Apache Spark 中支持的七种 Join 类型简介
Posted u4110122855
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Spark 中支持的七种 Join 类型简介相关的知识,希望对你有一定的参考价值。
数据分析中将两个数据集进行 Join 操作是很常见的场景。我在这篇文章中介绍了 Spark 支持的五种 Join 策略,本文我将给大家介绍一下 Apache Spark 中支持的 Join 类型(Join Type)。
目前 Apache Spark 3.0 版本中,一共支持以下七种 Join 类型:
-
INNER JOIN
-
CROSS JOIN
-
LEFT OUTER JOIN
-
RIGHT OUTER JOIN
-
FULL OUTER JOIN
-
LEFT SEMI JOIN
-
LEFT ANTI JOIN
在实现上,这七种 Join 对应的实现类分别如下:
object JoinType
def apply(typ: String): JoinType = typ.toLowerCase(Locale.ROOT).replace("_", "") match
case "inner" => Inner
case "outer" | "full" | "fullouter" => FullOuter
case "leftouter" | "left" => LeftOuter
case "rightouter" | "right" => RightOuter
case "leftsemi" | "semi" => LeftSemi
case "leftanti" | "anti" => LeftAnti
case "cross" => Cross
case _ =>
val supported = Seq(
"inner",
"outer", "full", "fullouter", "full_outer",
"leftouter", "left", "left_outer",
"rightouter", "right", "right_outer",
"leftsemi", "left_semi", "semi",
"leftanti", "left_anti", "anti",
"cross")
throw new IllegalArgumentException(s"Unsupported join type '$typ'. " +
"Supported join types include: " + supported.mkString("'", "', '", "'") + ".")
今天,我并不打算从底层代码来介绍这七种 Join 类型的实现,而是从数据分析师的角度来介绍这几种 Join 的含义和使用。在介绍下文之前,假设我们有顾客(customer)和订单(order)相关的两张表,如下:
scala> val order = spark.sparkContext.parallelize(Seq(
| (1, 101,2500), (2,102,1110), (3,103,500), (4 ,102,400)
| )).toDF("paymentId", "customerId","amount")
order: org.apache.spark.sql.DataFrame = [paymentId: int, customerId: int ... 1 more field]
scala> order.show
+---------+----------+------+
|paymentId|customerId|amount|
+---------+----------+------+
| 1| 101| 2500|
| 2| 102| 1110|
| 3| 103| 500|
| 4| 102| 400|
+---------+----------+------+
scala> val customer = spark.sparkContext.parallelize(Seq(
| (101,"iteblog") ,(102,"iteblog_hadoop") ,(103,"iteblog001"), (104,"iteblog002"), (105,"iteblog003"), (106,"iteblog004")
| )).toDF("customerId", "name")
customer: org.apache.spark.sql.DataFrame = [customerId: int, name: string]
scala> customer.show
+----------+--------------+
|customerId| name|
+----------+--------------+
| 101| iteblog|
| 102|iteblog_hadoop|
| 103| iteblog001|
| 104| iteblog002|
| 105| iteblog003|
| 106| iteblog004|
+----------+--------------+
