源码阅读(40):Java中线程安全的QueueDeque结构——LinkedTransferQueue
Posted 说好不能打脸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了源码阅读(40):Java中线程安全的QueueDeque结构——LinkedTransferQueue相关的知识,希望对你有一定的参考价值。
(接上文《源码阅读(39):Java中线程安全的Queue、Deque结构——LinkedTransferQueue(2)》)
2.4.1、生产者端对xfer方法的调用
请注意我们讨论的情况是同时有多个生产者线程,在进行LinkedTransferQueue队列的数据添加操作。最初,单向链表中只有一个虚拟节点,LinkedTransferQueue队列的head属性、tail属性都引用它,如下图所示

接着,由于是生产者线程调用xfer方法,所以xfer方法的4个方法的特性是:e是该生产者线程添加的数据对象(不为null);haveData参数的属性为true;至于how参数和nanos参数,会有多种值的情况,但是并不影响我们进行讨论。接着运行内层for循环时,由于判定条件:
(t != (t = tail) && t.isData == haveData)
的判定结果为true,所以p变量的引用将以当前tail属性的引用值为准。如下图所示:

按照上文所述,只有当前处理节点p的isData标识和入参的haveData标识一致,且当前处理节点p真实的数据对象存在情况和入参的haveData标识一致,既如下判定式的结果为true,才是出队操作:
p.isData != haveData && haveData == ((item = p.item) == null)
// ......
很明显,当多个生产者线程在进行xfer操作时,无论单向链表已形成了多少Node节点(Node节点都是存储任务),在当前操作的入参haveData值为true时,以上判定式的结果都为false,所以当前xfer操作不会进入出队处理逻辑。
由于p变量(代表当前正在处理的,处于单向链表中的node节点)从tail属性引用的位置开始,所以在经过以下语句逻辑后,p节点就会指向当前单向链表中的最后一个Node节点位置(注意这个“最后一个Node节点”的位置可能并不是tail属性指向的位置,且这个“最后一个Node节点”的位置可能在本线程操作过程中发生变化——因为还有其它生产者线程在同时操作)
// ......
// 通过以下的语句模式,p变量所代表的节点终会是某一个瞬时下
// 当前单向链表的最后一个Node节点
restart: for (Node s = null, t = null, h = null;;)
for (Node p = (t != (t = tail) && t.isData == haveData) ? t : (h = head);; )
// ......
if ((q = p.next) == null)
// ......
if (p == (p = q))
continue restart;
// ......
// ......
一旦“(q = p.next) == null”的判定是成立,本次xfer操作就开始进行入队处理逻辑。通过“s = new Node(e);”创建新的Node节点;通过“p.casNext(null, s)”原子操作,试图将创建的新节点s,成功引用到链单向链表的末尾;通过“casTail(t, s)”试图重新为tail属性指定新的引用位置——是否成功都无所谓。如下图是一种可能成功的操作状态:

2.4.2、消费者端对xfer方法的调用
我们设在多个消费者线程操作前,LinkedTransferQueue中的单向链表呈现如下的状态:

如上图所示,head引用指向的Node节点是一个“虚”节点,该节点是在LinkedTransferQueue初始化时创建的,其isData属性的值和item属性拥有值的真实情况是相悖的——这种特点的节点,将在skipDeadNodesNearHead方法中被清理掉。
那么当(多个)消费者线程调用xfer方法时,入参e为null,haveData为false。起初进入xfer方法时,通过后者外层for循环的初始表达时判定后,局部变量p将被赋值为head的引用位置,代码段如下所示:
// 由于tail引用的对象,其isData属性值与入参haveData不一致
// 所以p变量将被赋值为head的对象引用
for (Node p = (t != (t = tail) && t.isData == haveData) ? t : (h = head);; )
// ......
