python爬虫之Scrapy框架,基本介绍使用以及用框架下载图片案例
Posted the丶only
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫之Scrapy框架,基本介绍使用以及用框架下载图片案例相关的知识,希望对你有一定的参考价值。
一、Scrapy框架简介
Scrapy是:由Python语言开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据,只需要实现少量的代码,就能够快速的抓取。
Scrapy使用了Twisted异步网络框架来处理网络通信,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活地实现各种需求。
Scrapy可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的程序中,其最初是为页面抓取(更确切地说是网络抓取)而设计的,也可以应用于获取API所返回的数据(例如Amazon Associates Web Services)或者通用的网络爬虫。
二、Scrapy架构
1、架构图
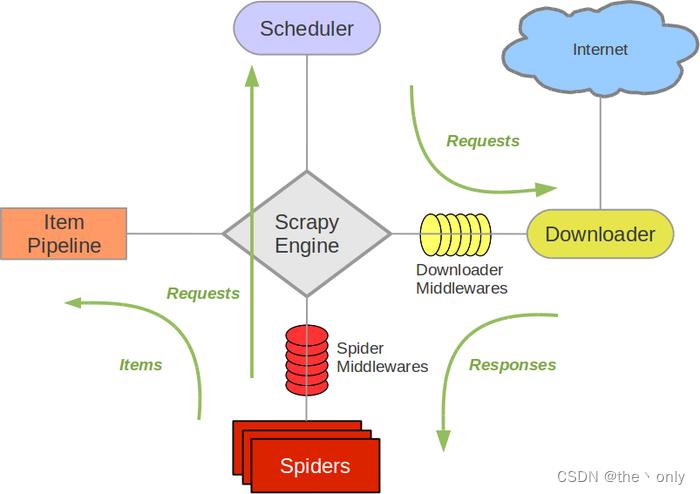
官方架构图
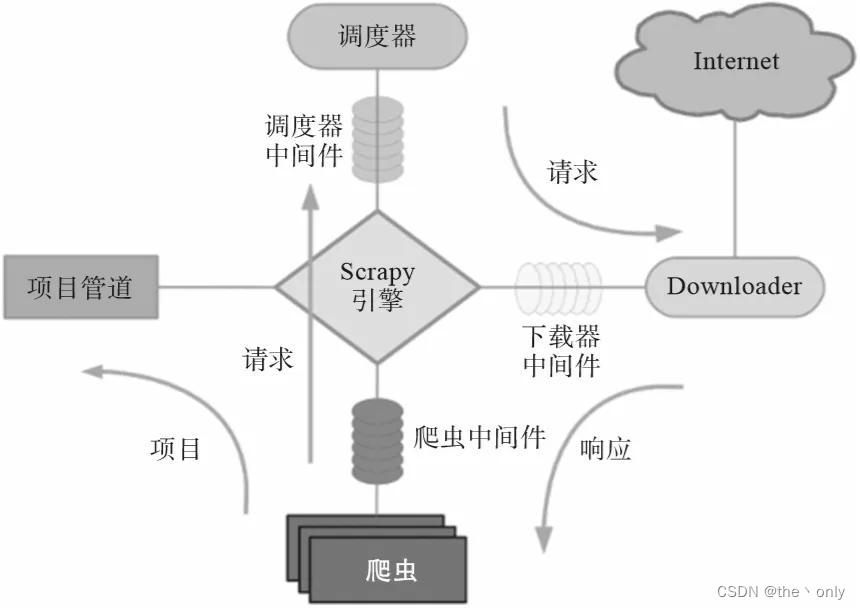
翻译架构图
2、组件
Scrapy主要包括了以下组件:
- 爬虫中间件(Spider Middleware):位于Scrapy引擎和爬虫之间的框架,主要用于处理爬虫的响应输入和请求输出。
- 调度器中间件(Scheduler Middleware):位于Scrapy引擎和调度器之间的框架,主要用于处理从Scrapy引擎发送到调度器的请求和响应。
- 调度器(Scheduler):用来接收引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。它就像是一个URL的优先队列,由它来决定下一个要抓取的网址是什么,同时在这里会去除重复的网址。
- 下载器中间件(Downloader Middleware):位于Scrapy引擎和下载器之间的框架,主要用于处理Scrapy引擎与下载器之间的请求及响应。代理IP和用户代理可以在这里设置。
- 下载器(Downloader):用于下载网页内容,并将网页内容返回给爬虫。
Scrapy引擎(ScrapyEngine):用来控制整个系统的数据处理流程,并进行事务处理的触发。 - 爬虫(Spiders):爬虫主要是干活的,用于从特定网页中提取自己需要的信息,即所谓的项目(又称实体)。也可以从中提取URL,让Scrapy继续爬取下一个页面。
- 项目管道(Pipeline):负责处理爬虫从网页中爬取的项目,主要的功能就是持久化项目、验证项目的有效性、清除不需要的信息。当页面被爬虫解析后,将被送到项目管道,并经过几个特定的次序来处理其数据。
3、运行流程
数据流(Data flow),Scrapy中的数据流由执行引擎(ScrapyEngine)控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站
三、Scrapy安装以及生成项目
1、下载安装
Linux下载方式,直接安装
pip install scrapy
或者
pip3 install scrapy)
windows 如果用Pycharm的话,在Pycharm底部打开命令终端
输入命令
pip install scrapy
2、创建Scrapy项目
#创建一个叫ScrapyDemmo
scrapy startproject ScrapyDemmo
#进入项目文件夹
cd ScrapyDemmo
#创建一个名为baidu的爬虫,爬虫目标www.baidu.com
scrapy genspider baidu www.baidu.com
创建完成后,目录结构如下:
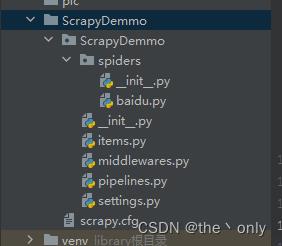
- scrapy.cfg: 项目的配置文件。
- scrapyspider/: 该项目的python模块。之后您将在此加入代码。
- scrapyspider/items.py: 项目中的item文件。
- scrapyspider/pipelines.py: 项目中的pipelines文件。
- scrapyspider/settings.py: 项目的设置文件。
- scrapyspider/spiders/: 放置spider代码的目录。
spiders下的baidu.py是scrapy用命令(scrapy genspider baidu www.baidu.com)自动为我们生成的。
内容如下:
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['www.baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
title = response.xpath('//html/dead/title/text()')
print(title)
当然,可以不用命令生成,可以自己在spiders下创建爬虫,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
