Day875.怎么给字符串字段加索引 -MySQL实战
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day875.怎么给字符串字段加索引 -MySQL实战相关的知识,希望对你有一定的参考价值。
怎么给字符串字段加索引
Hi,我是阿昌,今天学习记录的是关于怎么给字符串字段加索引的内容。
现在,几乎所有的系统都支持邮箱登录,如何在邮箱这样的字段上建立合理的索引。
假设,现在维护一个支持邮箱登录的系统,用户表是这么定义的:
mysql> create table SUser(
ID bigint unsigned primary key,
email varchar(64),
...
)engine=innodb;
由于要使用邮箱登录,所以业务代码中一定会出现类似于这样的语句:
mysql> select f1, f2 from SUser where email='xxx';
如果 email 这个字段上没有索引,那么这个语句就只能做全表扫描。
同时,MySQL 是支持前缀索引的,也就是说,可以定义字符串的一部分作为索引。
默认地,如果创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
比如,这两个在 email 字段上创建索引的语句:
mysql> alter table SUser add index index1(email);
或
mysql> alter table SUser add index index2(email(6));
第一个语句创建的 index1 索引里面,包含了每个记录的整个字符串;
而第二个语句创建的 index2 索引里面,对于每个记录都是只取前 6 个字节。
那么,这两种不同的定义在数据结构和存储上有什么区别呢?
如图 2 和 3 所示,就是这两个索引的示意图。
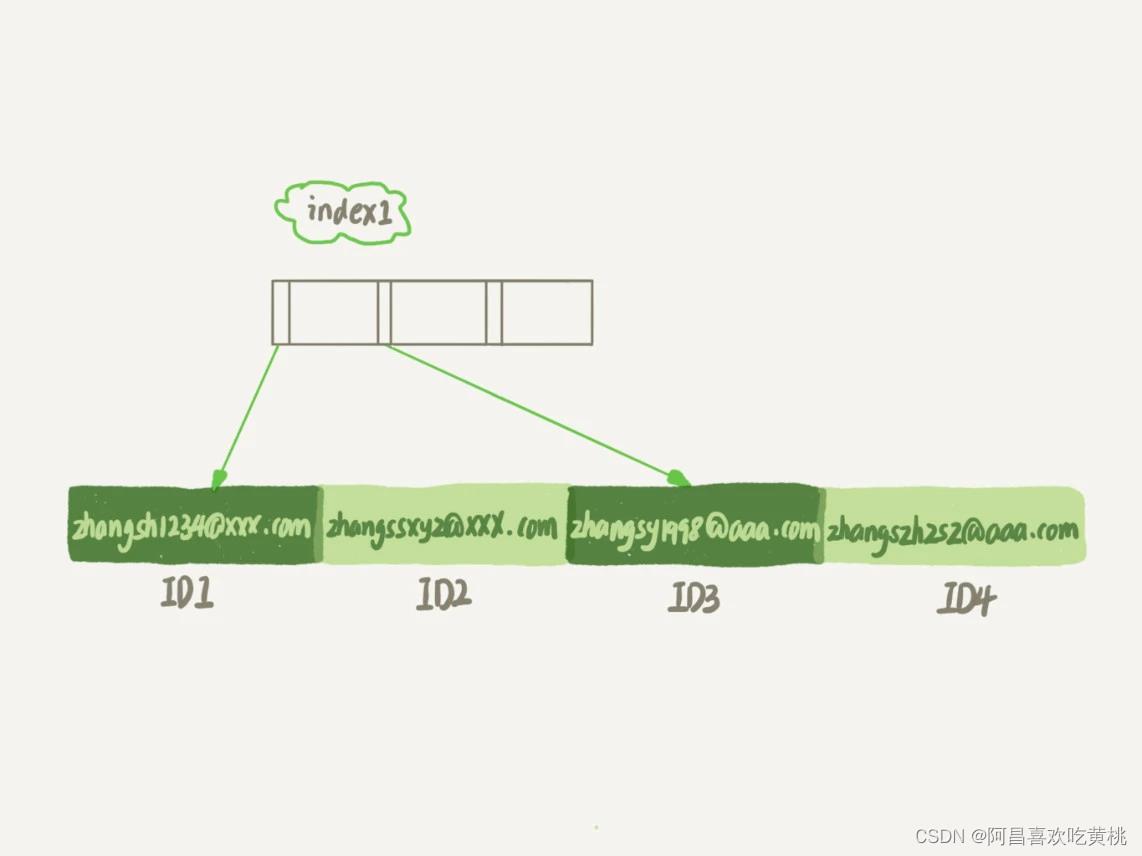
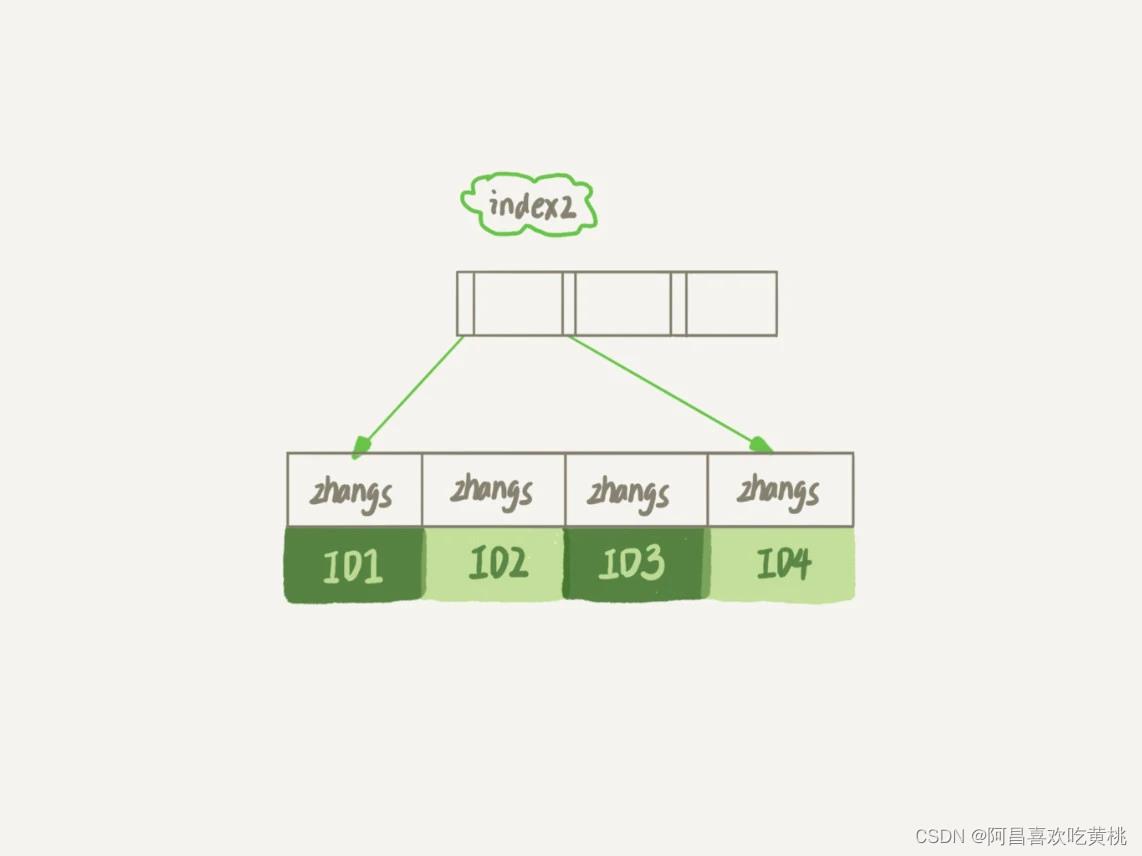
从图中你可以看到,由于 email(6) 这个索引结构中每个邮箱字段都只取前 6 个字节(即:zhangs),所以占用的空间会更小,这就是使用前缀索引的优势。但,这同时带来的损失是,可能会增加额外的记录扫描次数。
