从边际投影中重构类别型联合分布的可视分析方法(A Visual Analytics Approach for Categorical Joint Distribution Reconstruction
Posted 松子茶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从边际投影中重构类别型联合分布的可视分析方法(A Visual Analytics Approach for Categorical Joint Distribution Reconstruction相关的知识,希望对你有一定的参考价值。
来源: PKU Visualization Blog 作者: Chufan Lai
所谓边际投影,指的是多维数据在少数几个维度上的数量累积,例如两份病患统计数据,分别展示病人在年龄和性别上的一维分布。然而仅凭这些数据,我们无法确定不同性别的病患在各个年龄段上的二维分布,因为边际投影重构出的联合分布并不唯一。传统的自动算法能够给出重构分布的少数“可行解”,却无法结合用户的先验知识、也不一定符合现实情况。
在这篇文章中[1],作者提出了一种可视分析方法,通过高维可视化手段、重构并展示大量潜在的联合分布,以帮助用户识别其中符合事实或预期的、有价值的分布。
研究背景
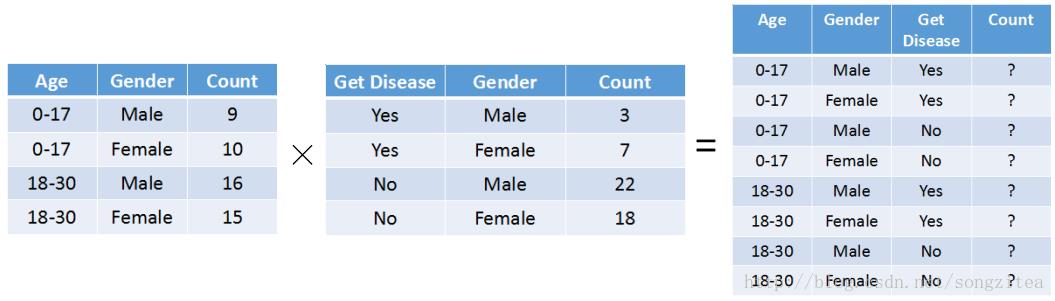
图1. 由边际投影重构联合分布
在现实生活中,我们常常把同一份多变量数据记录在多张表格里。图1所示为一群人的患病情况统计,其中一张表格记录了人群的年龄和性别分布,另一张则记录了性别和患病与否的信息,它们是同一份数据的不同边际投影。如何从中恢复出原始的联合分布,是数据处理中较为常见的问题。传统的自动算法[2]能够给出可能的分布,但这些分布不一定符合事实和用户的期望。譬如在手足口病中,青少年(0-17岁)的患病概率要明显高于成年人(18-30岁),自动算法却无法运用这些先验知识。该文章即针对这一情况设计了完整的可视分析流程,以帮助用户结合自身知识,重构、观察和筛选联合分布。
方法设计
文章提出的可视分析流程主要分为四步(如图2):缩减解空间、解空间采样、解样本可视化,以及交互分析。
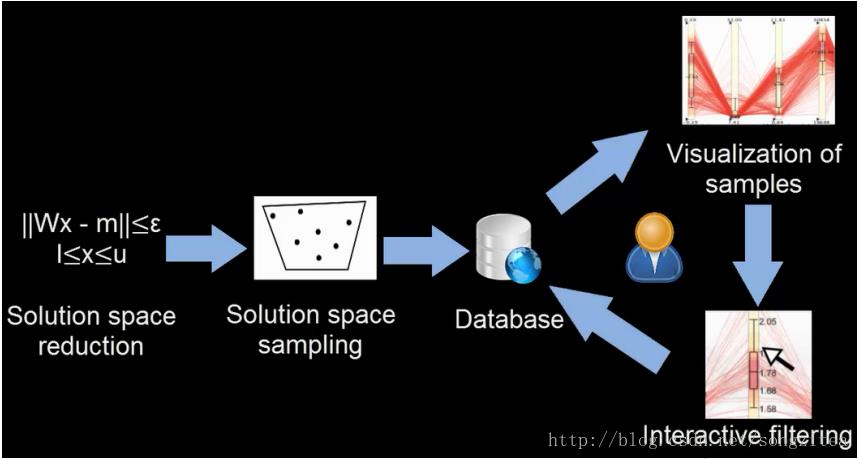
图2. 解空间可视分析流程
1. 缩减解空间
对于给定的边际投影,其重构出的所有可能的联合分布组成一个解空间(Solution Space)。在解空间中,每个点是一个联合分布,每个维度是一种变量取值的组合(如“0-17/男性/患病”、“18-30/女性/患病”等),各维数值则是相应的统计数目(如共有7人属于“0-17/男性/患病”)。其中,变量取值的组合数量极其庞大:假设数据集具有10个变量,每个变量有四种可能的取值,则完整的联合分布将包含4^10约一百万种取值组合。解空间的维度数高达百万,非常难以探索。因此在处理之前,需要添加一定的条件限制,以减小解空间。事实上,很多变量取值的组合都是不可能的,例如孕情与性别两个变量,“怀孕+男性”的取值组合就不可能发生,可以提前去掉。此外,各维取值即统计数目均为非负整数,可以进一步削减解空间。通过去除冗余的组合、添加各类限制,我们能够大为降低解空间的维度数。
2. 解空间采样
解样本可视化在解空间中,任意一个点都是一个可能的联合分布,无法遍历枚举。为探究其性质,有必要对其进行均匀、广泛的采样。文章采用了“Hit-and-run”的采样策略:在解空间中任选一个起始点(图3(a)),并选定一个任意的方向与距离(图3(b)、(c))移动到下一个点,在移动一定步数后即得到候选样本(图3(d))。由于样本在各维度上的取值只能是非负整数,最后还需要对样本进行局部位移,取其邻近的整数点作为最终的解样本。完成采样后,所有样本均存储在数据库中,以方便后续处理。