- name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
- start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
- parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
3、运行爬虫
运行方法:
在项目目录底下用命令运行,如下,我项目目录 D:\\Python\\ScrapyDemmo,运行name为baidu的爬虫
D:\\Python\\ScrapyDemmo> scrapy crawl baidu
在scrapy中,为了避免每一次运行或调试都输入一串命令,可以在项目文件下新建一个run.py文件,每次运行爬虫只需要运行此脚本即可。且运行调试模式也需要设置此启动脚本。
from scrapy import cmdline
cmdline.execute("scrapy crawl baidu".split())
最后运行这个run.py即可,执行结果:
D:\\Python\\venv\\Scripts\\python.exe D:\\Python\\ScrapyDemmo\\ScrapyDemmo\\run.py
2022-10-28 10:12:55 [scrapy.utils.log] INFO: Scrapy 2.7.0 started (bot: ScrapyDemmo)
2022-10-28 10:12:55 [scrapy.utils.log] INFO: Versions: lxml 4.9.1.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 2.0.1, Twisted 22.8.0, Python 3.9.13 (tags/v3.9.13:6de2ca5, May 17 2022, 16:36:42) [MSC v.1929 64 bit (AMD64)], pyOpenSSL 22.1.0 (OpenSSL 3.0.5 5 Jul 2022), cryptography 38.0.1, Platform Windows-10-10.0.22000-SP0
2022-10-28 10:12:55 [scrapy.crawler] INFO: Overridden settings:
'BOT_NAME': 'ScrapyDemmo',
'NEWSPIDER_MODULE': 'ScrapyDemmo.spiders',
'REQUEST_FINGERPRINTER_IMPLEMENTATION': '2.7',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['ScrapyDemmo.spiders'],
'TWISTED_REACTOR': 'twisted.internet.asyncioreactor.AsyncioselectorReactor'
2022-10-28 10:12:55 [asyncio] DEBUG: Using selector: SelectSelector
2022-10-28 10:12:55 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.asyncioreactor.AsyncioSelectorReactor
2022-10-28 10:12:55 [scrapy.utils.log] DEBUG: Using asyncio event loop: asyncio.windows_events._WindowsSelectorEventLoop
2022-10-28 10:12:55 [scrapy.extensions.telnet] INFO: Telnet Password: 8f7196797757e0f5
2022-10-28 10:12:55 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2022-10-28 10:12:55 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2022-10-28 10:12:55 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2022-10-28 10:12:55 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2022-10-28 10:12:55 [scrapy.core.engine] INFO: Spider opened
