入等,一个有限状态机的实现,做必要的检查、请求合并提交和并发处理等
4、复制
1)Replicator:用于 leader 向 followers 复制日志,也就是 raft 中的 AppendEntries 调用,包括心跳存活检查等
2)ReplicatorGroup:用于单个 raft group 管理所有的 replicator,必要的权限检查和派发
5、RPC
RPC 模块用于节点之间的网络通讯
1)RPC Server:内置于 Node 内的 RPC 服务器,接收其他节点或者客户端发过来的请求,转交给对应服务处理
2)RPC Client:用于向其他节点发起请求,例如投票、复制日志、心跳等
6、KV Store
KV Store 是各种 Raft 实现的一个典型应用场景,JRaft 中包含了一个嵌入式的分布式 KV 存储实现(JRaft-RheaKV)
7、JRaft Group
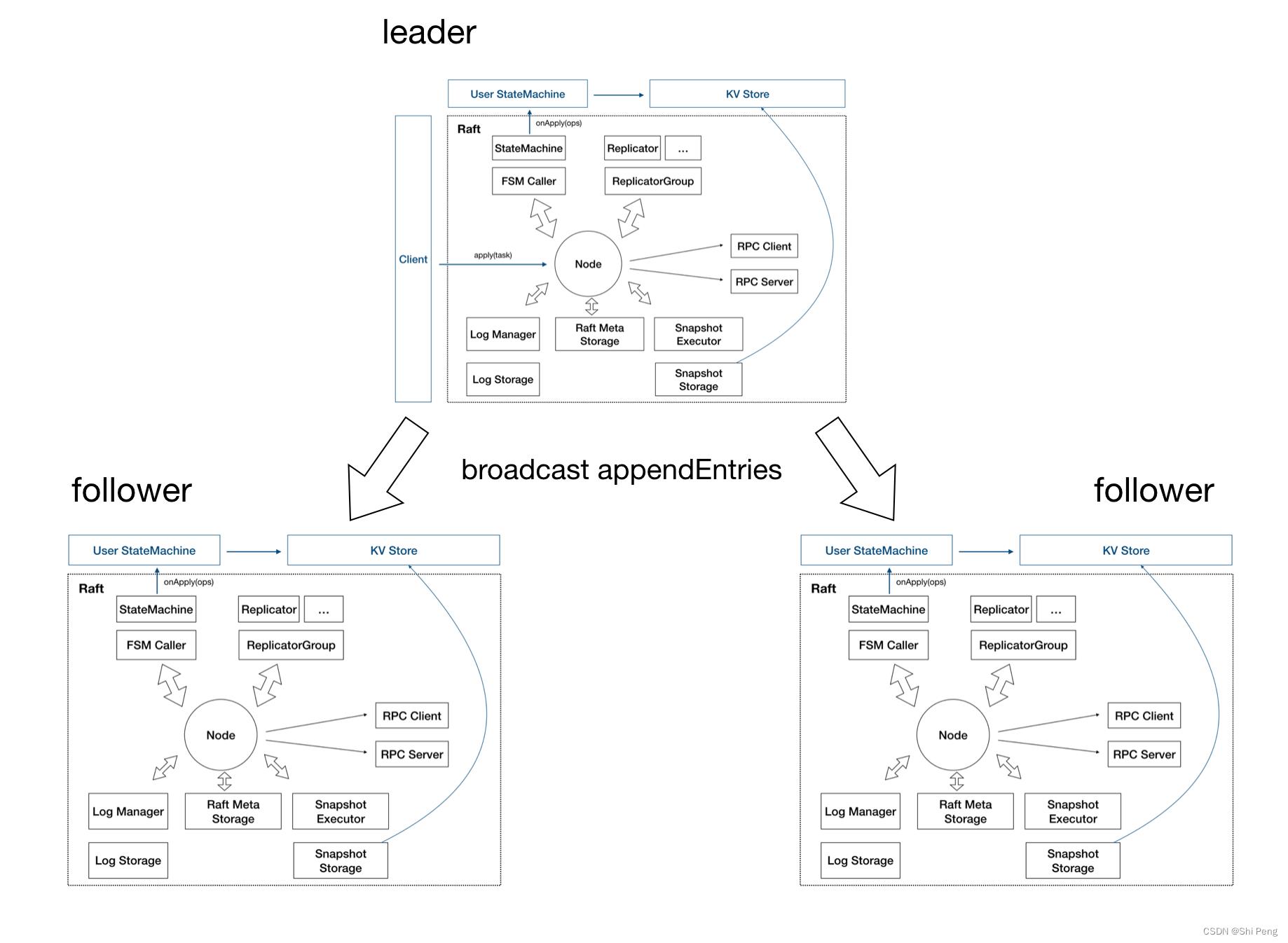
单个节点的 JRaft-node 是没什么实际意义的,需要加入到JRaft Group。
下面是三副本的 JRaft 架构图:
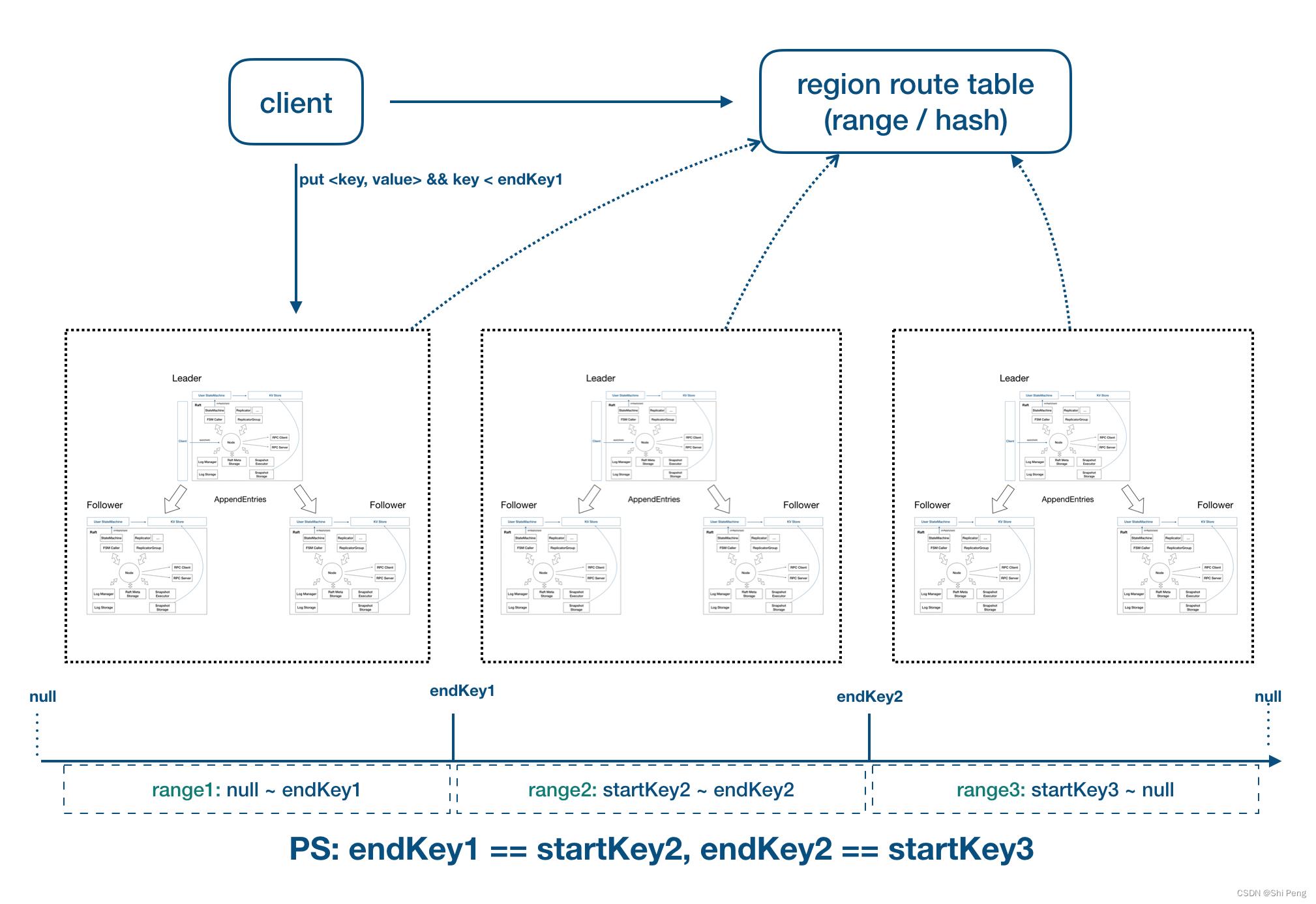
8、JRaft Multi Group
单个 Raft group 是无法解决大流量的读写瓶颈的,JRaft 自然也要支持 multi-raft-group
2.3、JRaft应用场景
场景1:Leader 选举
场景2:分布式锁服务,比如 zookeeper,在 JRaft 中的 RheaKV 模块提供了完整的分布式锁实现
场景3:高可靠的元信息管理,可直接基于 JRaft-RheaKV 存储
场景4:分布式存储系统,如分布式消息队列、分布式文件系统、分布式块系统等等
2.4、JRaft使用
2.4.1、基本概念
1、log index:提交到 raft group 中的任务都将序列化为一条日志存储下来,每条日志一个编号,在整个 raft group 内单调递增并复制到每个 raft 节点。
