复用tcmalloc源码中的基数树进行优化
Posted 4nc414g0n
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了复用tcmalloc源码中的基数树进行优化相关的知识,希望对你有一定的参考价值。
复用tcmalloc源码中的基数树进行优化
基数树(radix tree)
基数树:
- 压缩前缀树,是一种更节省空间的Trie(前缀树)。对于基数树的每个节点,如果该节点是确定的子树的话,就和父节点合并。基数树可用来构建关联数组。 用于IP 路由。 信息检索中用于文本文档的倒排索引
- 基数树将长整数与指针键值相关联,解决Hash冲突和Hash表大小的设计问题
- 利用基数树可以根据一个长整型(比如一个长ID,或一串地址)快速查找到其对应的对象指针(在redis中用来存储stream消息队列,tcmalloc中用来建立page id和span*的映射)
- 基数树的空间使用更加灵活,只有当需要用到某节点时才会去创建它(pageMap)
基数树的插入查找:
- 插入
- 查找:
- 删除 分为两种:
惰性删除:即沿着路径查找到叶节点后,直接删除叶节点,中间的非叶节点不删除
非惰性删除:将删除后只有一条边的顶点向上合并基数树的缺点:
- 基数树另一个主要的缺陷是低效。即使你只想存一个键值对,但其中的键长度有几百字符长,那么每个字符的那个层级你都需要大量的额外空间。每次查找和删除都会有上百个步骤。可以使用Patricia树来解决这个问题(参考:Merkle Patricia Tree(MPT))