2022-10-28 10:12:55 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2022-10-28 10:12:55 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2022-10-28 10:12:55 [filelock] DEBUG: Attempting to acquire lock 2507249710320 on D:\\Python\\venv\\lib\\site-packages\\tldextract\\.suffix_cache/publicsuffix.org-tlds\\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-10-28 10:12:55 [filelock] DEBUG: Lock 2507249710320 acquired on D:\\Python\\venv\\lib\\site-packages\\tldextract\\.suffix_cache/publicsuffix.org-tlds\\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-10-28 10:12:55 [filelock] DEBUG: Attempting to release lock 2507249710320 on D:\\Python\\venv\\lib\\site-packages\\tldextract\\.suffix_cache/publicsuffix.org-tlds\\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-10-28 10:12:55 [filelock] DEBUG: Lock 2507249710320 released on D:\\Python\\venv\\lib\\site-packages\\tldextract\\.suffix_cache/publicsuffix.org-tlds\\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock
2022-10-28 10:12:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com/robots.txt> (referer: None)
2022-10-28 10:12:55 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://www.baidu.com/>
2022-10-28 10:12:55 [scrapy.core.engine] INFO: Closing spider (finished)
2022-10-28 10:12:55 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
若嫌弃scrapy日志文件太杂乱,想无日志输出,只需在后面增加–nolog即可:
from scrapy import cmdline
cmdline.execute('scrapy crawl baidu --nolog'.split())
执行导出为json或scv格式,执行爬虫文件时添加-o选项即可
scrapy crawl 项目名 -o *.csv
scrapy crawl 项目名 -o *.json
对于json文件,在setting.js文件里添加,设置编码格式,否则会乱码:
from scrapy import cmdline
cmdline.execute('scrapy crawl baidu -o baidu.csv'.split())
四、Scrapy配置文件settings.py
默认配置文件,主要设置参数:
BOT_NAME = 'ScrapyDemmo' #Scrapy项目的名字,这将用来构造默认 User-Agent,同时也用来log,当您使用 startproject 命令创建项目时其也被自动赋值。
SPIDER_MODULES = ['ScrapyDemmo.spiders'] #Scrapy搜索spider的模块列表 默认: [xxx.spiders]
NEWSPIDER_MODULE = 'ScrapyDemmo.spiders' #使用 genspider 命令创建新spider的模块。默认: 'xxx.spiders'
#爬取的默认User-Agent,除非被覆盖
#USER_AGENT = 'ScrapyDemmo (+http://www.yourdomain.com)'
#如果启用,Scrapy将会采用 robots.txt策略
ROBOTSTXT_OBEY = True
#Scrapy downloader 并发请求(concurrent requests)的最大值,默认: 16
#CONCURRENT_REQUESTS = 32
#为同一网站的请求配置延迟(默认值:0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3 #下载器在下载同一个网站下一个页面前需要等待的时间,该选项可以用来限制爬取速度,减轻服务器压力。同时也支持小数:0.25 以秒为单位
#下载延迟设置只有一个有效
#CONCURRENT_REQUESTS_PER_DOMAIN = 16 #对单个网站进行并发请求的最大值。
#CONCURRENT_REQUESTS_PER_IP = 16 #对单个IP进行并发请求的最大值。如果非0,则忽略
#禁用Cookie(默认情况下启用)
#COOKIES_ENABLED = False
#禁用Telnet控制台(默认启用)
#TELNETCONSOLE_ENABLED = False
#覆盖默认请求标头:
#DEFAULT_REQUEST_HEADERS =
