AirVO: An Illumination-Robust Point-Line Visual Odometry 论文笔记
Posted Kris_u
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AirVO: An Illumination-Robust Point-Line Visual Odometry 论文笔记相关的知识,希望对你有一定的参考价值。
论文 GitHub 开源 :GitHub开源
ABSTRACT
AirVO, 一个基于点、线特征具有光照鲁棒性行且精确的双目视觉里程计系统。为了实现对于光照变化的鲁棒性,我们引入了基于学习的特征提取和匹配方法,并设计了一个新颖的视觉里程计管道:包括特征跟踪、三角测量、关键帧选择和图形优化等。我们还采用了环境中的长线特征来提高系统的准确性。我们提出了一个光照鲁棒性的线追踪方法,其中点特征追踪、点分布和线特征被用来实现线的匹配。
This paper, we present AirVO, an illumination-robust and accurate stereo visual odometry system based on point and line features. To be robust to illumination variation, we introduce the learning-based feature extraction and matching method and design a novel VO pipeline,
including feature tracking, triangulation, key-frame selection,and graph optimization etc. We also employ long line featuresin the environment to improve the accuracy of the system.
INTRODUCTION
由于低成本和精确性,视觉里程计被广泛应用于各类应用中,尤其是增强现实和机器人技术领域。尽管已经有一些优秀的解决方案如MSCKF、VINS-Mono、OKVIS等,但是现有的方案对时间较长的应用鲁棒性的要求无法满足,例如,在光照一直变化的环境中,视觉追踪变得更加具有艰难,而且轨迹估计的质量也受到严重的影响。
另一方面,卷积神经网络在许多机器视觉任务中已经取得了重大贡献,已经促成了另一个研究趋势。虽然许多基于学习的特征提取和匹配方法已经被提出来,并在许多应用方面获得了优越的性能。然而,其往往需要巨大的计算资源,也使得其在拥有低算力的机器人如无人机上实时性无法实现。因此,我们诉诸使用一个既拥有传统优化的高效性又拥有基于学习方法的鲁棒性的混合方案。
文章中,我们提出了AirVO,一个具有光照鲁棒性和精确性的双目视觉里程计,基于学习的特征提取和匹配算法。相较于视觉里程计和SLAM中的手工特征如FAST和ORB,基于学习的特征在光照变化剧烈的情况下鲁棒性更好。在特征追踪阶段,基于学习的方法不但可以使用特征的外观信息还有几何信息,所以它的性能跟好,相比于传统的数据关联方法如光流追踪法和最小化特征算子距离 。为了更好的将学习方法应用到我们的系统,我们改进了框架中的追踪、特征三角测量和关键帧选择。为了提高准确性,我们使用线特征并提出了一个新颖的线处理管道来实现线追踪在光照不稳定环境中的鲁棒性。最后,使用传统的SLAM后端实现局部地图的优化。
METHODOLOGY

A. System Overview
It's a hybrid VO system where we utilize both learning-based fronted and traditional backend. For every stereo image pair, we first employ a CNN(e.g.,SuperPoint) to extract feature points and match them with a feature matching network (e.g,SuperGlue). Line features are also utilized in our system to improve the accuracy.
框架如图所示: Fig:2是一个混合视觉里程计系统。既使用了基于学习的前端还有传统的后端优化。对于每组双目图像,我们先使用一个CNN(例如:SuperPoint)来提取特征点,并且使用一个特征匹配网络(例如:SuperGlue)取匹配特征点。我们使用预训练模型跳过了关键点检测和匹配网络的细节,线特征用来提升我们系统的准确性。观察到我们系统中提取到的许多关键点位于边缘部分,也是提取到线特征提取地方,根据他们之间的距离可以将两种特征联系在一起。那么便可以匹配双目图像中的线条或者是不同的帧,或使用关联点的匹配结果进行追踪以实现更好的视觉鲁棒性。为了提高系统的准确性,我们只使用了左眼图像的不同帧进行特追踪,基于特征追踪结果,我们选择关键帧,bingqie并优化点、线且对关键帧进行全局调整。
B. 2D Line Processing
2D Line Processing 包括线段的检测和匹配。
1、Detection: 线段的检测使用AirVO ,此方法基于传统的LSD方法,但是LSD 方法在将直线分割为多个部分方面存在问题,我们改进了此问题,如果两个线段L1和L2 满足以下条件,将两线段归纳认为一条。
- 线段L1和L2的角度差小于给定阈值