准备好数据之后,现在我们来一一介绍这些 Join 类型。
INNER JOIN
在 Spark 中,如果没有指定任何 Join 类型,那么默认就是 INNER JOIN。INNER JOIN 只会返回满足 Join 条件( join condition)的数据,这个大家用的应该比较多,具体如下:
scala> val df = customer.join(order,"customerId")
df: org.apache.spark.sql.DataFrame = [customerId: int, name: string ... 2 more fields]
scala> df.show
+----------+--------------+---------+------+
|customerId| name|paymentId|amount|
+----------+--------------+---------+------+
| 101| iteblog| 1| 2500|
| 103| iteblog001| 3| 500|
| 102|iteblog_hadoop| 2| 1110|
| 102|iteblog_hadoop| 4| 400|
+----------+--------------+---------+------+
从上面可以看出,当我们没有指定任何 Join 类型时,默认就是 INNER JOIN;在生成的结果中, Spark 自动为我们删除了两张表都存在的 customerId。如果用图来表示的话, INNER JOIN 可以如下表示:
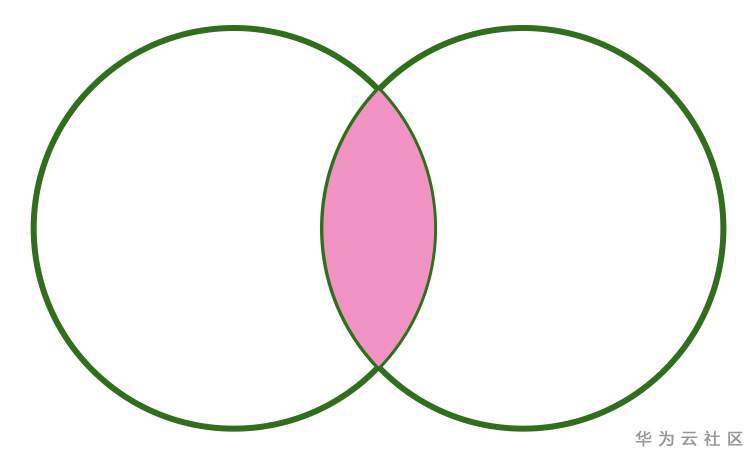
上图粉色部分就是 INNER JOIN 的结果。
CROSS JOIN
这种类型的 Join 也称为笛卡儿积(Cartesian Product),Join 左表的每行数据都会跟右表的每行数据进行 Join,产生的结果行数为 m*n,所以在生产环境下尽量不要用这种 Join。下面是 CROSS JOIN 的使用例子:
scala> val df = customer.crossJoin(order)
df: org.apache.spark.sql.DataFrame = [customerId: int, name: string ... 3 more fields]
scala> df.show
+----------+--------------+---------+----------+------+
|customerId| name|paymentId|customerId|amount|
+----------+--------------+---------+----------+------+
| 101| iteblog| 1| 101| 2500|
| 101| iteblog| 2| 102| 1110|
| 101| iteblog| 3| 103| 500|
| 101| iteblog| 4| 102| 400|
| 102|iteblog_hadoop| 1| 101| 2500|
| 102|iteblog_hadoop| 2| 102| 1110|
| 102|iteblog_hadoop| 3| 103| 500|
| 102|iteblog_hadoop| 4| 102| 400|
| 103| iteblog001| 1| 101| 2500|
| 103| iteblog001| 2| 102| 1110|
| 103| iteblog001| 3| 103| 500|
| 103| iteblog001| 4| 102| 400|
| 104| iteblog002| 1| 101| 2500|
| 104| iteblog002| 2| 102| 1110|
| 104| iteblog002| 3| 103| 500|
| 104| iteblog002| 4| 102| 400|
| 105| iteblog003| 1| 101| 2500|
| 105| iteblog003| 2| 102| 1110|
| 105| iteblog003| 3| 103| 500|
| 105| iteblog003| 4| 102| 400|
+----------+--------------+---------+----------+------+
only showing top 20 rows
LEFT OUTER JOIN
LEFT OUTER JOIN 等价于 LEFT JOIN,这个 Join 的返回的结果相信大家都知道,我就不介绍了。下面三种写法都是等价的:
val leftJoinDf = customer.join(order,Seq("customerId"), "left_outer")
val leftJoinDf = customer.join(order,Seq("customerId"), "leftouter")
val leftJoinDf = customer.join(order,Seq("customerId"), "left")
scala> leftJoinDf.show
