元数据系统设计理论与实践
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了元数据系统设计理论与实践相关的知识,希望对你有一定的参考价值。
本文首发微信公众号:码上观世界
在大数据架构中,从数据生产、加工到数据消费,每个环节都涉及到元数据的共享和交换,比如数据库,数据表,表结构、存储格式、ETL任务配置、运行记录、操作日志等,由于这些信息分布在不同的系统,既有OLTP系统,又有OLAP系统,这些系统之间并没有统一的企业标准,导致IT在进行系统集成时面临较大挑战,甚至用户自己也无法寻找需要的数据,并对数据的来源、含义、质量、可信度等给出解释。
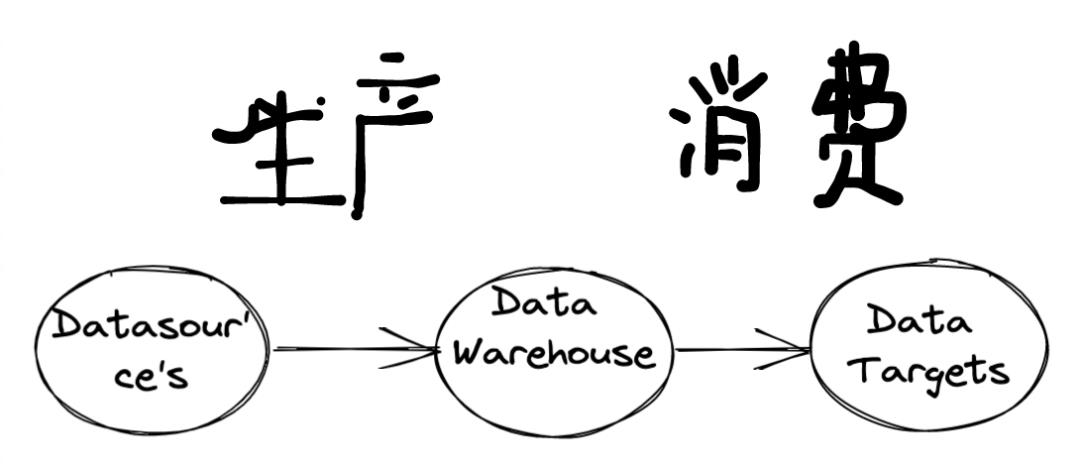
为此,需要一套公共的元数据平台,提供统一的视角进行元数据管理。目前元数据的架构,一般分为集中式架构和分散式架构。集中式的架构,指的是采集多种数据源的元数据到公共元数据系统中存储。分散式的架构,没有自己的元数据存储,而是在使用的时候,即时查询其他数据源的元数据。
这两种架构各有利弊:
集中式的架构,可以快速的检索元数据,抽取的时候,可以自由的转换,自定义补充,提升了元数据的质量;同时也有缺点,需要保证自身存储和其他源数据的一致性,增加了流程复杂度和工作量。
分散式架构的优点是,元数据总能够保持最新,查询更加的简单;缺点也很明显,无法自定义或修改元数据项,查询也受源系统可用性的影响。
元数据系统设计涉及到元数据建模、元数据存储、元数据应用等方面,本文关注最底层核心的部分-元模型设计,同时介绍元数据获取经历的几个阶段所采用的的实现方式。
01
元模型理论
如果采用集中式架构,则首先解决元数据建模问题。元数据建模通过统一的标准和规范解决通用性和扩展性问题,其理论来源于OMG(Object Management Group )定义的元模型规范,OMG将元数据从数据对象开始逐层抽象建模,依次为:
数据(Data):初始数据、物理世界中存在的原始数据,记为M0;
元数据(Metadata):定义数据的数据,也称为Model,记为M1;
元-元数据(Meta-metadata ):定义元数据的数据,也称为Metamodel,记为M2;
元-元-元数据(Meta-metametadata ):定义元模型数据,也称为Meta-Metamodel,记为M3。
各层次的示例用表格列举下:
Meta-Level | Modeling Level | Examples |
M3 | Meta-Metamodel/Meta-metametadata | MOF Class, Attribute, Association,Package, Operation |