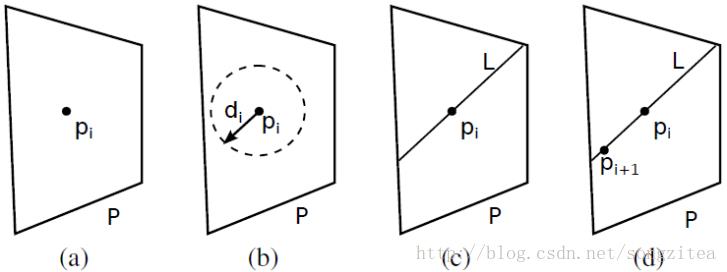
图3. 解空间的Hit-and-run采样
3. 解空间可视化
作者们采用了平行坐标的方式来展现解样本在不同指标上的分布。其中各类指标由用户自定义,如维度相关性、特定事件的统计数目等,用以检验解样本是否符合客观事实和用户的先验知识。具体的可视化设计如图4所示,其中轴上的和图、顶部的概率密度函数等反映了解样本集在不同指标上的分布状况与趋势。
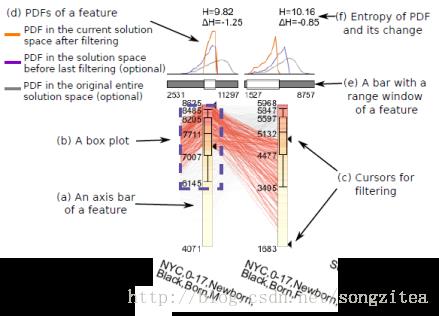
图4. 基于平行坐标的解空间可视化
4.交互分析
用户可以在平行坐标的各个轴上进行筛选,从而在选定范围内增加样本、过滤无关样本,直到最终获得满意的联合分布。
案例分析
案例分析使用的是纽约市公共健康数据,包含六个变量、约一千万份数据样本。解空间共有84,240个变量取值的组合,通过缩减能够减少至4505个有效组合。
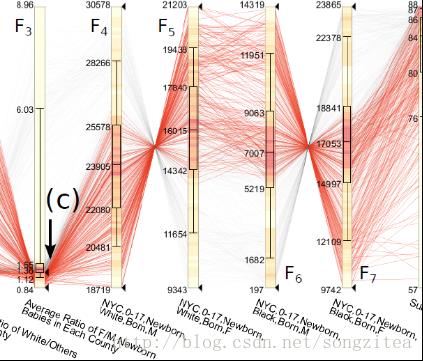
图5. 案例分析:不同性别与族裔的新生儿数量比较
总的来说,该文章针对联合分布的重构问题,设计了完整的解空间构造、采样、可视分析的流程,能够有效地辅助用户对潜在的联合分布进行检验和筛选。事实上,除了分布重构,还有许多其他实际问题具有探索解空间的需求。如何通过可视分析的手段,帮助用户对大量可行解进行了解、审视和挑选,仍然是一个值得研究的课题。
在图5中,用户利用了族裔、性别、年龄三个变量定义了数个关于新生儿的指标,分别是“白种人/男性/新生儿”、“白种人/女性/新生儿”、“黑种人/男性/新生儿”和“黑种人/女性/新生儿”(对应图5第2至5轴)。由各轴的数值范围可见,白种人的男性新生儿要多于女性新生儿,而黑种人的情况则恰好相反。但事实上,男、女新生儿的数量应该大致持平,这说明样本集中的很大一部分可能并不符合现实情况。因此,用户定义了新的指标为“男女新生儿比例”,并将其取值限定在1附近(图5第1轴)。高亮的结果显示,选出来的样本使得男女新生儿数目更加接近,用户可以继续增加这部分样本做进一步的探究。
[1] Xie C, Zhong W, Mueller K. A Visual Analytics Approach for Categorical Joint Distribution Reconstruction from Marginal Projections. IEEE Transactions on Visualization and Computer Graphics (TVCG), 2017, 23(1): 51-60.
[2] Deming W E, Stephan F F. On a least squares adjustment of a sampled frequency table when the expected marginal totals are known. The Annals of Mathematical Statistics, 11(4):427–444, 1940.
以上是关于从边际投影中重构类别型联合分布的可视分析方法(A Visual Analytics Approach for Categorical Joint Distribution Reconstruction的主要内容,如果未能解决你的问题,请参考以下文章