用图形化的表达方式,展示如下:
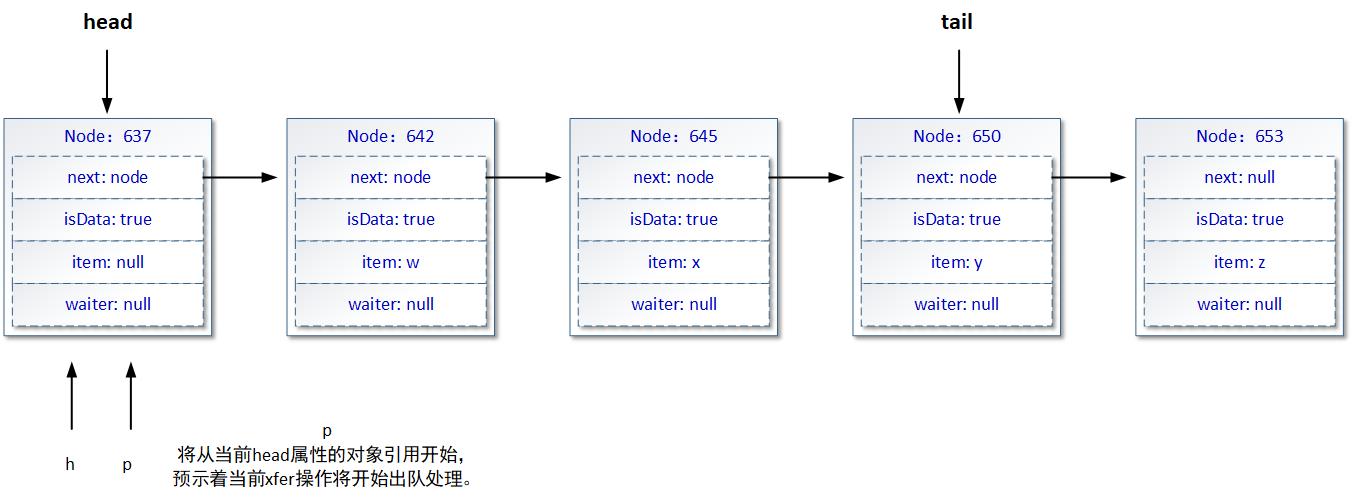
接着,由于head引用的节点是一个“虚”节点,所以p变量的引用位置将基于“q = p.next” 和 “p = q”语句的配合,向链表的后续结“移动”,随后p变量的引用将指向对象编号为642的Node对象。由于这个Node符合出队操作的判定式,所以开始执行出队逻辑:
// ......
// 对象id编号为642的Node结点,其isData属性值和入参haveData的值相悖
// 并且其item属性真实存在数据的情况也和入参haveData的值相悖(注意,不要看到“==”就认为是相同,请仔细分析判定场景)
if (p.isData != haveData && haveData == ((item = p.item) == null))
// 出队逻辑在这里
// ......
// ......
这里需要注意,由于是多个出队操作同时进行,所以当前p变量所引用的对象节点的数据可能已经被某个操作线程取出(甚至该节点已经被skipDeadNodesNearHead方法以无效节点的身份清理,变成了自引用状态),那么以上表达式可能不成立,需要按照cas的思路重新确认p变量的引用位置,然后再重新开始处理逻辑。请注意出队逻辑中的如下语句:
// ......
// 由于我们示例的操作场景,单向链表由生产者模式下的Node节点构成
// 所以消费者任务进行出队操作时,以下方法调用成功,将使得p节点item属性值变为null。
if (p.tryMatch(item, e))
// ......
// ......
我们来看一下tryMatch方法的内部逻辑:
/** Tries to CAS-match this node; if successful, wakes waiter. */
final boolean tryMatch(Object cmp, Object val)
// 使用原子操作设定当前Node对象的item属性为null
// 如果设置成功,则通知Node对象中记录的可能的waiter线程(等待匹配操作的线程)
// 解除阻塞状态。LockSupport工具类之前的文章已经花较大篇幅介绍了,这里不再赘述
if (casItem(cmp, val))
LockSupport.unpark(waiter);
return true;
return false;
一个中心思想是,当p变量引用的Node节点对象成功调用tryMatch方法后,这个节点对象的isData属性值和item属性中实际的数据对象引用情况,就变得相悖——也就是说这个Node节点对象变成了一个“虚”节点。如下图所示(编号642的Node节点对象变成了虚节点):
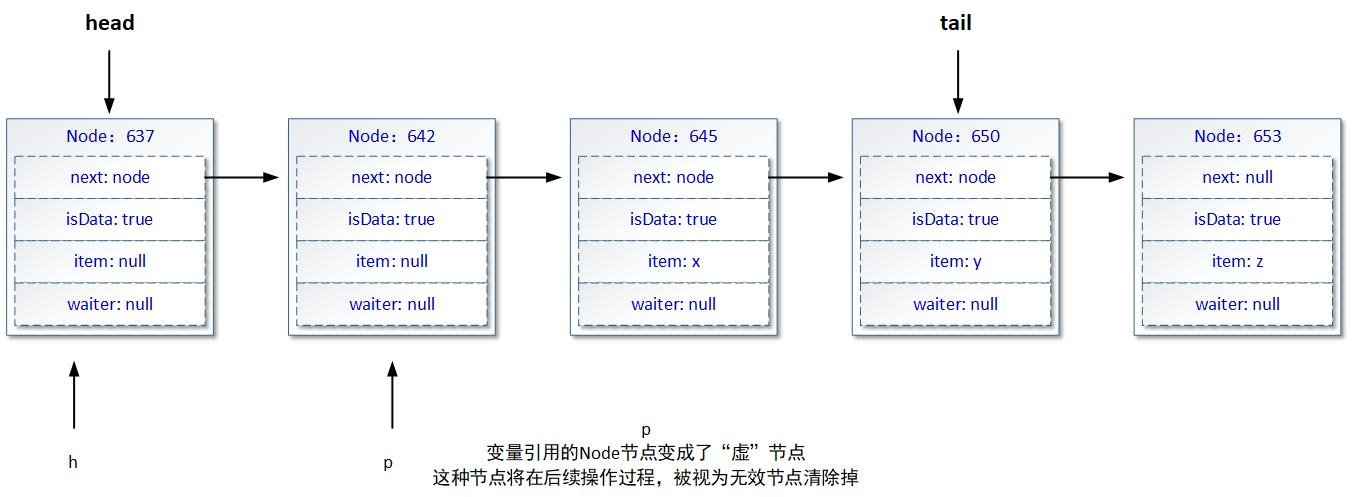