M2 | Metamodel/Meta-metadata | UML Class, Attribute CWM Table, Column |
M1 | Model/Metadata | Product : TableProduct Type : Column |
M0 | Data/Object | "Toaster""Television""Stereo" |
其中M3、M2属于语言规范层,M3层的元模型是为定义下层的模型,该层只有一种元模型,即MOF。MOF(Meta Object Facility,元对象设施)标准是一个模型驱动的分布式对象框架,是OMG关于元模型和元数据库的标准;MOF为构建模型和元模型提供了可扩展的框架,并提供了存取元数据的程序接口。由于M3层具有自描述性,可以递归定义自身,所以往上就没有必要再加层次了。
M2层相对M3更为具体,但仍然属于抽象层,用于定义模型层,该层包含多个元模型:UML、CWM(Common Warehouse Metamodel)。CWM规范基于UML(Unified Modeling Language)、MOF(Meta Object Facility)和XMI(XML Metadata Interchange) 这三个核心标准实现了对元数据的定义(设计)、交换(交 互)、存储、存取(操作)等,为元数据管理提供全面能力支持。
M1层属于用户规范层,用于定义数据层。数据层的数据可通过M1层动态构建。上述各模型组成了如下的层次结构:
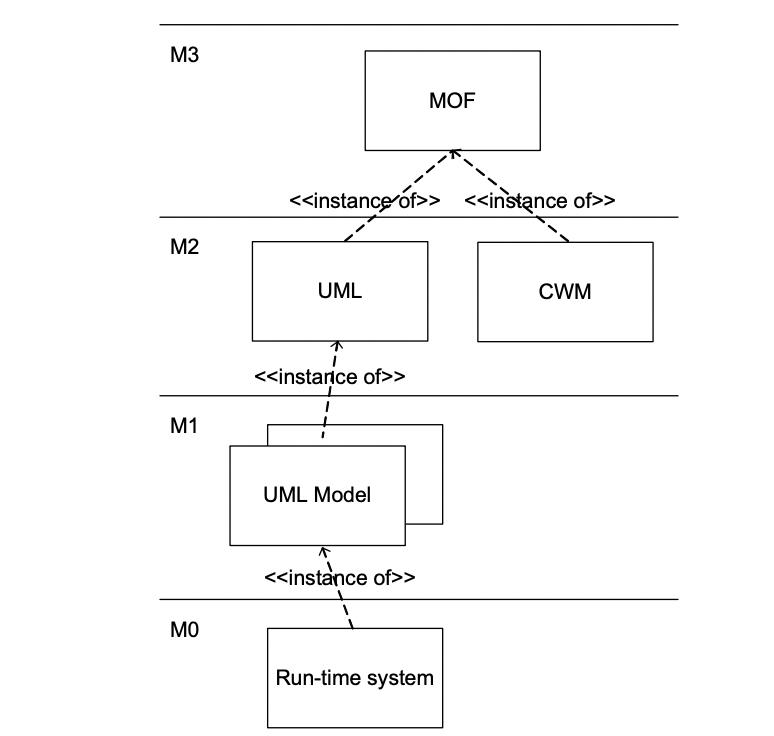
上述模型架构理解起来非常困难,需要从底层数据逐层抽象,相当于在脑海中逐层挤压多余的水分,层次越高,水分越少,最上层都是干货,从上层到下层理解的过程相当于不断加水稀释。在实践中,这篇文章中,我也不打算详细介绍,感兴趣的同学可以参考以下内容:
MOF规范、案例的详细参考:
https://essay.utwente.nl/57286/1/scriptie_Overbeek.pdf
CWM 缘由、规范、设计基础参考:
https://cwmforum.org/cwm.pdf
元模型理论给实践提供了参考来源,实践中也不一定完全照搬实现,接下来我从几个实践案例来介绍相关的元模型设计。
02
Hive Metastore 元模型设计
Hive Metastore 大家比较熟悉,它通过规范化的关系对象定义元数据的存储方式,比如库、表、列、参数、序列化等信息,在物理层模型中,我们可以很直观的看到这些信息,比如下面列举的一些信息:
表名称 | 表描述 |
CTLGS | Catalog数据表 |
DBS | DataBase数据表 |
TBLS | Table数据表 |