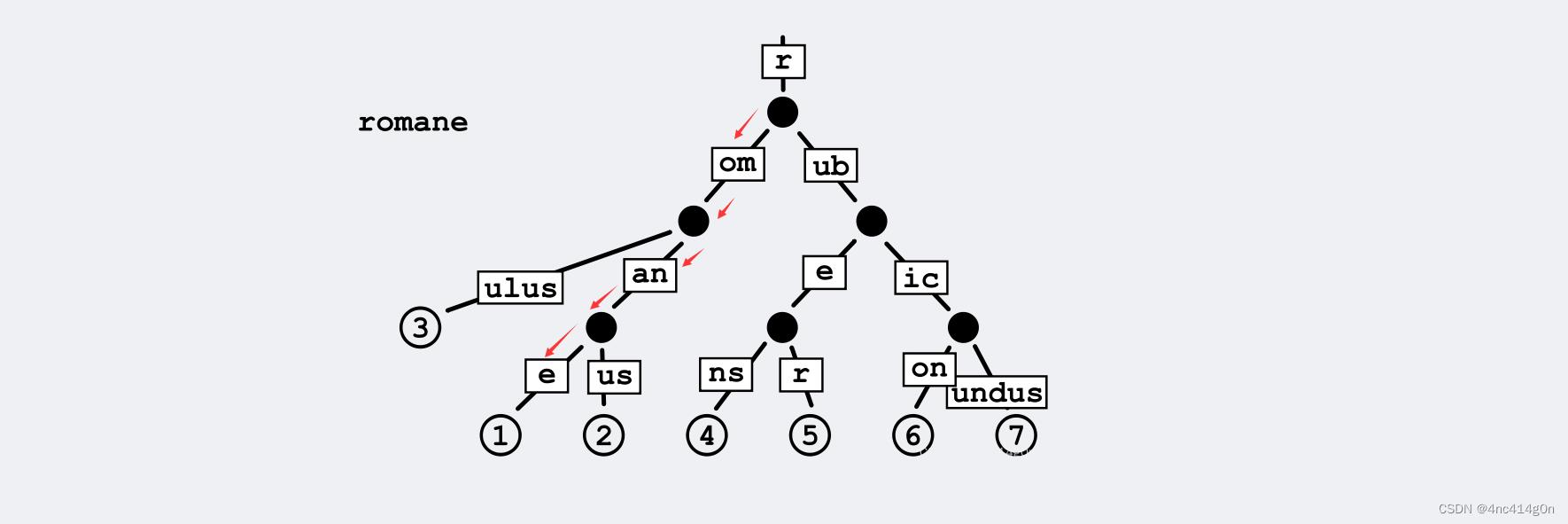
tcmalloc中的基数树
PageMap
TCMalloc中针对32、64位系统设计了不同基数树(考虑这个映射表占用内存的大小):
- 32位系统使用二级的Radix Tree(PageMap2),Two-level radix tree
- 64位系统使用三级Radix Tree(PageMap3),Three-level radix tree
- PageMap负责判断并调用PageMap2与PageMap3
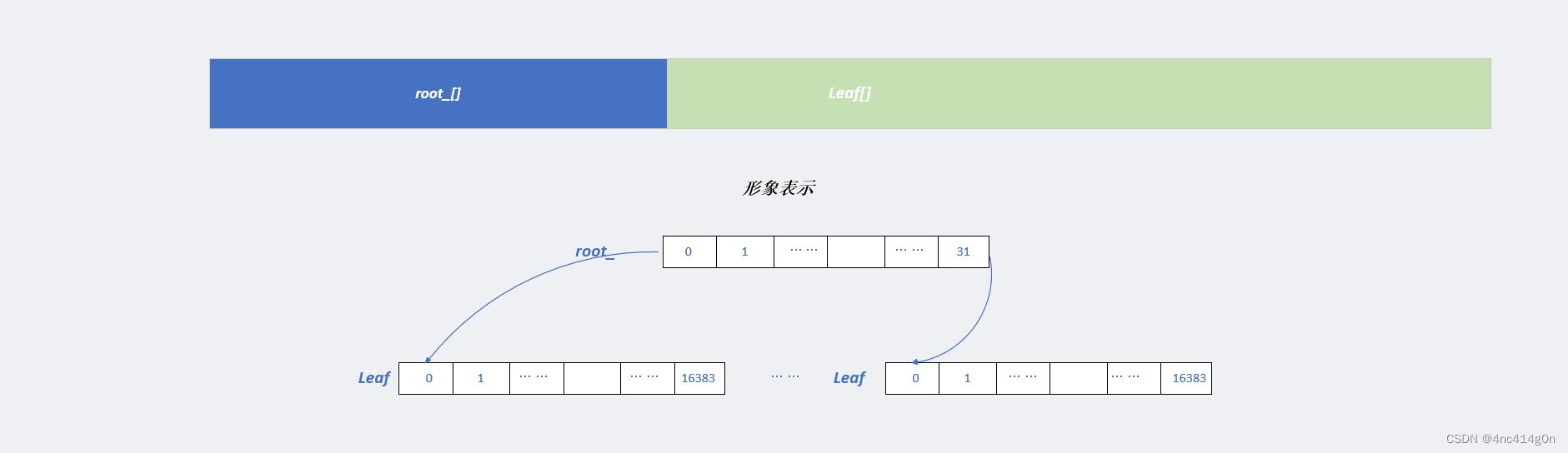
PageMap2(Two-level radix tree):
(叶节点(无论指针大小)总是映射 215 个条目;对于 8K 的页,为每个叶节点提供了 256MB 的映射)
- 非类型模板参数BITS保存了记录存储所有页所需要的比特位(32位下是32 -TCMALLOC_PAGE_SHIFT, 64位下48 -TCMALLOC_PAGE_SHIFT)
- TCmalloc中TCMALLOC_PAGE_SHIFT的值分多种情况:
- 以32位下TCMALLOC_PAGE_SHIFT=13为例:
BITS为32-13=19,kLeafBits=15(叶节点总是映射 215 个条目)kLeafLength=32768字节,kRootBits根节点=19-5=4((1<<kRootBits) 不能溢出“int”) kRootLength=16字节- 叶节点Leaf定义在PageMap2里面
PageMap2私有一个Leaf*的数组,Leaf私有一个Span*的数组- 共19页将高4位作为root_[],而低15位作为Leaf[](???Leafbits为什么是15??应该root 5 leaf 14)
如图:
PageMap3(Three-level radix tree):
对于 x86有 48 个可用位(__x86_64__处理器中,只用了地址的低48bits用于虚拟和物理地址的转换,高16bits是不用的),对于 PowerPC,只有 46 个可用位(这里不做讨论)
- 此处BITS为48-13=35,与二级类似,不做赘述,只是增加了一个struct Node作为Mid-level
分为三级,第一级root_[]占12位,第二级leafs[]占12位,第三级span[]占11位- 如图所示:




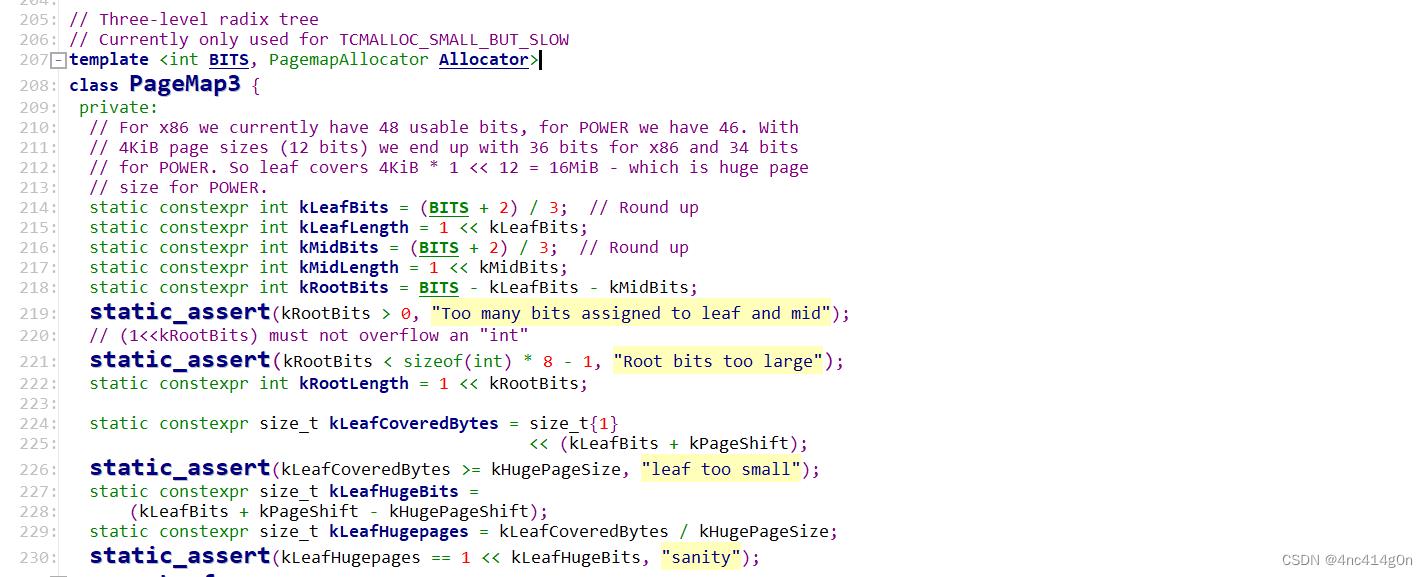


get与set,Ensure
对于PageMap2:
- 页号为k,i1为root_[]中的下标,i2为span中的下标,映射关系如下
- 对于i1, kLeafBits=15,右移kLeafBits位,取k高4位即kRootBits位,作为root_[]找span[]的下标 (4-15??5-14??)
- 对于i2,(kLeafLength-1)(215-1)就是将第15位值0,其他位(0-14)置1,相&,即取k低15位作为span[]的下标
对于PageMap3:
- 同理,移位操作i1,i2,i3作为root_[], leafs[], span[]的下标
对于PagaeMap2与PageMap3都有一个Ensure函数用于确认以及开辟空间:
- 第一层root_[]都是提前开好的,注释可见,而成,三层都是在需要时才开辟空间,减少元数据的内存占用
其他函数如get_next_set_page(), 获取下一个set好的页 等这里不做讨论






使用基数树为什么可以不用加锁
之前使用unordered_map时可能有的线程在建立映射,有的线程在使用MapToSpan()进行读取 (必须加锁)
- 若使用set,底层是红黑树:遍历时如果正好在进行旋转(左右旋),映射关系发生变化,出错
- 若使用unordered_map, 底层是哈希桶,遍历时刚好在进行扩容或插入删除,桶也变了,错误
而使用基数树:
- 插入时不会动结构,在写之前会提前开好空间(红黑树或哈希桶会动结构)
- 只有两个函数FetchNewSpan和ReleaseSpanToPageCache会使用_pageMap建立映射,多个线程不可能对同一个位置进行写(调用这两个函数时已加锁)
- 读写是分离的,不可能读的时候在写
改造PageMap并复用
增加了一个一层的PageMap1(采用直接定值法哈希(提前开好))
PageMap1 (One-level radix tree)
- 私有一个指针数组的指针array_
- get,set操作很简单(就是直接定值法哈希)
- 源码中使用了Allocator空间配置器开辟空间,本质上也是使用了malloc,为了脱离使用,直接使用SystemAlloc开辟空间
对于PageMap2,PageMap3:
- 源码中使用了Allocator空间配置器开辟空间,本质上也是使用了malloc,为了脱离使用,这里使用定长内存池ObjectPool来开辟空间
- 只留下get set Ensure这三个主体函数
vs studio改为x86, 复用PageMap2,替换映射函数,修改PageCache私有_pageMap
#ifdef _WIN64 PageMap3<48 - PAGE_SHIFT> _pageMap;//64位下使用PageMap3 #else PageMap2<32 - PAGE_SHIFT> _pageMap;//32位下使用PageMap2 #endif //std::unordered_map<PAGE_ID, Span*> _pageMap;再次对比性能:
性能明显提高

