小实验1比较ResNetViTSwinTransformer的归纳偏置(然而并没有达到预期结果)
Posted SinHao22
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小实验1比较ResNetViTSwinTransformer的归纳偏置(然而并没有达到预期结果)相关的知识,希望对你有一定的参考价值。
目录
写在前面:本实验并未获得预期的结果,更多的是当作实验记录。
1. idea
1.1 实验思路
这个实验的思路是这样的:通过随机初始化(正态分布)的未经过训练的ResNet、ViT和SwinTransformer,来对ImangeNet-1k(2012)的验证集(val,共50000张图片,1000类别)进行预测,对比预测结果和随机猜(准确率为1‰)的区别。
1.2 灵感来源
灵感来自Deep Clustering for Unsupervised Learning of Visual Features这篇论文,论文中提到这么一段话:

这段话说的是:“当模型(如CNN)中的参数
θ
\\theta
θ使用高斯分布随机初始化时,在未经训练时,预测出的结果很差。但是,要比随即猜测(对于ImageNet-1k来讲随机猜对的概率为千分之1)要好不少。”
作者给出的解释是,这是因为我们模型,如CNN,引入了先验知识(即CNN关于平移等变性、局部性等归纳偏置),所以随机初始化后,虽然没有经过数据训练,但得出的结果也要比随机猜要好。
所以我就在想,用未经训练的随机初始化的ResNet、ViT和SwinTransformer来预测ImageNet-1k(val),准确率越高,从某种程度上来讲说明引入的归纳偏置越强。
2. 实验设置
| 实验环境 | Pytorch1.12、2xRTX3090(24G) |
| 模型 | ResNet、ViT、SwinTransformer |
| 测试数据集 | ImageNet-1k(2012,val,50000张,1000类别) |
| 实验模型 | 参数量 |
|---|---|
| ResNet50 | 25.56M |
| ResNet101 | 44.55M |
| ViT_B_16 | 86.57M |
| ViT_L_16 | 304.33M |
| swin_t | 28.29M |
| swin_s | 49.61M |
其中初始化基本都是采用各种类型的正态分布进行初始化,比如
nn.init.trunc_normal_
nn.init.normal_
nn.init.kaiming_normal_
具体用法参考Pytorch官方文档
3. 实验结果
3.1 结果
实验结果是:未经训练的、随机初始化的ResNet、ViT和SwinTransformer,最后预测的结果都和随机猜的差不多(千分之一)。
| 模型 | 预测正确数量 | 测试集数量 | 准确率 | 训练时间 | batch_size | 显卡使用情况 |
|---|---|---|---|---|---|---|
| resnet50 | 50 | 50000 | 1‰ | 35.485s | 256 | 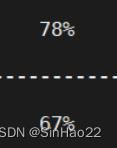 |
| resnet101 | 50 | 50000 | 1‰ | 45.556s | 256 | 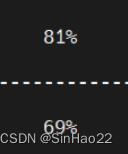 |
| vit_b_16 | 50 | 50000 | 1‰ | 83.587s | 256 | 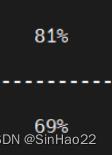 |
| vit_l_16 | 50 | 50000 | 1‰ | 370.091s | 64 | 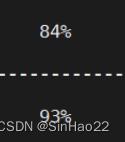 |
| swin_t | 43 | 50000 | ~1‰ | 44.616s | 256 |  |
| swin_s | 49 | 50000 | ~1‰ | 67.754s | 256 |  |
3.2 结果分析
3.2.1 一个奇怪的现象
有个比较有意思的现象,我们可以看到对于ResNet系列和ViT系列,都是预测对了50个样本。这是因为对于未经训练的随机初始化的ResNet和ViT,不论输入什么样本,预测出的标签是一样的。
注意:不是说输出都是一样的,而是说最后经过softmax输出的1000维特征,最大值对应的索引都相同。 所以才会有正好50个预测对的。(Imagnet-1K的val有50000张图片,1000个类别,每个类别都有50张图片)。
而对于SwinTransformer,最后预测的标签确实看上去是随机分布的,但也跟瞎猜的一样(都是1‰),并没有像Deep Cluster的作者说的那样:要比瞎猜的好上不少。
3.2.2 分析
我觉得Deep Cluster的作者说的应该是没错的(毕竟是大佬写的文章,还是顶会),问题应该出在我的代码实现的细节上,比如初始化的方式?我是使用TorchVision源码中自带的初始化,感觉也没什么问题啊。
这个现象我不打算再深入了,因为本身就只是想读一下Deep Cluster,看到作者说的这个现象觉得很有趣就像试一试,但没出现预期的效果。如果想深入找一下原因的话可以看看Deep Cluster的引用文献。
4. 代码
import os
import time
import torch
import torch.nn as nn
from torchvision.models import resnet50, resnet101, vit_b_16, vit_l_16, swin_t, swin_s
from torchvision import datasets, transforms
from tqdm import tqdm
def get_dataloader(data_dir=None, batch_size=64):
'''
:param data_dir: val dataset direction
:return: imageNet
'''
assert data_dir is not None
transform = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.2, 1.)),
transforms.ToTensor(),