COLUMNS_V2 | 存储字段信息,通过CD_ID与其他表关联 |
DATABASE_PARAMS | DataBase参数数据表 |
TABLE_PARAMS | Table参数数据表 |
SDS | 存储输入输出format等信息,包括表的format和分区的format。关联字段CD_ID,SERDE_ID |
SD_PARAMS | SDS参数数据表 |
SERDES | 存储序列化反序列化使用的类 |
SERDE_PARAMS | 序列化反序列化相关信息,通过SERDE_ID关联 |
这些表通过ER图,也能够直观的看到它们的引用关联关系,比如以HMS2.x版本为例来看:
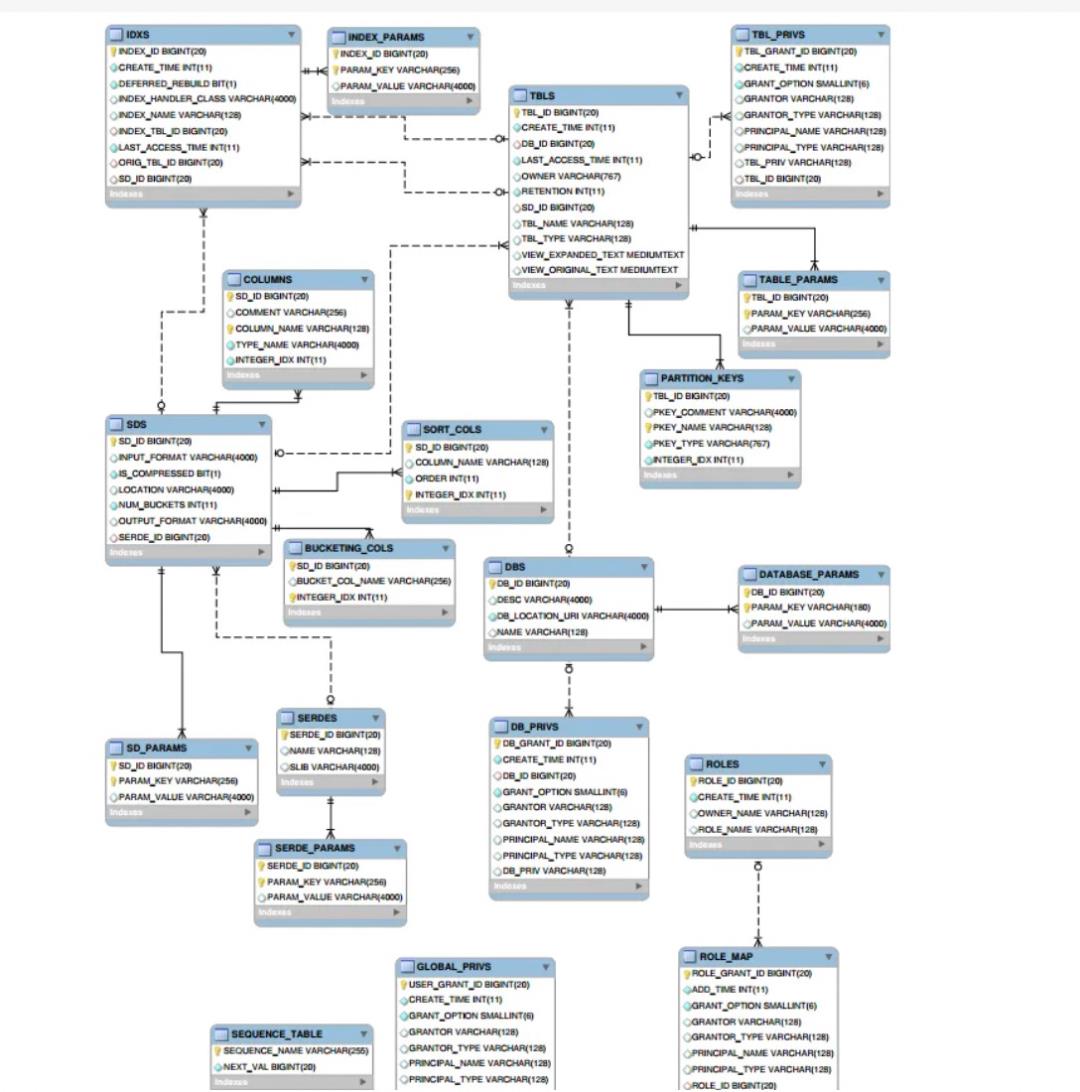
上述信息大致对应了元模型理论中的M2元模型在物理层的实现。
03
Atlas 元模型设计
类型系统是Atlas中的核心系统之一,是一个提供给用户定义和管理类型与实体的组件。所有Atlas中可管理的、立即可用的元数据对象都是由特定类型模型下的实体开描述的。
在Atlas中“类型”是对一个特定类别元数据对象如何存储和访问的定义。一个类型描述了一项属性或一组属性集合,而这些属性定义了元数据对象所包含的内容。有开发背景的用户可将类型类比理解为面向对象编程语言中的类,或者是关系型数据库中的表模式(table schema)。
下面是在Atlas中定义的一个名为Hive表的类型,该类型包含了以下的属性:
Name: hive_table
TypeCategory: Entity
SuperTypes: DataSet
Attributes:
name: string
db: hive_db
owner: string
createTime: date
lastAccessTime: date
comment: string
retention: int
sd: hive_storagedesc
partitionKeys: array<hive_column>
aliases: array<string>
columns: array<hive_column>
parameters: map<string,string>
viewOriginalText: string
viewExpandedText: string
tableType: string
temporary: boolean上述示例的关键点:
Atlas中每一个类型都通过唯一的名字来标识。
每一个类型都有一个元类型(metatype)。Atlas有如下的元类型:
1.基本元类型:boolean, byte, short, int, long, float, double, biginteger, bigdecimal, string, date
