模型推理加速系列06: 基于resnet18加速方案评测
Posted JasonLiu1919
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型推理加速系列06: 基于resnet18加速方案评测相关的知识,希望对你有一定的参考价值。
简介
花雪随风不厌看,更多还肯失林峦。愁人正在书窗下,一片飞来一片寒。小伙伴们好,我是微信公众号小窗幽记机器学习的首席称重师:卖麻辣烫的小男孩。今天这篇文章以resnet18模型为例,对比Pytorch、ONNX、TorchScript、TensorRT模型格式在不同硬件(包括CPU和GPU)上的inference性能。由于此前TorchScript模型在 AMD CPU上的评测结果是负向效果(远慢于Pytorch),具体可以参考此前的推文模型推理加速系列|04:BERT模型推理加速 TorchScript vs. ONNX的推理速度评测部分,因此本次实验涉及CPU评测部分改用Intel CPU。
本文也同步发布于微信公众号:模型推理加速系列 | 06: 基于resnet18加速方案评测。
更多、更新文章欢迎关注微信公众号:小窗幽记机器学习。后续会持续输出模型推理加速和工程部署相关系列,敬请期待~
老惯例,下图是算法生成的图片,仅供欣赏~

本次实验所用硬件信息如下:
CPU:
10 Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
GPU:
Nvidia T4 和 Nvidia 3090 都是单卡
模型导出
导出TorchScript
关于如何导出TorchScript模型格式及其TorchScript模型格式的进一步介绍可以参考此前的文章:模型推理加速系列|04:BERT模型推理加速 TorchScript vs. ONNX
和 模型推理加速系列|05:TorchScript模型格式简介及其使用。本文将 resnet18 导出TorchScript格式及其Python版inference的评测代码如下:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : check_jit.py
@Time : 2022/11/25 20:31:12
@Author : 卖麻辣烫的小男孩
@Desc :
'''
import os
os.environ['TORCH_HOME']='/data/model_zoo/cv'
"""
默认情况下环境变量TORCH_HOME的值为~/.cache
"""
import torch
import torchvision
import pdb
import time
from tqdm import tqdm
import numpy as np
def convert_resnet18_torchscript():
"""
将 resnet18 转为 TorchScript 模型格式
"""
# An instance of your model.
model = torchvision.models.resnet18(pretrained=True)
# Switch the model to eval model
model.eval()
# An example input you would normally provide to your model's forward() method.
example = torch.rand(1, 3, 224, 224)
# Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing.
trace_model = torch.jit.trace(model, example) # torch.jit.ScriptModule
raw_output = model(example)
trace_model_output = trace_model(example)
np.testing.assert_allclose(raw_output.detach().numpy(), trace_model_output.detach().numpy())
# Save the TorchScript model
trace_model.save("/data/model_zoo/cv/resnet18_traced_model.pt")
# Use torch.jit.trace to generate a torch.jit.ScriptModule via script.
script_model = torch.jit.script(model)
script_model_output = script_model(example)
np.testing.assert_allclose(raw_output.detach().numpy(), script_model_output.detach().numpy())
# Save the TorchScript model
script_model.save("/data/model_zoo/cv/resnet18_script_model.pt")
导出 ONNX
关于如何导出ONNX模型格式可以参考之前的文章:模型推理加速系列|04:BERT模型推理加速 TorchScript vs. ONNX。
导出ONNX模型
本次实验将resnet18导出为ONNX模型格式的代码如下:
import torch
MODEL_ONNX_PATH = "/data/model_zoo/cv/resnet18.onnx"
OPERATOR_EXPORT_TYPE = torch._C._onnx.OperatorExportTypes.ONNX
model = torchvision.models.resnet18(pretrained=True)
model.eval()
org_dummy_input = torch.rand(1, 3, 224, 224)
torch.onnx.export(model,
org_dummy_input,
MODEL_ONNX_PATH,
verbose=True,
operator_export_type=OPERATOR_EXPORT_TYPE,
opset_version=12,
input_names=['inputs'],
output_names=['outputs'],
do_constant_folding=True,
dynamic_axes="inputs": 0: "batch_size", "outputs": 0: "batch_size"
)
ONNX模型可视化
利用 netron 对导出的ONNX模型进行可视化:
netron /data/model_zoo/cv/resnet18.onnx -p 8001 --host "0.0.0.0"
可视化结果如下:
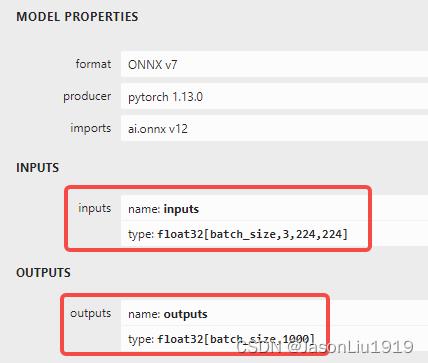
导出TensorRT
使用如下命令将 ONNX 格式模型转为 TensorRT 模型格式:
CUDA_VISIBLE_DEVICES=0 trtexec --onnx=model_repo/resnet18.onnx --minShapes=inputs:1x3x224x224 --optShapes=inputs:64x3x224x224 --maxShapes=input_ids:256x3x224x224 --saveEngine=model_repo/model.plan --workspace=20480
更多关于如何导出TensorRT模型格式的细节,敬请期待后续系列。
C++上做模型inference
由于导出的 TorchScript 模型能够在C++上运行,本文进一步在C++上进行评测。
编译和运行
官方发布的LibTorch所有版本都是已经编译好的,解压后就可以使用。在Linux上提供了两种类型的libtorch二进制文件:一种是用GCC pre-cx11 ABI编译的,另一种是用GCC-cx11 ABI编译的,应该根据系统使用的GCC ABI进行选择。
CMakeList.txt 内容如下:
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(example-app)
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "$CMAKE_CXX_FLAGS $TORCH_CXX_FLAGS")
add_executable(example-app example-app.cpp)
target_link_libraries(example-app "$TORCH_LIBRARIES")
set_property(TARGET example-app PROPERTY CXX_STANDARD 14)
cmake 编译:
cmake -DCMAKE_PREFIX_PATH=/opt/conda/lib/python3.8/site-packages/torch/share/cmake/ ..
