docker部署canal 1.1.6 rocketmq 分区顺序性
Posted 伍Wu哈Ha
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了docker部署canal 1.1.6 rocketmq 分区顺序性相关的知识,希望对你有一定的参考价值。
docker部署canal 1.1.6
docker pull canal/canal-server:v1.1.6
mkdir -p /mydata/canal/
mkdir -p /mydata/canal/logs/
chmod 755 -R /mydata/canal/
docker run --name canal -d canal/canal-server:v1.1.6
#拷贝配置文件
docker cp canal:/home/admin/canal-server/conf/canal.properties /mydata/canal/
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /mydata/canal/
docker run -p 11111:11111 \\
--name canal \\
-v /mydata/canal/instance.properties:/home/admin/canal-server/conf/example/instance.properties \\
-v /mydata/canal/canal.properties:/home/admin/canal-server/conf/canal.properties \\
-v /mydata/canal/logs:/home/admin/canal-server/logs \\
-d canal/canal-server:v1.1.6
rocketmq 分区顺序性问题
https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
# mq config
canal.mq.topic=canal
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\\\..*,.*\\\\..*
canal.mq.partition=0
# hash partition config
#动态获取MQ服务端的分区数,如果设置为true之后会自动根据topic获取分区数替换canal.mq.partitionsNum的定义,目前主要适用于RocketMQ
canal.mq.enableDynamicQueuePartition=true
#散列模式的分区数
canal.mq.partitionsNum=2
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#指定所有正则匹配的表对应的hash字段为表主键(自动查找)
canal.mq.partitionHash=.*\\\\..*:$pk$
@Component
@RocketMQMessageListener(
topic = "canal",
consumerGroup = "test_group"
)
public class CanalConsumer implements RocketMQListener<String>
@Override
public void onMessage(String message)
//处理
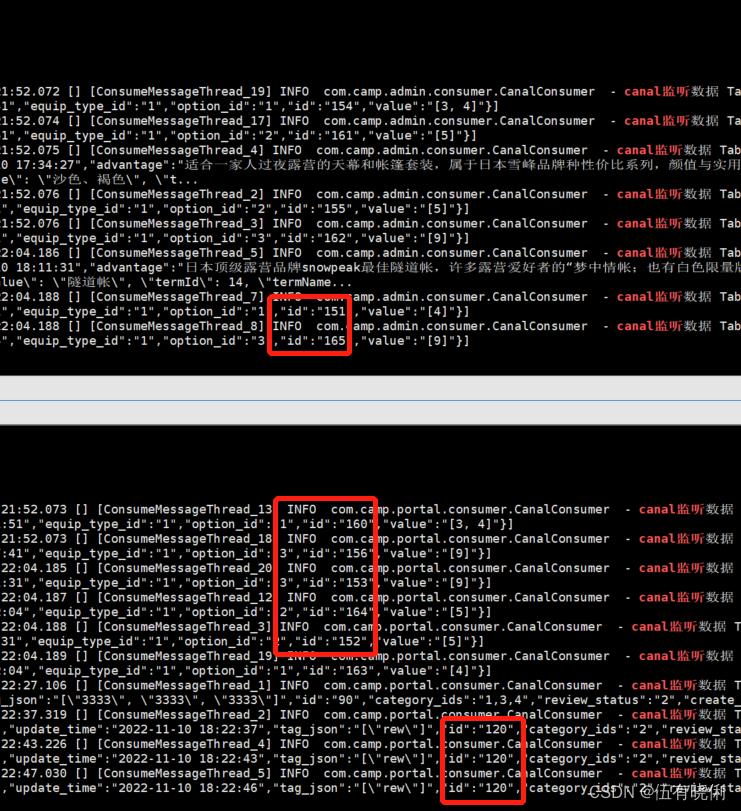
消费者两台的情况下会根据主键id分区,确保每个分区消费顺序性
canal.mq.partitionHash 表达式说明
canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
- 例子1:test\\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
- 例子2:.\\…:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
- 例子3:.\\…: p k pk pk 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
- 例子4: 匹配规则啥都不写,则默认发到0这个partition上
- 例子5:.\\… ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名
- 按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
- 例子6: test\\.test:id,.\\…* , 针对test的表按照id散列,其余的表按照table散列
注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
其他详细参数可参考Canal AdminGuide https://github.com/alibaba/canal/wiki/AdminGuide
mq顺序性问题
binlog本身是有序的,写入到mq之后如何保障顺序是很多人会比较关注,在issue里也有非常多人咨询了类似的问题,这里做一个统一的解答
-
canal目前选择支持的kafka/rocketmq,本质上都是基于本地文件的方式来支持了分区级的顺序消息的能力,也就是binlog写入mq是可以有一些顺序性保障,这个取决于用户的一些参数选择
-
canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分区
- canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name
- canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等
-
canal的消费顺序性,主要取决于描述2中的路由选择,举例说明:
- 单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
- 多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
- 单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),如果用户选择的是指定pk hash的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk hash的方式需要业务权衡,这里性能会最好,但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况. 如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题,需要注意
以上是关于docker部署canal 1.1.6 rocketmq 分区顺序性的主要内容,如果未能解决你的问题,请参考以下文章