2.枚举元类型(Enum metatypes)
3.集合元类型:array, map
4.复合元类型:Entity, Struct, Classification, Relationship
Entity & Classification可以继承其他类型,被继承的类型称为supertype。这样做的好处是,类型可以继承获得超类型的属性。建模者可以将一些公共属性定义在超类型中。比如示例中hive表就是继承自DataSet。
具有‘Entity’, ‘Struct’, ‘Classification’ or 'Relationship'元类型的类型可拥有一个属性集合。其中每一项属性都有一个名词及与之对应的取值。属性可通过表达式type_name.attribute_name来引用。比如hive_table.name是String,hive_table.aliases是String数组,hive_table.db引用了hive_db类型的一个实例
Atlas中的一个“实体”是一个实体类型的特殊值或实例,也表征了真实世界中的元数据对象。类比面向对象编程语言,一个实例是特定类的一个对象。
一个Hive表的实例就是一个实体。假设在“default”数据库中有个名为“customers”的hive表。该表就是hive表类型的一个实体。
guid: "9ba387dd-fa76-429c-b791-ffc338d3c91f"
typeName: "hive_table"
status: "ACTIVE"
values:
name: “customers”
db: "guid": "b42c6cfc-c1e7-42fd-a9e6-890e0adf33bc", "typeName": "hive_db"
owner: “admin”
createTime: 1490761686029
updateTime: 1516298102877
comment: null
retention: 0
sd: "guid": "ff58025f-6854-4195-9f75-3a3058dd8dcf", "typeName": "hive_storagedesc"
partitionKeys: null
aliases: null
columns: [ "guid": ""65e2204f-6a23-4130-934a-9679af6a211f", "typeName": "hive_column" , "guid": ""d726de70-faca-46fb-9c99-cf04f6b579a6", "typeName": "hive_column" , ...]