2、term:在整个 raft group 中单调递增的一个 long 数字,可以简单地认为表示一轮投票的编号,成功选举出来的 leader 对应的 term 称为 leader term,在这个 leader 没有发生变更的阶段内提交的日志都将拥有相同的 term 编号。
2.4.2、配置和辅助类
jraft 的配置和辅助工具相关接口和类:
2.4.2.1、地址Endpoint
Endpoint:表示一个服务地址,包括 IP 和端口。
Endpoint addr = new Endpoint("localhost", 8080);
String s = addr.toString(); // 结果为 localhost:8080
PeerId peer = new PeerId();
boolean success = peer.parse(s); // 可以从字符串解析出地址,结果为 true
问题:如果把每个partition作为raft group的元素,而一个节点有多个partition,那么怎样用raft呢?难道用不同的peerId区分?-- 看来是的。
2.4.2.2、节点PeerId
PeerId 表示一个 raft 协议的参与者(leader/follower/candidate),它由三元素组成: ip:port:index, IP 就是节点的 IP, port 就是端口, index 表示同一个端口的序列号,如果没有用到,默认是0。预留此字段是为了支持同一个端口启动不同的 raft 节点,通过 index 区分。
创建一个 PeerId, index 指定为 0, ip 和端口分别是 localhost 和 8080,代码demo:
PeerId peer = new PeerId("localhost", 8080);
Endpoint addr = peer.getEndpoint(); // 获取节点地址
int index = peer.getIdx(); // 获取节点序号,目前一直为 0
String s = peer.toString(); // 结果为 localhost:8080