+----------+--------------+---------+------+
|customerId| name|paymentId|amount|
+----------+--------------+---------+------+
| 101| iteblog| 1| 2500|
| 103| iteblog001| 3| 500|
| 102|iteblog_hadoop| 2| 1110|
| 102|iteblog_hadoop| 4| 400|
| 105| iteblog003| null| null|
| 106| iteblog004| null| null|
| 104| iteblog002| null| null|
+----------+--------------+---------+------+
如果用图表示的话,LEFT OUTER JOIN 可以如下所示:可以看出,参与 Join 的左表数据都会显示出来,而右表只有关联上的才会显示。
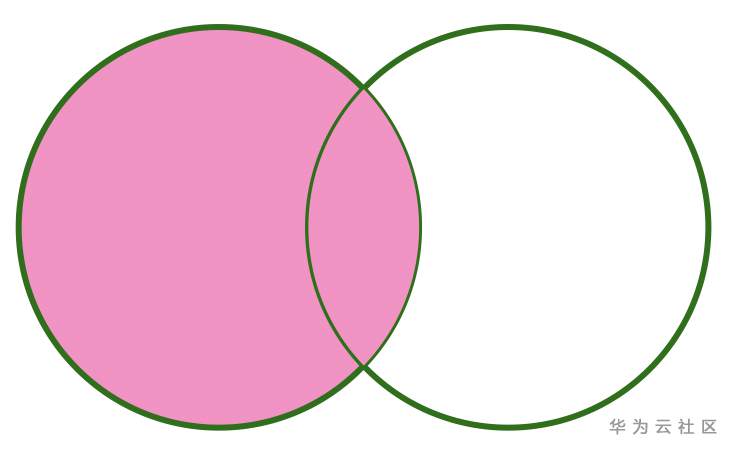
RIGHT OUTER JOIN
和 LEFT OUTER JOIN 类似,RIGHT OUTER JOIN 等价于 RIGHT JOIN,下面三种写法也是等价的:
val rightJoinDf = order.join(customer,Seq("customerId"), "right")
val rightJoinDf = order.join(customer,Seq("customerId"), "right_outer")
val rightJoinDf = order.join(customer,Seq("customerId"), "rightouter")
scala> rightJoinDf.show
+----------+---------+------+--------------+
|customerId|paymentId|amount| name|
+----------+---------+------+--------------+
| 101| 1| 2500| iteblog|
| 103| 3| 500| iteblog001|
| 102| 2| 1110|iteblog_hadoop|
| 102| 4| 400|iteblog_hadoop|
| 105| null| null| iteblog003|
| 106| null| null| iteblog004|
| 104| null| null| iteblog002|
+----------+---------+------+--------------+
如果用图表示的话,RIGHT OUTER JOIN 可以如下所示:可以看出,参与 Join 的右表数据都会显示出来,而左表只有关联上的才会显示。
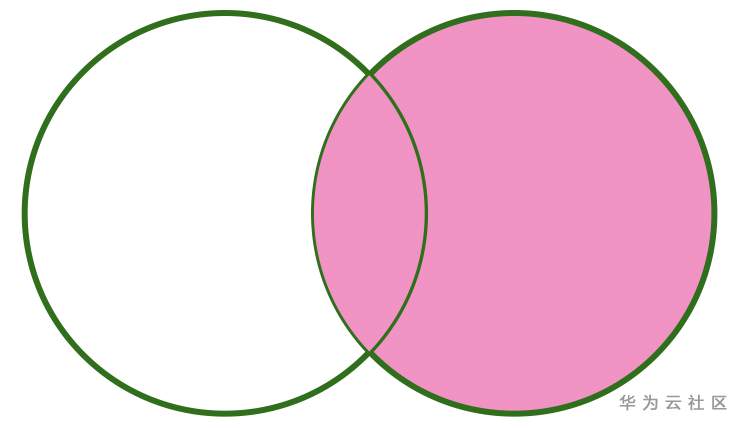
FULL OUTER JOIN
FULL OUTER JOIN 的含义大家应该也都熟悉,我就不介绍其含义了。FULL OUTER JOIN 有以下四种写法:
val fullJoinDf = order.join(customer,Seq("customerId"), "outer")
val fullJoinDf = order.join(customer,Seq("customerId"), "full")
val fullJoinDf = order.join(customer,Seq("customerId"), "full_outer")
val fullJoinDf = order.join(customer,Seq("customerId"), "fullouter")
scala> fullJoinDf.show
+----------+---------+------+--------------+
|customerId|paymentId|amount| name|
+----------+---------+------+--------------+
| 101| 1| 2500| iteblog|
| 103| 3| 500| iteblog001|
| 102| 2| 1110|iteblog_hadoop|
| 102| 4| 400|iteblog_hadoop|
| 105| null| null| iteblog003|
| 106| null| null| iteblog004|
| 104| null| null| iteblog002|
+----------+---------+------+--------------+
FULL OUTER JOIN 可以用如下图表示:
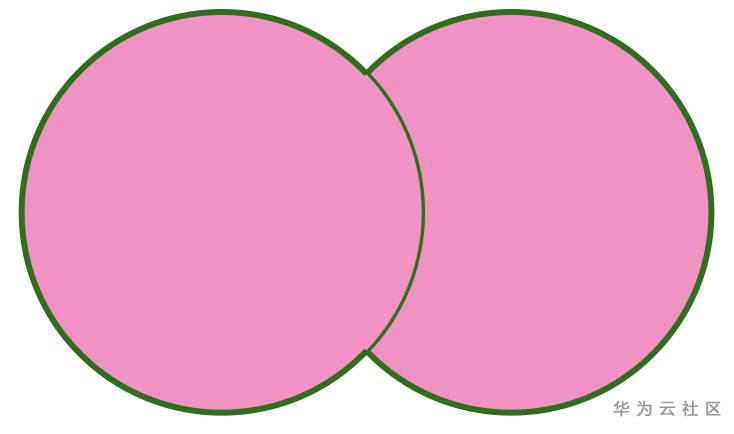
LEFT SEMI JOIN
LEFT SEMI JOIN 这个大家应该知道的人相对少些,LEFT SEMI JOIN 只会返回匹配右表的数据,而且 LEFT SEMI JOIN 只会返回左表的数据,右表的数据是不会显示的,下面三种写法都是等价的:
val leftSemiJoinDf = order.join(customer,Seq("customerId"), "leftsemi")
val leftSemiJoinDf = order.join(customer,Seq("customerId"), "left_semi")
val leftSemiJoinDf = order.join(customer,Seq("customerId"), "semi")
scala> leftSemiJoinDf.show
+----------+---------+------+
|customerId|paymentId|amount|
+----------+---------+------+
| 101| 1| 2500|
| 103| 3| 500|
| 102| 2| 1110|
| 102| 4| 400|
+----------+---------+------+
从上面结果可以看出,LEFT SEMI JOIN 其实可以用 IN/EXISTS 来改写:
scala> order.registerTempTable("order")
warning: there was one deprecation warning (since 2.0.0); for details, enable `:setting -deprecation' or `:replay -deprecation'
scala> customer.registerTempTable("customer")
warning: there was one deprecation warning (since 2.0.0); for details, enable `:setting -deprecation' or `:replay -deprecation'
scala> val r = spark.sql("select * from order where customerId in (select customerId from customer)")
r: org.apache.spark.sql.DataFrame = [paymentId: int, customerId: int ... 1 more field]
scala> r.show
+---------+----------+------+
|paymentId|customerId|amount|
+---------+----------+------+
| 1| 101| 2500|
| 3| 103| 500|
| 2| 102| 1110|
| 4| 102| 400|
+---------+----------+------+
LEFT SEMI JOIN 可以用下图表示:
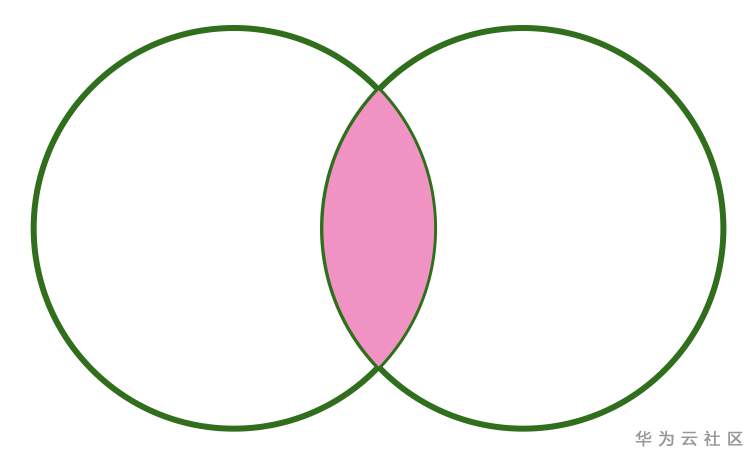
LEFT ANTI JOIN
与 LEFT SEMI JOIN 相反,LEFT ANTI JOIN 只会返回没有匹配到右表的左表数据。而且下面三种写法也是等效的:
val leftAntiJoinDf = customer.join(order,Seq("customerId"), "leftanti")
val leftAntiJoinDf = customer.join(order,Seq("customerId"), "left_anti")
val leftAntiJoinDf = customer.join(order,Seq("customerId"), "anti")
scala> leftAntiJoinDf.show
+----------+----------+
|customerId| name|
+----------+----------+
| 105|iteblog003|
| 106|iteblog004|
| 104|iteblog002|
+----------+----------+
同理,LEFT ANTI JOIN 也可以用 NOT IN 来改写:
scala> val r = spark.sql("select * from customer where customerId not in (select customerId from order)")
r: org.apache.spark.sql.DataFrame = [customerId: int, name: string]
scala> r.show
+----------+----------+
|customerId| name|
+----------+----------+
| 104|iteblog002|
| 105|iteblog003|
| 106|iteblog004|
+----------+----------+
LEFT SEMI ANTI 可以用下图表示:
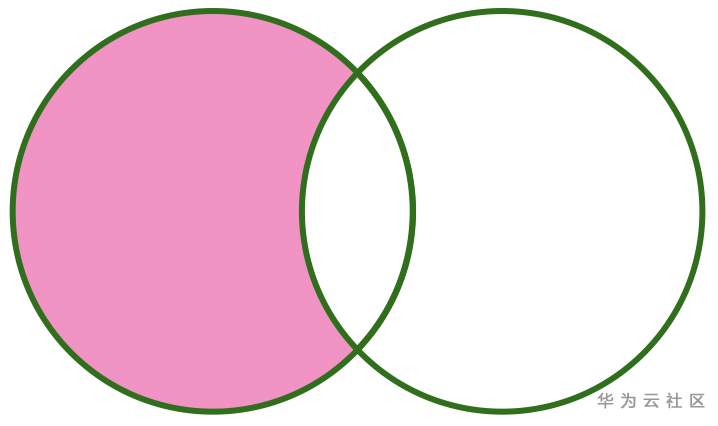
好了,Spark 七种 Join 类型已经简单介绍完了,大家可以根据不同类型的业务场景选择不同的 Join 类型。今天分享就到这,感谢大家关注支持。
以上是关于Apache Spark 中支持的七种 Join 类型简介的主要内容,如果未能解决你的问题,请参考以下文章