parameters: "transient_lastDdlTime": "1466403208"
viewOriginalText: null
viewExpandedText: null
tableType: “MANAGED_TABLE”
temporary: false以上示例中的要点:
每一个实体类型的实例都有一个唯一标识,即GUID。该GUID是在(元数据)对象定义时由Atlas服务生成,并且在该对象的生命周期内以常量方式保存。任何时刻,我们都能用GUID来访问这个对象。
一个实体实例的values是一个map,该map的key为对应类型中定义属性的名称,value为属性的取值。
属性的取值必须与类型中定义的属性类型保持一致。实体类型(Entity-type)的属性拥有一个AtlasObjectId类型的取值。
实体(Entity)与结构(Struct)元类型都是由其他类型属性组合而成。然而,实例类型的实例拥有一个标识(GUID值),可以被其他实例引用(比如hive_db实体引用hive_table实体)。结构类型没有标识。结构类型的值是所有属性的集合。
而属性拥有以下的内容:
name: string,
typeName: string,
isOptional: boolean,
isIndexable: boolean,
isUnique: boolean,
cardinality: enumname - 属性的名称。
typeName - 属性的元类型名称。
isComposite - 这个标识了建模的考虑。如果一个属性被标记为复合的(composite),那么就表明这个属性不能脱离包含它的实体而存在。比如一个hive表的字段不能脱离表存在。一个复合属性必须在Atlas与包含的实体一起创建。
isIndexable - 标识是否在该属性上建立了索引
isUnique - 是否时唯一索引。任何标记设置为真的属性,都可以作为区分实体的主键。
multiplicity - 值是该属性是必须的,可选的,多值的其中之一。
如果isOptional=true,那么创建表实体时必须可以引用到db实体
db:
"name": "db",
"typeName": "hive_db",
"isOptional": false,
"isIndexable": true,
"isUnique": false,
"cardinality": "SINGLE"注意到列属性定义中的ownedRef约束。这使得我们在定义列实体必须与对应的表实体绑定起来。