boolean success = peer.parse(s); // 可以从字符串解析出 PeerId,结果为 true
2.4.2.3、配置 Configuration
Configuration 表示一个 raft group 的配置,也就是参与者列表:
PeerId peer1 = ...
PeerId peer2 = ...
PeerId peer3 = ...
// 由 3 个节点组成的 raft group
Configuration conf = new Configuration();
conf.addPeer(peer1);
conf.addPeer(peer2);
conf.addPeer(peer3);
2.4.2.4、工具类 JRaftUtils
为了方便创建 Endpoint/PeerId/Configuration 等对象, jraft 提供了 JRaftUtils 来快捷地从字符串创建出所需要的对象:
Endpoint addr = JRaftUtils.getEndpoint("localhost:8080");
// Create a peer from a string in the form of "host:port[:idx]"
PeerId peer = JRaftUtils.getPeerId("localhost:8080");
// 三个节点组成的 raft group 配置,注意节点之间用逗号隔开
Configuration conf = JRaftUtils.getConfiguration("localhost:8081,localhost:8082,localhost:8083");
2.4.2.5、回调 Closure 和状态 Status
Closure 就是一个简单的 callback 接口, jraft 提供的大部分方法都是异步的回调模式,结果通过此接口通知:
public interface Closure
/**
* Called when task is done.