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#
#项目管道,300为优先级,越低越爬取的优先度越高
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES =
# 'ScrapyDemmo.pipelines.ScrapydemmoPipeline': 300,
#
还可以设置日志的等级与日志存放的路径:
相关变量
LOG_LEVEL= ""
LOG_FILE="日志名.log"
日志等级分为,默认等级是1
1.DEBUG 调试信息
2.INFO 一般信息
3.WARNING 警告
4.ERROR 普通错误
5.CRITICAL 严重错误
如果设置
LOG_LEVEL=“WARNING”,就只会WARNING等级之下的ERROR和CRITICAL
一般主要需要配置的几个参数,其他按需配置即可。
USER_AGENT:默认是注释的,这个东西非常重要,如果不写很容易被判断为电脑爬虫。
ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true,需要改为false,否则很多东西爬不了
DEFAULT_REQUEST_HEADERS:和USER_AGENT类似,只是参数更完整。
五、完整案例(下载图片)
用scrapy框架下载以前的示例:python爬虫之批量下载图片
以前
1、修改settings.py 主要参数
#关闭robot.txt协议
ROBOTSTXT_OBEY = False
#页面延迟下载,我这里测试,可以先不设置
DOWNLOAD_DELAY = 1
# 是否启用Cookie
COOKIES_ENABLED = True
#请求头
DEFAULT_REQUEST_HEADERS =
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
#打开下载器
DOWNLOADER_MIDDLEWARES =
'ScrapyDemmo.middlewares.ScrapydemmoDownloaderMiddleware': 543,
#打开优先级,并添加自己编写的图片下载管道
ITEM_PIPELINES =
'ScrapyDemmo.pipelines.ScrapydemmoPipeline': 300,
'ScrapyDemmo.pipelines.ImageDownloadPipeline': 300,
#添加下载储存目录
IMAGES_STORE = 'D:\\Python\\pic'
# 文件保存时间
#IMAGES_EXPIRES = 90
2、定义Item字段(Items.py)
本项目用于下载图片,因此可以仅构建图片名和图片地址字段。
import scrapy
class ScrapydemmoItem(scrapy.Item):
#图片下载链接
image_url = scrapy.Field()
#图片名称
image_name = scrapy.Field()
3、编写爬虫文件(spiders目录下)
这里文件名为:image_download.py
以前用requests库和BeautifulSoup库下载图片,这里就不需要了,scrapy自带相关函数和方法。
scrapy元素定位,提供三种方式,正则、Xpath表达式、css。
我这里有xpath定位方式。
import scrapy
import re
from ..items import ScrapydemmoItem
class ImageSpider(scrapy.Spider):
name = 'image_download'
allowed_domains = ['desk.3gbizhi.com']
start_urls = ['https://desk.3gbizhi.com/deskMV/index.html']
def parse(self, response):
#导入Items.py字段
items = ScrapydemmoItem()
#获取所有链接列表
lists = response.xpath('//div[5]/ul/li')
#点位元素循环获取图片链接和图片名称
for i in lists:
#图片名称
image_name = i.xpath('./a/img/@alt').get()
#图片链接
items['image_url'] = i.xpath('./a/img/@*[1]').get().replace('.278.154.jpg', '')
#图片格式类型
image_type = re.sub(r'h.*\\d+.', '', items['image_url'])
#拼接文件名,图片名称+图片格式
items['image_name'] = '.'.format(image_name, image_type)
yield items
#循环跳转下一页,并重复返回数据,这里测试先下载1页的图片,总共23页。
for i in range(2,3):
next_url = 'https://desk.3gbizhi.com/deskMV/index_.html'.format(i)
yield scrapy.Request(next_url,callback=self.parse)