下面这个语句,在这两个索引定义下分别是怎么执行的。
select id,name,email from SUser where email='zhangssxyz@xxx.com';
如果使用的是 index1(即 email 整个字符串的索引结构),执行顺序是这样的:
- 从 index1 索引树找到满足索引值是’zhangssxyz@xxx.com’的这条记录,取得 ID2 的值;
- 到主键上查到主键值是 ID2 的行,判断 email 的值是正确的,将这行记录加入结果集;
- 取 index1 索引树上刚刚查到的位置的下一条记录,发现已经不满足 email='zhangssxyz@xxx.com’的条件了,循环结束。
这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
如果使用的是 index2(即 email(6) 索引结构),执行顺序是这样的:
- 从 index2 索引树找到满足索引值是’zhangs’的记录,找到的第一个是 ID1;
- 到主键上查到主键值是 ID1 的行,判断出 email 的值不是’zhangssxyz@xxx.com’,这行记录丢弃;
- 取 index2 上刚刚查到的位置的下一条记录,发现仍然是’zhangs’,取出 ID2,再到 ID 索引上取整行然后判断,这次值对了,将这行记录加入结果集;
- 重复上一步,直到在 idxe2 上取到的值不是’zhangs’时,循环结束。
在这个过程中,要回主键索引取 4 次数据,也就是扫描了 4 行。
通过这个对比,你很容易就可以发现,使用前缀索引后,可能会导致查询语句读数据的次数变多。但是,对于这个查询语句来说,如果你定义的 index2 不是 email(6) 而是 email(7),也就是说取 email 字段的前 7 个字节来构建索引的话,即满足前缀’zhangss’的记录只有一个,也能够直接查到 ID2,只扫描一行就结束了。
也就是说使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
于是,就有个问题:当要给字符串创建前缀索引时,有什么方法能够确定我应该使用多长的前缀呢?
实际上,在建立索引时关注的是区分度,区分度越高越好。因为区分度越高,意味着重复的键值越少。