*
* @param status the task status.
*/
void run(Status status);
结果通过 Status 告知,Status#isOk() 告诉你成功还是失败,错误码和错误信息可以通过另外两个方法获取:
boolean success= status.isOk();
RaftError error = status.getRaftError(); // 错误码,RaftError 是一个枚举类
String errMsg = status.getErrorMsg(); // 获取错误详情
Status 提供了一些方法来方便地创建错误码及错误信息:
// 创建一个成功的状态
Status ok = Status.OK();
// 创建一个失败的错误,错误信息支持字符串模板
String filePath = "/tmp/test";
// 第一个参数是错误码,第二个参数是错误信息
Status status = new Status(RaftError.EIO, "Fail to read file from %s", filePath);
2.4.2.6、任务 Task
Task 是用户使用 jraft 最核心的类之一,用于向一个 raft 复制分组提交一个任务,这个任务提交到 leader,并复制到其他 follower 节点。
Task 包括:
1)ByteBuffer data:任务的数据,用户应当将要复制的业务数据通过一定序列化方式(比如 java/hessian2) 序列化成一个 ByteBuffer,放到 task 里。
2)long expectedTerm = -1:任务提交时预期的 leader term,如果不提供(也就是默认值 -1 ),在任务应用到状态机之前不会检查 leader 是否发生了变更,如果提供了(从状态机回调中获取,参见下文),那么在将任务应用到状态机之前,会检查 term 是否匹配,如果不匹配将拒绝该任务。
3)Closure done:任务的回调,在任务完成的时候通知此对象,无论成功还是失败。这个 closure 将在 StateMachine#onApply(iterator) 方法应用到状态机的时候,可以拿到并调用,一般用于客户端应答的返回。
创建一个简单 Task 实例:
Closure done = ...;
Task task = new Task();
task.setData(ByteBuffer.wrap("hello".getBytes()));
task.setDone(done);
任务的 closure 还可以使用特殊的 TaskClosure 接口,额外提供了一个 onCommitted 回调方法:
public interface TaskClosure extends Closure
/**
* Called when task is committed to majority peers of the RAFT group but before it is applied to state machine.
*
* <strong>Note: user implementation should not block this method and throw any exceptions.</strong>
*/
void onCommitted();
当 jraft 发现 task 的 done 是 TaskClosure 的时候,会在 RAFT 日志提交到 RAFT group 之后(并复制到多数节点),应用到状态机之前调用 onCommitted 方法。
2.4.3、服务端
服务端部分主要介绍 jraft 服务端编程的主要接口和类。
2.4.3.1、迭代器 Iterator
提交的 task ,在 jraft 内部会做累积批量提交,应用到状态机的是一个 task 迭代器,通过 com.alipay.sofa.jraft.Iterator 接口表示。
例子:
Iterator it = ....
//遍历迭代任务列表
while(it.hasNext())
ByteBuffer data = it.getData(); // 获取当前任务数据
Closure done = it.done(); // 获取当前任务的 closure 回调
long index = it.getIndex(); // 获取任务的唯一日志编号,单调递增, jraft 自动分配
long term = it.getTerm(); // 获取任务的 leader term
...逻辑处理...