# 这里我在考虑是否要进行标准化,可以做个对比实验
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
val_dataset = datasets.ImageFolder(
data_dir,
transform,
)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=batch_size,
num_workers=8,
shuffle=True,
)
return val_loader
def get_models():
'''
:return: res50, res101, ViT, SwinTransformer
'''
# load model with random initialization
res50 = resnet50()
res101 = resnet101()
vit_B_16 = vit_b_16()
vit_L_16 = vit_l_16()
swin_T = swin_t() # 参数量和res50相近
swin_B = swin_s() # 参数量和res101相近
model_list = [res50, res101, vit_B_16, vit_L_16, swin_T, swin_B]
model_names = ['res50', 'res101', 'vit_B_16', 'vit_L_16', 'swin_T', 'swin_B']
for name, model in zip(model_names, model_list):
print(f'name:10parametersize is compute_params(model): .2fM')
return model_list, model_names
def compute_params(model):
'''
:param model: nn.Module, model
:return: float, model parameter size
'''
total = sum(p.numel() for p in model.parameters())
size = total / 1e6
# print("Total params: %.2fM" % (total / 1e6))
return size
def model_evaluate(model, data_loader):
'''
:param model: test model
:param data_loader: val_loader
:return: list[float] acc list
'''
device = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')
device_ids = [1, 2] # use 2 GPUs
model = nn.DataParallel(model, device_ids=device_ids)
model.to(device)
model.eval()
total = 0
correct = 0
loop = tqdm((data_loader), total=len(data_loader))
for imgs, labels in loop:
imgs.to(device)
outputs = model(imgs)
outputs = outputs.argmax(dim=1)
labels = labels.to(device)
# print(outputs.shape, '\\n', outputs, outputs.argmax(dim=1))
# print(labels.shape, '\\n', labels)
total += len(labels)
res = outputs==labels
correct += res.sum().item()
loop.set_description(f'inference test:')
loop.set_postfix(total=total, correct=correct, acc=f'correct/total:.2f')
if __name__ == '__main__':
seed = 2022
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
data_dir = os.path.join('..', '..', '..', 'data', 'ImageNet2012', 'imagenet', 'val')
val_loader = get_dataloader(data_dir, batch_size=256)
get_models() # 输出模型的大小,本来想写一个循环自动训练所有的model,但测试会爆显存,所以就单独测试每个model了
net = swin_s() # 这里换成我们测试的模型,可以用resnet50, resnet101, vit_b_16, vit_l_16, swin_t, swin_s
t1 = time.time()
model_evaluate(net, val_loader)
print(f'total time: time.time() - t1:.3fs')
# nets, net_names = get_models()
# for net, name in zip(nets, net_names):
# if name == 'vit_L_16':
# val_loader = get_dataloader(data_dir, batch_size=16)
# val_loader = get_dataloader(data_dir, batch_size=128)
#
# t1 = time.time()
# model_evaluate(net, val_loader)
# print(f'name:.10 total time: time.time()-t1:.3fs')
参考:
1. Deep Clustering for Unsupervised Learning of Visual Features
以上是关于小实验1比较ResNetViTSwinTransformer的归纳偏置(然而并没有达到预期结果)的主要内容,如果未能解决你的问题,请参考以下文章