因此,可以通过统计索引上有多少个不同的值来判断要使用多长的前缀。
首先,可以使用下面这个语句,算出这个列上有多少个不同的值:
mysql> select count(distinct email) as L from SUser;
然后,依次选取不同长度的前缀来看这个值,比如要看一下 4~7 个字节的前缀索引,可以用这个语句:
mysql> select
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from SUser;
当然,使用前缀索引很可能会损失区分度,所以需要预先设定一个可以接受的损失比例,比如 5%。
然后,在返回的 L4~L7 中,找出不小于 L * 95% 的值,假设这里 L6、L7 都满足,就可以选择前缀长度为 6。
一、前缀索引对覆盖索引的影响
前面说了使用前缀索引可能会增加扫描行数,这会影响到性能。
其实,前缀索引的影响不止如此,再看一下另外一个场景。
先来看看这个 SQL 语句:
select id,email from SUser where email='zhangssxyz@xxx.com';
与前面例子中的 SQL 语句
select id,name,email from SUser where email='zhangssxyz@xxx.com';
相比,这个语句只要求返回 id 和 email 字段。
所以,如果使用 index1(即 email 整个字符串的索引结构)的话,可以利用·覆盖索引·,从 index1 查到结果后直接就返回了,不需要回到 ID 索引再去查一次。
如果使用 index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
即使将 index2 的定义修改为 email(18) 的前缀索引,这时候虽然 index2 已经包含了所有的信息,但 InnoDB 还是要回到 id 索引再查一下,因为系统并不确定前缀索引的定义是否截断了完整信息。
也就是说,使用前缀索引就用不上覆盖索引对查询性能的优化了,这也是你在选择是否使用前缀索引时需要考虑的一个因素。
二、其他方式
对于类似于邮箱这样的字段来说,使用前缀索引的效果可能还不错。
但是,遇到前缀的区分度不够好的情况时,我们要怎么办呢?