it.next(); // 移到下一个task
请注意, 如果 task 没有设置 closure,那么 done 可能会是 null,另外在 follower 节点上, done 也是 null,因为 done 不会被复制到除了 leader 节点之外的其他 raft 节点。
这里有一个优化技巧,通常 leader 获取到的 done closure,可以扩展包装一个 closure 类 包含了没有序列化的用户请求,那么在逻辑处理部分可以直接从 closure 获取到用户请求,无需通过 data 反序列化得到,减少了 leader 的 CPU 开销,具体可参见 counter 例子。
2.4.3.2、状态机 StateMachine
提交的任务最终将会复制应用到所有 raft 节点上的状态机,状态机通过 StateMachine 接口表示,它的主要方法包括:
1)void onApply(Iterator iter):最核心的方法,应用任务列表到状态机,任务将按照提交顺序应用。请注意,当这个方法返回的时候,我们就认为这一批任务都已经成功应用到状态机上,如果你没有完全应用(比如错误、异常),将会被当做一个 critical 级别的错误,报告给状态机的 onError 方法,错误类型为 ERROR_TYPE_STATE_MACHINE。
2)void onError(RaftException e):当 critical 错误发生的时候,会调用此方法,RaftException 包含了 status 等详细的错误信息;当这个方法被调用后,将不允许新的任务应用到状态机,直到错误被修复并且节点被重启。因此对于任何在开发阶段发现的错误,都应当及时做修正。
3)void onLeaderStart(long term):当状态机所属的 raft 节点成为 leader 的时候被调用,成为 leader 当前的 term 通过参数传入。
4)void onLeaderStop(Status status):当前状态机所属的 raft 节点失去 leader 资格时调用,status 字段描述了详细的原因,比如主动转移 leadership、重新发生选举等。
5)void onStartFollowing(LeaderChangeContext ctx):当一个 raft follower 或者 candidate 节点开始 follow 一个 leader 的时候调用,LeaderChangeContext 包含了 leader 的 PeerId/term/status 等上下文信息。并且当前 raft node 的 leaderId 属性会被设置为新的 leader 节点 PeerId。
6)void onStopFollowing(LeaderChangeContext ctx):当一个 raft follower 停止 follower 一个 leader 节点的时候调用,这种情况一般是发生了 leadership 转移,比如重新选举产生了新的 leader,或者进入选举阶段等。同样 LeaderChangeContext 描述了停止 follow 的 leader 的信息,其中 status 描述了停止 follow 的原因。
7)void onConfigurationCommitted(Configuration conf):当一个 raft group 的节点配置提交到 raft group 日志的时候调用:通常打印个日志即可。
8)void onShutdown():当状态机所在 raft 节点被关闭的时候调用,可以用于一些状态机的资源清理工作,比如关闭文件等。
9)onSnapshotSave 和 onSnapshotLoad:Snapshot 的保存和加载
因为 StateMachine 接口的方法比较多,并且大多数方法可能不需要做一些业务处理,因此 jraft 提供了一个 StateMachineAdapter 桥接类,方便适配实现状态机,除了强制要实现 onApply 方法外,其他方法都提供了默认实现,也就是简单地打印日志,用户可以选择实现特定的方法:
public class TestStateMachine extends StateMachineAdapter
private AtomicLong leaderTerm = new AtomicLong(-1);
@Override
public void onApply(Iterator iter)
while(iter.hasNext())
//应用任务到状态机
iter.next();
@Override
public void onLeaderStart(long term)
//保存 leader term
this.leaderTerm.set(term);
super.onLeaderStart(term);
2.4.3.3、Raft 节点 Node
Node 接口表示一个 raft 的参与节点,他的角色可能是 leader、follower 或者 candidate,随着选举过程而转变。
Node 接口最核心的几个方法如下:
1)void apply(Task task):提交一个新任务到 raft group,此方法是线程安全并且非阻塞,无论任务是否成功提交到 raft group,都会通过 task 关联的 closure done 通知到。如果当前节点不是 leader,会直接失败通知 done closure。
2)PeerId getLeaderId():获取当前 raft group 的 leader peerId,如果未知,返回 null
3)shutdown 和 join:前者用于停止一个 raft 节点,后者可以在 shutdown 调用后等待停止过程结束。
4)void snapshot(Closure done):触发当前节点执行一次 snapshot 保存操作,结果通过 done 通知。