关于 yield 的理解,⾸先,如果你还没有对yield有个初步分认识,那么你先把yield看做“return”,这个是直观的,它⾸先是个return。
最主要的不同在于yield在返回值后还可以继续运行接下来的代码,使用的函数会返回一个生成器,而return在返回后就不在执行代码。
以上两个yield:
-
yield items:这里我们通过 yield 返回的不是 Request 对象,而是一个 ScrapydemmoItem 对象。
scrap有框架获得这个对象之后,会将这个对象传递给 pipelines.py来做进一步处理。
我们将在 pipelines.py里将传递过来的 scrapy.Item 对象保存到数据库里去。 -
yield scrapy.Request:这里是在爬取完一页的信息后,我们在当前页面获取到了下一页的链接,然后通过 yield 发起请求,并且将 parse 自己作为回调函数来处理下一页的响应。
4、修改管道文件pipelines.py用于下载图片
除了爬取文本,我们可能还需要下载文件、视频、图片、压缩包等,这也是一些常见的需求。scrapy提供了FilesPipeline和ImagesPipeline,专门用于下载普通文件及图片。
继承 Scrapy 内置的 ImagesPipeline,只需要重写get_media_requests 和item_completed函数即可。
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy import Request
class ScrapydemmoPipeline:
def process_item(self, item, spider):
return item
class ImageDownloadPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 下载图片,如果传过来的是集合需要循环下载
# meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
yield Request(url = item['image_url'],meta = 'filename':item['image_name'])
def item_completed(self, results, item, info):
# 分析下载结果并剔除下载失败的图片
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
def file_path(self, request, response=None, info=None):
# 接收上面meta传递过来的图片名称
file_name = request.meta['filename']
return file_name
- get_media_requests()。它的第一个参数 item 是爬取生成的 Item 对象。我们将它的 url 字段取出来,然后直接生成 Request 对象。此 Request 加入调度队列,等待被调度,执行下载。
- item_completed(),它是当单个 Item 完成下载时的处理方法。因为可能有个别图片未成功下载,所以需要分析下载结果并剔除下载失败的图片。该方法的第一个参数 results 就是该 Item 对应的下载结果,它是一个列表形式,列表每一个元素是一个元组,其中包含了下载成功或失败的信息。这里我们遍历下载结果找出所有成功的下载列表。如果列表为空,那么说明该 Item 对应的图片下载失败了,随即抛出异常DropItem,该 Item 忽略。否则返回该 Item,说明此 Item 有效。
以上两个函数即可下载图片了,图片名称为自动已哈希值命名,如:0db6e07054d966513f0a6f315b687f205c7ced90.jpg 这种命名方式不友好,所以我们需要重写 file_path函数,自定义图片名称。
- file_path():它的第一个参数 request 就是当前下载对应的 Request 对象。这个方法用来返回保存的文件名,接收上面meta传递过来的图片名称,将图片以原来的名称和定义格式进行保存。
5、编写执行文件run.py运行
在项目下新建run.py作为执行文件
from scrapy import cmdline
#cmdline.execute('scrapy crawl image_download --nolog'.split())
cmdline.execute('scrapy crawl image_download'.split())
运行此文件,执行结果,在目录下载第一页壁纸完成。
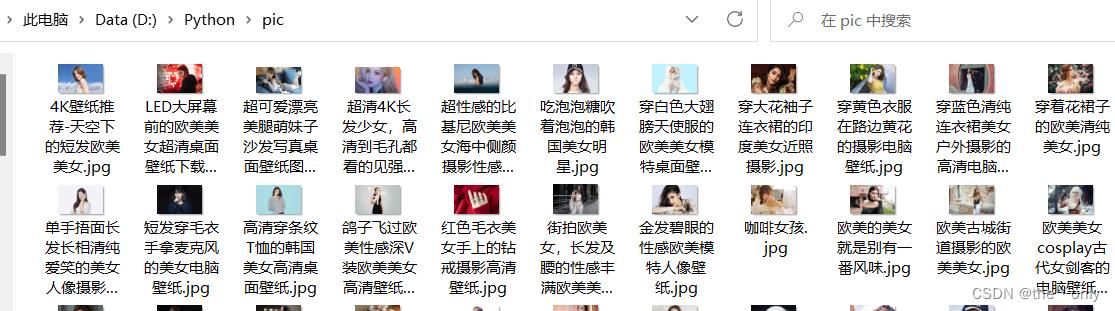
六、小结
除了 ImagesPipeline 处理图片外,还有 FilesPipeline 可以处理文件,使用方法与图片类似,事实上 ImagesPipeline 是 FilesPipeline 的子类,因为图片也是文件的一种。
Scrapy很强大,对于大型网站非常实用,还可以同时运行多个爬虫程序,提升效率。Scrapy还有很多功能,可以自己研究。
以上是关于python爬虫之Scrapy框架,基本介绍使用以及用框架下载图片案例的主要内容,如果未能解决你的问题,请参考以下文章