比如,国家的身份证号,一共 18 位,其中前 6 位是地址码,所以同一个县的人的身份证号前 6 位一般会是相同的。
假设维护的数据库是一个市的公民信息系统,这时候如果对身份证号做长度为 6 的前缀索引的话,这个索引的区分度就非常低了。
按照前面说的方法,可能需要创建长度为 12 以上的前缀索引,才能够满足区分度要求。
但是,索引选取的越长,占用的磁盘空间就越大,相同的数据页能放下的索引值就越少,搜索的效率也就会越低。
那么,如果能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?
这种方法,既可以占用更小的空间,也能达到相同的查询效率。
答案是,有的。
第一种方式是使用倒序存储。
如果存储身份证号的时候把它倒过来存,每次查询的时候,可以这么写:
mysql> select field_list from t where id_card = reverse('input_id_card_string');
由于身份证号的最后 6 位没有地址码这样的重复逻辑,所以最后这 6 位很可能就提供了足够的区分度。
当然了,实践中不要忘记使用 count(distinct) 方法去做个验证。
第二种方式是使用 hash 字段。
可以在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc);
然后每次插入新记录的时候,都同时用 crc32() 这个函数得到校验码填到这个新字段。
由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
mysql> select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
这样,索引的长度变成了 4 个字节,比原来小了很多。
再一起看看使用
倒序存储和使用hash 字段这两种方法的异同点。
首先,它们的相同点是,都不支持范围查询。
倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经没有办法利用索引方式查出身份证号码在[ID_X, ID_Y]的所有市民了。同样地,hash 字段的方式也只能支持等值查询。
它们的区别,主要体现在以下三个方面:
- 从占用的额外空间来看
倒序存储方式在主键索引上,不会消耗额外的存储空间,hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
- 在 CPU 消耗方面
倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,hash 字段的方式需要额外调用一次 crc32() 函数。
如果只从这两个函数的计算复杂度来看的话,reverse 函数额外消耗的 CPU 资源会更小些。
- 从查询效率上
- 使用
hash 字段方式的查询性能相对更稳定一些。因为crc32 算出来的值虽然有冲突的概率,但是概率非常小,可以认为每次查询的平均扫描行数接近 1。 倒序存储方式毕竟还是用的前缀索引的方式,也就是说还是会增加扫描行数。
- 使用
三、总结
字符串字段创建索引的场景可以使用的方式有:
- 直接创建完整索引,这样可能比较
占用空间; - 创建前缀索引,
节省空间,但会增加查询扫描次数,并且不能使用覆盖索引; - 倒序存储,再创建前缀索引,用于
绕过字符串本身前缀的区分度不够的问题,不支持范围扫描; - 创建 hash 字段索引,
查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不支持范围扫描。
在实际应用中,你要根据业务字段的特点选择使用哪种方式。
如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号 @gmail.com", 而学号的规则是:
十五位的数字
- 其中前三位是所在城市编号
- 第四到第六位是学校编号
- 第七位到第十位是入学年份
- 最后五位是顺序编号
系统登录的时候都需要学生输入登录名和密码,验证正确后才能继续使用系统。就只考虑登录验证这个行为的话,怎么设计这个登录名的索引呢?
首先排除全部索引,占空间,其次排除前缀索引,区分度不高,再排除倒序索引,区分度还没前缀索引高。
最后hash索引适合,而且只是登录检验,不需要范围查询。
以上是关于Day875.怎么给字符串字段加索引 -MySQL实战的主要内容,如果未能解决你的问题,请参考以下文章