创建一个 raft 节点可以通过 RaftServiceFactory.createRaftNode(String groupId, PeerId serverId) 静态方法:
- groupId: 该 raft 节点的 raft group Id
- serverId:该 raft 节点的 PeerId
创建后还需要初始化才可以使用,初始化调用 boolean init(NodeOptions opts) 方法,需要传入 NodeOptions 配置。
NodeOptions 主要配置如下:
// 一个 follower 当超过这个设定时间没有收到 leader 的消息后,变成 candidate 节点的时间。
// leader 会在 electionTimeoutMs 时间内向 follower 发消息(心跳或者复制日志),如果没有收到,
// follower 就需要进入 candidate状态,发起选举或者等待新的 leader 出现,默认1秒。
private int electionTimeoutMs = 1000;
// 自动 Snapshot 间隔时间,默认一个小时
private int snapshotIntervalSecs = 3600;
// 当节点是从一个空白状态启动(snapshot和log存储都为空),那么他会使用这个初始配置作为 raft group
// 的配置启动,否则会从存储中加载已有配置。
private Configuration initialConf = new Configuration();
// 最核心的,属于本 raft 节点的应用状态机实例。
private StateMachine fsm;
// Raft 节点的日志存储路径,必须有
private String logUri;
// Raft 节点的元信息存储路径,必须有
private String raftMetaUri;
// Raft 节点的 snapshot 存储路径,可选,不提供就关闭了 snapshot 功能。
private String snapshotUri;
// 是否关闭 Cli 服务,默认不关闭
private boolean disableCli = false;
// 内部定时线程池大小,默认按照 cpu 个数计算,需要根据应用实际情况适当调节。
private int timerPoolSize = Utils.cpus() * 3 > 20 ? 20 : Utils.cpus() * 3;
// Raft 内部实现的一些配置信息,特别是性能相关。
private RaftOptions raftOptions = new RaftOptions();
NodeOptions 最重要的就是设置三个存储的路径,以及应用状态机实例,如果是第一次启动,还需要设置 initialConf 初始配置节点列表。
然后就可以初始化创建的 Node:
NodeOptions opts = ...
Node node = RaftServiceFactory.createRaftNode(groupId, serverId);
if(!node.init(opts))
throw new IllegalStateException("启动 raft 节点失败,具体错误信息请参考日志。");
创建和初始化结合起来也可以直接用 createAndInitRaftNode 方法:
Node node = RaftServiceFactory.createAndInitRaftNode(groupId, serverId, nodeOpts);
2.4.3.4、RPC 服务
单纯一个 raft node 是没有什么用,测试可以是单个节点,但是正常情况下一个 raft grup 至少应该是三个节点,如果考虑到异地多机房容灾,应该扩展到5个节点。
节点之间的通讯使用 bolt 框架(基于Netty)的 RPC 服务。
首先,创建节点后,需要将节点地址加入到 NodeManager:
NodeManager.getInstance().addAddress(serverId.getEndpoint());
NodeManager 的 address 集合表示本进程提供的 RPC 服务地址列表。
其次,创建 Raft 专用的 RPCServer,内部内置了一套处理内部节点之间交互协议的 processor:
RPCServer rpcServer = RaftRpcServerFactory.createRaftRpcServer(serverId.getEndPoint());
// 启动 RPC 服务
rpcServer.init(null);
上述创建和 start 两个步骤可以合并为一个调用:
RPCServer rpcServer = RaftRpcServerFactory.createAndStartRaftRpcServer(serverId.getEndPoint());
这样就为了本节点提供了 RPC Server 服务,其他节点可以连接本节点进行通讯,比如发起选举、心跳和复制等。
但是大部分应用的服务端也会同时提供 RPC 服务给用户使用,jraft 允许 raft 节点使用业务提供的 RPCServer 对象,也就是和业务共用同一个服务端口,这就需要为业务的 RPCServer 注册 raft 特有的通讯协议处理器:
RpcServer rpcServer = ... // 业务的 RPCServer 对象
...注册业务的处理器...
// 注册 Raft 内部协议处理器
RaftRpcServerFactory.addRaftRequestProcessors(rpcServer);
// 启动,共用了端口
rpcServer.init(null);
同样,应用服务器节点之间可能需要一些业务通讯,会使用到 bolt 的 RpcClient,你也可以直接使用 jraft 内部的 rpcClient:
RpcClient以上是关于JRaft框架学习笔记的主要内容,如果未能解决你的问题,请参考以下文章