接下来,由于p != h的判定式成立,所以出队逻辑会调用skipDeadNodesNearHead方法将h变量指向的节点(包含)和p变量指向的节点(包含)间的所有节点,作为无效节点清除掉,并且重新设置LinkedTransferQueue队列head属性的引用位置。我们来看看skipDeadNodesNearHead方法内部是如何工作的:
// 该方法负责清理单向链表中的无效节点,既是isData属性值和item属性值相悖的那些节点
// h变量表示清理的开始(节点)位置
// p变量表示清理的结束(节点)位置,p所引用的Node节点一定是一个无效节点
private void skipDeadNodesNearHead(Node h, Node p)
// 循环的目的并不是cas原理,而是为了找到单向链表中离链表头部最近的有效节点
for (;;)
final Node q;
// 如果清理过程发现已经达到当前链表的最后一个节点,则p节点不能再“向后移动”了
// 注意每次循环都会有一个变量q,指向当前p变量所指向Node节点对象的下一个Node节点对象
if ((q = p.next) == null)
break;
// 如果q变量指向的Node节点是有效的,就说明已找到了单向链表中离链表头部最近的有效节点了
// 将q变量的值赋给p,以便达到“向后移动”的目的,并且不需要再继续向后找了,推出循环
else if (!q.isMatched())
p = q;
break;
// 如果以上条件不成立,则还是要将q变量的值赋给p,而且通过循环,继续向链表的后续结点寻找。
// 注意:如果p节点出现了自循环的情况,这种情况代表p已经被其它线程的调用过程清理出了队列,那么直接退出处理即可
else if (p == (p = q))
return;
// 当方法的以上操作成功找到自己认为的最接近链表头部的有效节点
// 则通过原则操作,重新设置单向链表的head属性的对象引用位置,并将原来h变量引用的Node节点设置为自循环
// 表示这个节点已经被移出队列
if (casHead(h, p))
h.selfLink();
// 该方法用于确认当前Node节点对象的isData属性值和item属性值是否相悖(是否有效)
// 所谓相悖,是指如下两种情况中的一种:
// a、当isData属性值为true时,item属性却为null
// b、当isData属性值为false时,item属性却不为null
// 如果两个属性的值相悖,则返回true
final boolean isMatched()
return isData == (item == null);
通过skipDeadNodesNearHead方法的调用,如果其中的cas操作成功,那么单向链表呈现的状态可用下图进行表示:
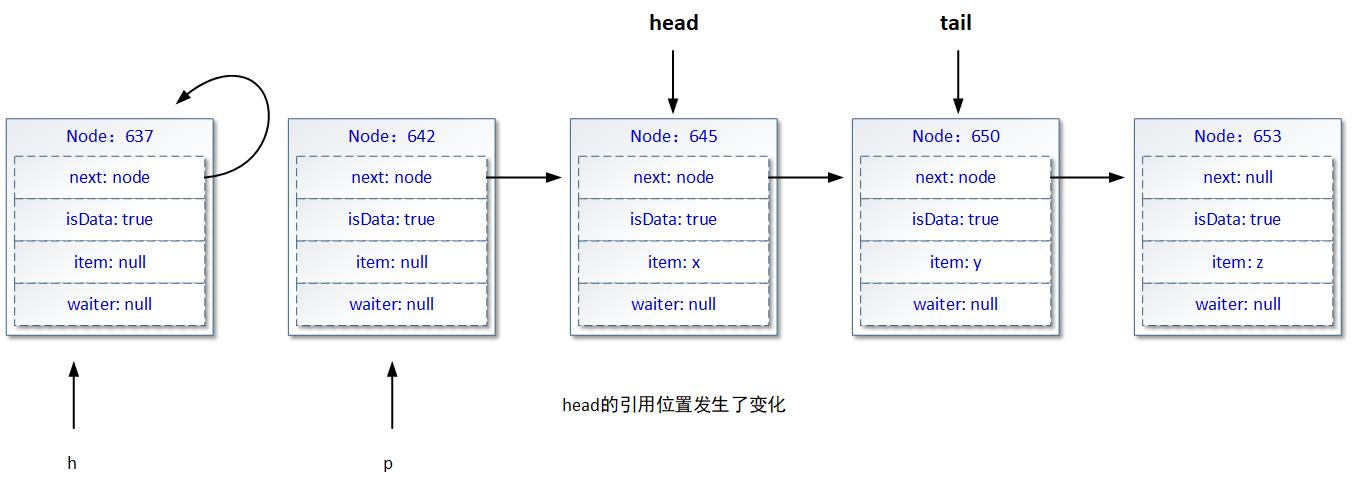
2.4.3、xfer方法工作过程总结
上文中我们逐句阅读了xfer中的源代码,并通过一个典型的多生产者、多消费者的使用场景讨论了LinkedTransferQueue队列的工作过程。要说明的是,无论是上文中提到的生产者先工作然后消费者再工作;还是反向的场景:消费者先工作然后生成者再工作;又或者生产者和消费者一同工作,LinkedTransferQueue中单向链表的基本工作原理都相同。
如此,我们基本可以总结出LinkedTransferQueue内部单向链表工作的几个特点:
-
单向链表中并不是所有节点都有效(有“虚”节点存在),但除了“虚”节点以外,整个单向链表所有有效节点只可能是同一种任务模式——要么全是取数任务,要么全是存储任务。
-
tail引用的位置不一定在单向链表的最末尾,这可能是因为多线程下的并发操作导致的,还可能是在同一线程中两次连续操作导致的。
-
head引用的位置也不一定在单向链表的头部,这也是因为多线程下的并发操作导致的。而且单向链表可以保证在head引用位置之前还没有脱离单向链表的所有Node节点都是“虚”节点(无效节点)。
-
而且基于以上两个描述,我们还可以得出一个结论,就是head可能在某种情况下,会指向tail引用之后的Node节点(也就是head引用的位置在tail引用位置之后),如下图所示:
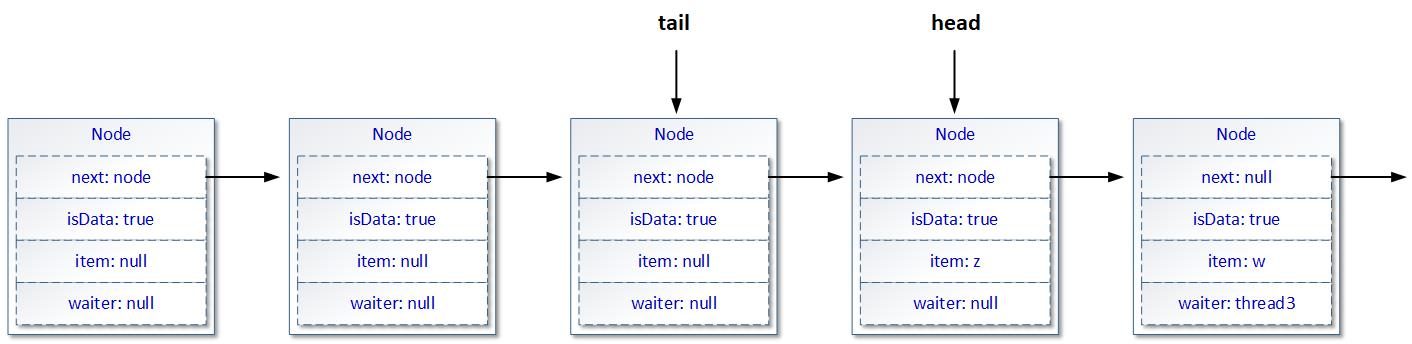
这种情况是正常的,最直白的解释就是:在多线程的操作场景下,出队操作追赶上了入队操作——或者说入队操作还没有来得急修正tail的引用位置,刚入队的Node节点就被出队了。 -
当xfer方法中通过skipDeadNodesNearHead方法清理无效Node节点时,并不是直接将无效节点置为null,而是将无效节点的next属性引用向它自己,这样做主要有两个原因:
-
原因1:让无效Node节点失去引用路径可达性,以便帮助垃圾回收器进行回收
-
原因2:但是以上原因并不是最主要的原因,毕竟即使不将无效节点对象的next属性引用指向它自己,无效Node节点也会因为head引用位置后移而失去路径可达性。这样做的最主要原因是在多线程场景下,方便告知处理进度“落后于”自己的出队处理线程,它们正在处理的Node节点已经被当前线程完成了出队处理,已经变成了无效状态,需要他们重新开始自己的出队逻辑。这就是xfer方法中“p == (p = q) continue restart;” 语句的意义。
-
============(接下文)
以上是关于源码阅读(40):Java中线程安全的QueueDeque结构——LinkedTransferQueue的主要内容,如果未能解决你的问题,请参考以下文章