VS Studio进行性能瓶颈分析
未使用基数树之前:
使用调试中的性能探测器:

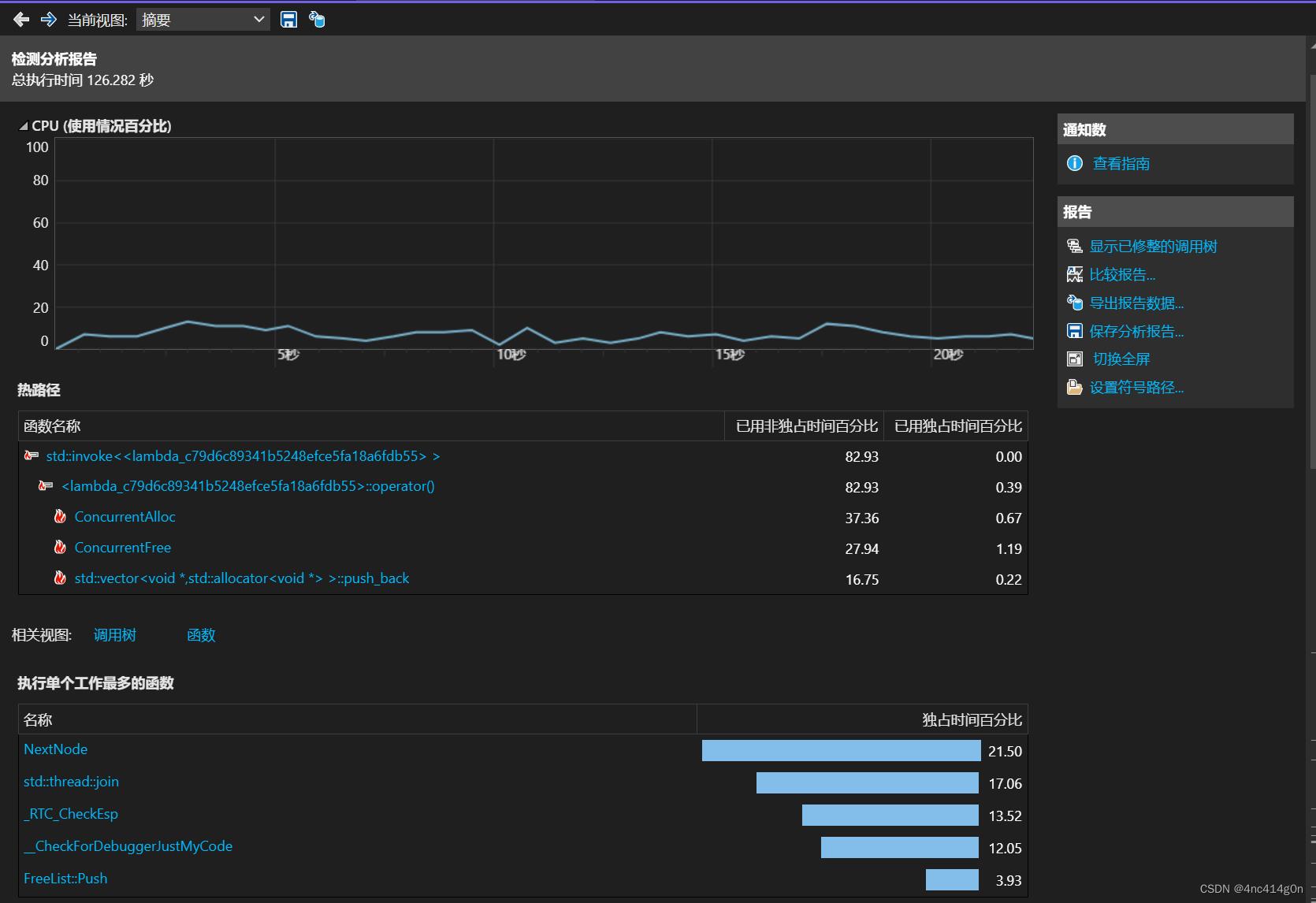
使用基数树进行优化后
lock不再是独占时间最多的
- 点入函数名称可以看到细节:


以上是关于复用tcmalloc源码中的基数树进行优化的主要内容,如果未能解决你的问题,请参考以下文章