cmake --build . --config Release
运行程序:
./example-app /home/model_zoo/cv/resnet18_traced_model.pt gpu 1
功能测试
以torch::ones(1, 3, 224, 224作为输入,测试结果如下。
Python版在 GPU 上 inference的输出结果:
(Pdb) outputs[0,:5]
tensor([-0.0375, 0.1146, -1.7963, -1.2334, -0.8193], device='cuda:0',
grad_fn=<SliceBackward0>)
C++版在 CPU 上inference的输出结果:
-0.0391 0.1145 -1.7968 -1.2343 -0.8190
[ CPUFloatType1,5 ]
C++版 在 GPU 上inference的输出结果:
-0.0375 0.1146 -1.7963 -1.2334 -0.8193
[ CUDAFloatType1,5 ]
评测结果
以下综合评测了resnet18在原生Pytorch模型格式、ONNX、TorchScript(Python版和C++版)和TensorRT模型格式的inference性能。具体评测结果如下表所示(单位ms):
CPU 版
| batch-size | Pytorch | ONNX | JIT-trace | JIT-trace(C++) |
|---|---|---|---|---|
| 1 | 16.7 | 7 | 14.4 | 14.3 |
| 8 | 76.2 | 50.2 | 71.3 | 70.0 |
| 16 | 146.8 | 99.9 | 139.6 | 140.6 |
| 32 | 277.6 | 194.3 | 274 | 269.9 |
NVIDIA T4 GPU 评测结果:
| batch-size | Pytorch | ONNX | JIT-trace | JIT-trace(C++) | TensorRT |
|---|---|---|---|---|---|
| 1 | 4.2 | 4.1 | 4.2 | 4.2 | 3.9 |
| 2 | 5.5 | 5.8 | 5.5 | 5.5 | 5.2 |
| 4 | 9.5 | 8.3 | 9.5 | 9.5 | 8.4 |
| 8 | 17.6 | 16.8 | 17.6 | 17.6 | 15.3 |
| 16 | 28.5 | 26.2 | 28.6 | 28.6 | 25.2 |
| 32 | 52 | 51.1 | 52.1 | 52 | 50.7 |
| 64 | 100.3 | 96.2 | 100.3 | 100.2 | 92.6 |
| 128 | 显存不足 | 198.6 | 显存不足 | 200 | 174.8 |
NVIDIA 3090 GPU 评测结果:
| batch-size | Pytorch | ONNX | JIT-trace | JIT-trace(C++) | TensorRT |
|---|---|---|---|---|---|
| 1 | 2.6 | 1.4 | 1.9 | 1.9 | 0.9 |
| 2 | 2.7 | 1.5 | 1.9 | 2 | 1.1 |
| 4 | 2.7 | 1.9 | 1.9 | 2 | 1.5 |
| 8 | 2.7 | 2.7 | 2.3 | 2.3 | 2.4 |
| 16 | 4.3 | 4.4 | 4.2 | 4.15 | 4.2 |
| 32 | 7.6 | 7.8 | 7.5 | 7.5 | 7.3 |
| 64 | 14.1 | 13.8 | 13.9 | 14 | 12.7 |
| 128 | 26.5 | 27.7 | 26.3 | 26.6 | 24 |
小结
本文基于resnet18模型在CPU和GPU上评测原生Pytorch模型格式、ONNX、TorchScript(Python版和C++版)和TensorRT模型格式的inference性能。根据上述评测结果可以得出以下初步结论:
-
Intel CPU 上,ONNX的推理速度最快。
-
图片场景下(尺寸固定,只是batch size可变)如果使用GPU,TensorRT推理速度最快
-
小 batch size加速明显,随着batch size的增加,耗时近乎上线性增加,即提速收益不再增加
-
随着batch size的增加,各个方案的inference性能接近,没有显著差异。
-
相同模型格式以不同编程语言在GPU上做推理,纯GPU inference部分耗时一样。不同语言在GPU上inference的差异仅仅在于把数据放在GPU上的API不同,最终是同一硬件GPU对同一模型进行inference,所需要的算力是一样的。
-
C++中显存利用率更高
以上是关于模型推理加速系列06: 基于resnet18加速方案评测的主要内容,如果未能解决你的问题,请参考以下文章