- 一个线段的中点到另一个线段中点的距离不大于
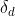
- 如果L1和L2在X轴和Y轴的投影不重叠,线段端点的距离小于给定值
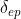
选取更具有代表性的长线段,小于预设长度的线段会被过滤掉。
Matching:在光线条件较好的情况下,目前大多数的视觉里程计以及SLAM系统使用LBD描述符。或使用样点追踪再或者是追踪线条,这些方法都有比较好的性能。但在光照变化较大的情况下就会出现问题。我们设计了一种新颖的线段匹配通道在光照变化较大的环境。首先,通过点线之间的距离将点特征跟线段联系起来。假设一张图中检测有M个关键点和N条线段。
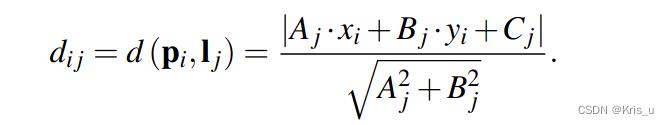
C. 3D Line Processing
3D 线拥有更多的自由度,首先,介绍其在不同阶段的表示方法,比如三角化方法:将二维转化成3D 直线;直线的投影:将3D直线投影到图像平面。
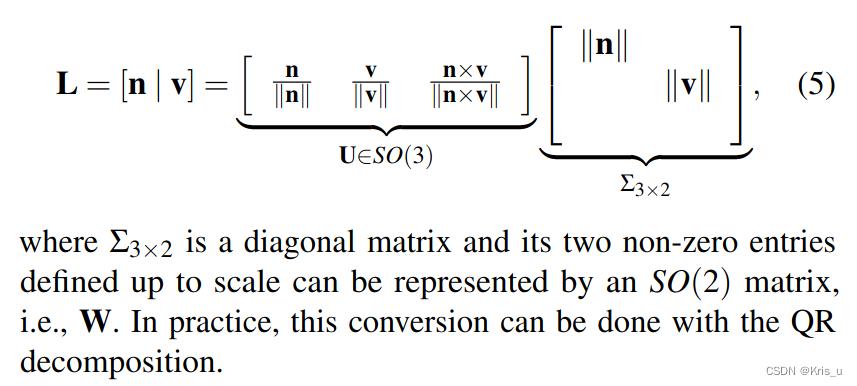
- Representation: 使用普鲁克坐标系表示3D空间的直线

Orthonormal representation can be obtained from Plücker coordinate by:
2.Triangulation: Triangulation is to initialize a 3D line from two or more 2D line observations.
系统中使用了两种3D直线的三角化方法,分别如下:
- 3D linecan be computed from two planes. To achieve this, we select two line segments, l1 and l2, on two images, which are two observations of a 3D line. l1 and l2 can be back-projected to two planes, π1 and π2. Then the 3D line can be regarded as the intersection of π1 and π2.
- employ a second line triangulation method if the above method fails, where
points are utilized to compute the 3D line. In Section III-B.2, we have associated point features with line features.So to initialize a 3D line, two triangulated points X1 and X2, which belong to this line and have the shortest distance on image plane, are selected, where X1 = (x1, y1, z1) and X2 = (x2, y2, z2). Then the Plücker coordinate of this line canbe obtained through:
 Because the selected 3D points have been triangulated in the point triangulating stage, so this method requires little extra computation. It is very efficient and robust.
Because the selected 3D points have been triangulated in the point triangulating stage, so this method requires little extra computation. It is very efficient and robust.
3、Re-projection:使用普鲁克坐标系做3D直线的变换和重投影,首先,将3D直线从世界框架转换到相机框架

D. Key-Frame Selection
Observing that the learning-based data association method is able to track two frames which have large baseline, so different from frame-by-frame tracking strategy used in other VO or SLAM systems, we only match current frame with key-frames, as this can reduce the tracking error. A frame will be selected as a key-frame if any of the following conditions is satisfied:

EXPERIMENTS
In this section, experimental results will be presented to demonstrate the performance of our method. We takes pre-trained SuperPoint and SuperGlue to detect and match feature points without any fine-tuning. The experiments are conducted on two datasets: OIVIO dataset [51] and UMA visual-inertial dataset [6]. We compare the localization accuracy of the proposed method with PL-SLAM [26], VINS-Fusion [3], StructVIO [34], UV-SLAM [30], and Stereo ORB-SLAM2[19].
As the proposed method is a VO system, we disabled the loop closure part from above baselines. Note that we cannot compare with DX-SLAM [15] and GCNv2-SLAM[22], since they are based on RGB-D inputs.
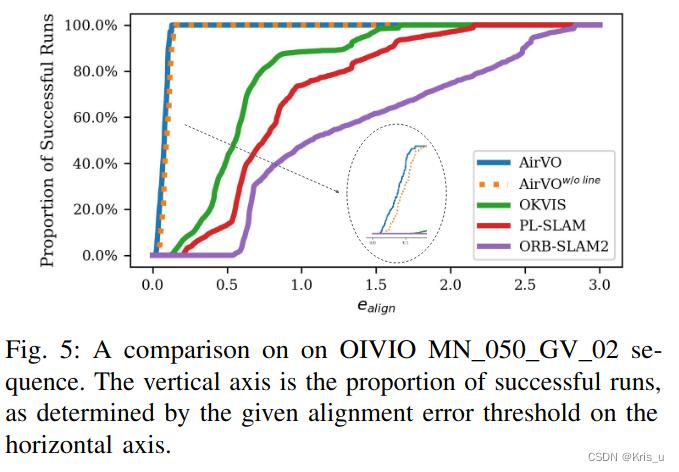
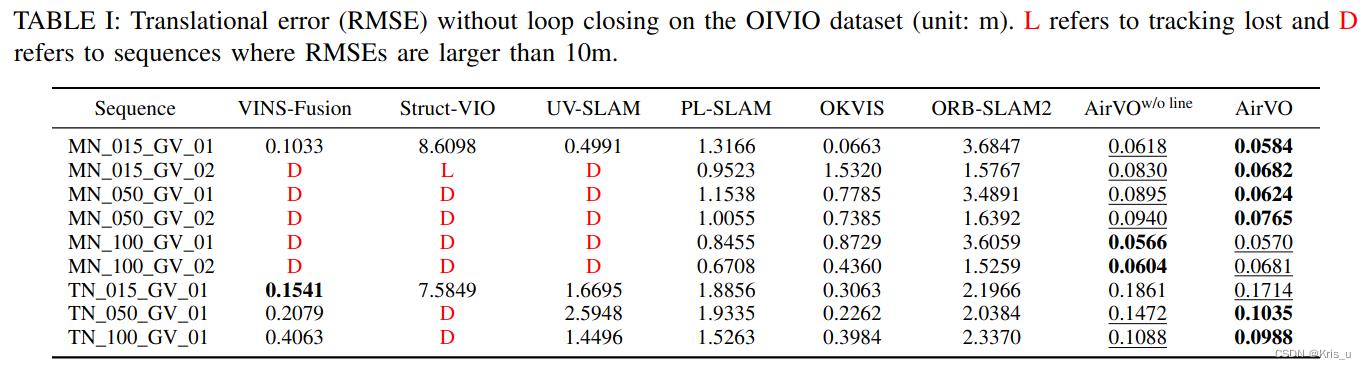
A. Results on OIVIO Benchmark
B. Results on UMA-VI Benchmark
Conclusions
In this work, we presented an illumination-robust visual odometry based on learning based key-point detection and matching methods. To improve the accuracy, line features are also utilized in our system. In the experiments, we showed that the proposed method achieved superior performance in dynamic illumination environments and could run in real time. We open the source code and expect this method will play an important role in robotic applications. For future work, we will extend AirVO to a SLAM system by adding loop closing, re-localization and map-reuse. We hope to build an illumination-robust visual map for long-term localization.
提出的基于学习的点特征提取和匹配算法取得了不错的表现在动态光照环境中,并应用线特征来提高系统的准确性。此方法已开源,未来将增加回环检测功能、重定位和地图复用等扩展AireVO。
以上是关于AirVO: An Illumination-Robust Point-Line Visual Odometry 论文笔记的主要内容,如果未能解决你的问题,请参考以下文章