columns:
"name": "columns",
"typeName": "array<hive_column>",
"isOptional": optional,
"isIndexable": true,
“isUnique": false,
"constraints": [ "type": "ownedRef" ]上面通过示例介绍了Entity类型,除此之外,Atlas还有以下重要的类型,包括:
Referenceable:该类型表示,它的所有实体都可以通过叫做qualifiedName的唯一属性查询到。
Asset: 该类型扩展自Referenceable,并增加了诸如name,description和owner等属性。name是必选属性,其他为可选属性。提供Referenceable和Asset的目的是,让建模者在定义和查询他们自定义类型时能具备强一致性。具有这些固定的属性集,能让应用和用户接口开发时有这样的属性假设,即默认这些属性已经才能在。
Infrastructure:该类型扩展自Asset,一般可作为基础上设施元数据对象(如集群,主机等)的公用超类型。
DataSet:该类型扩展自Referenceable。概念上,它用于描述一种存储数据的类型。在Atlas中,hive表,hbase表等都可以从DataSet扩展而来。从DataSet类型扩展而来的类型都将拥有一个模式(schema),即有一个属性定义了该数据集的列(字段或属性),比如hive表中columes字段。所有DataSet扩展类型的实体都会参与数据转换(transformation),而这种转换会通过Atlas的血缘图记录下来。
Process:该类型扩展自Asset。概念上,它用于描述任何数据转换的操作。例如,一个ETL处理过程可以是Process扩展类型的实例,而该ETL处理过程可将原始数据转换成存储到一个存放聚合数据的hive表中。Process类型有两个特别的属性,输入和输出。输入和输出都是DataSet实例数组类型的。因此,一个Process类型的实例可用输入和输出属性来展示数据的血缘关系。
关于Atlas的更多内容参考:
https://atlas.apache.org/#/TypeSystem
04
DataHub 元模型设计
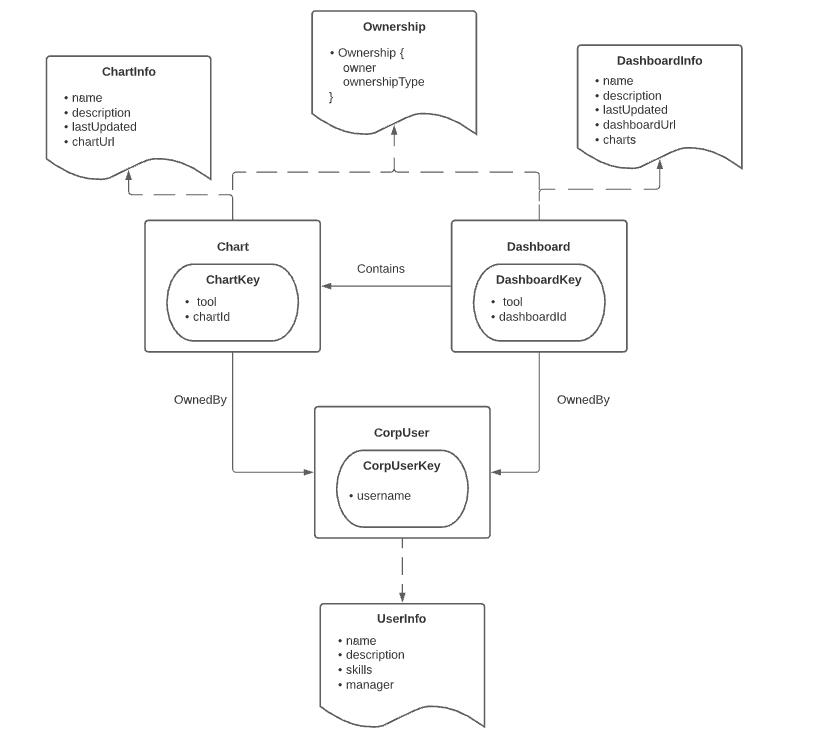
DataHub 元模型基于以下几个抽象来实现:
Entities:实体。比如用户、图表Chart、Dataset、Dashboard、DataJob等,实体有自己的唯一标识符,实体通过唯一标识符关联一系列属性信息;
Aspects:描述实体的部分属性。切面可以独立更新,它是DataHub写入的最小原子单位。切面可以跨多个实体存在,比如在多个有”ownership“属性的实体上定义名叫 Ownership的切面,那么该切面就可以被这多个实体重用。
Relationships:实体跟实体之间的关系。类似数据库的外键引用。关系允许双向遍历。
Identifiers(Keys & Urns):查询实体的标识符。其中Keys是一种特殊的切面,Keys可以序列化到字符串形式的Urns,Urns 也可以转换回Keys,而Urns是一种对用户查询实体更友好的方式。
通过一个示例来看DataHub 元模型,比如下图中包含 3 个实体:CorpUser、Char、Dashboard, 2 个关系:OwnedBy、Contains,3 个元数据切面:Ownership、ChartInfo、DashboardInfo。
关于DataHub的更多内容可参考:
https://datahubproject.io/docs/metadata-modeling/metadata-model/
05
元数据采集
元数据的采集方式,从发展过程划分为3代。
1. G1 基于Pull的方式。
此时的元数据服务很简单,只需要一个存储元数据的数据库以及搜素引擎即可。其元数据来源于ETL过程,ETL从数据源,如关系数据库,非结构存储的文件等中获取元数据。
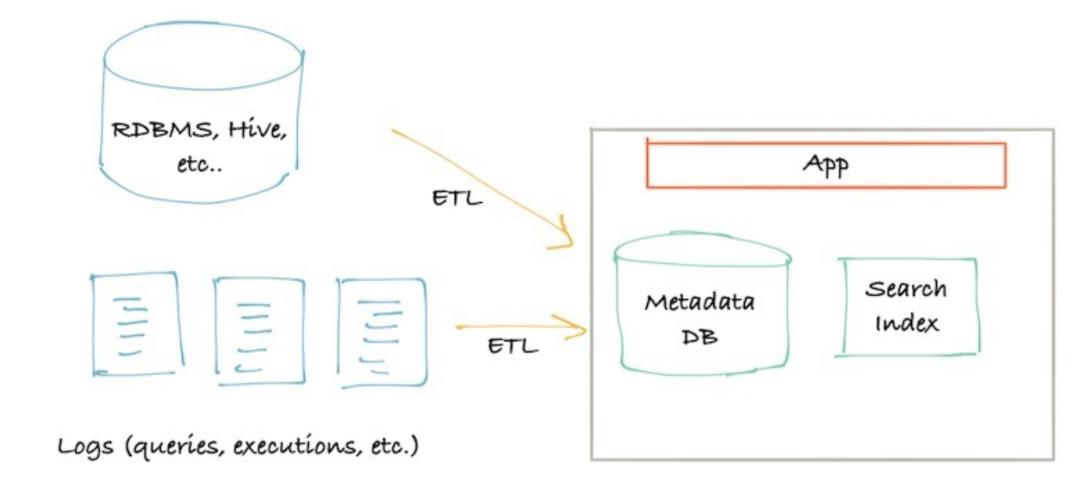
这种方式实现起来简洁直观,不需要多太多事情。但是缺点很明显:
容易影响在线系统;
外部数据源的响应能力与可靠性无法保证;
元数据新鲜度和系统负载不好权衡。
2. G2基于Push的方式
为避免G1中Pull的方式的缺点,G2在原来存储的基础上,增加元服务,提供元数据存取的API,外部数据源通过Push的方式上传元数据。
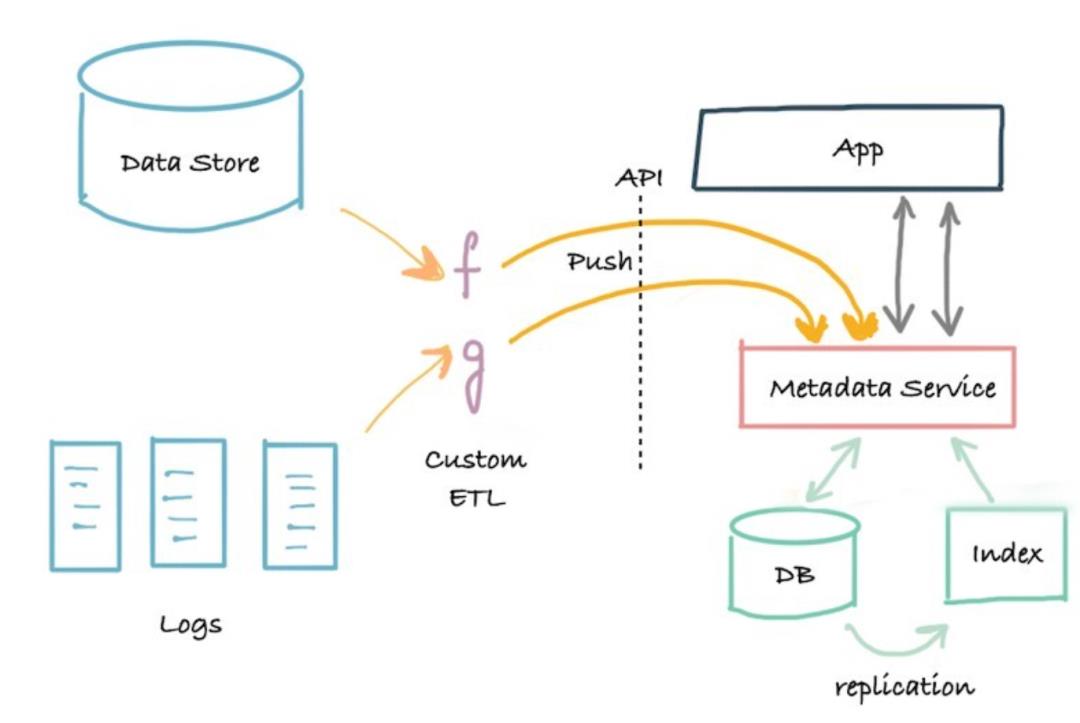
相比G1,G2可以随时响应Push请求,很好的平衡了元数据的采集及时性和系统负载。但G2也存在较大问题:
不能订阅元数据变更日志;
单体元数据服务过于集中,所有对元数据的存取需求都集中到该服务,无法支撑跨团队开发。
3. G3 基于事件的方式
G3的出现主要解决G2中存在的元数据服务过于集中,无法及时响应多场景应用开发的情形,引入事件机制,将元数据的获取和应用解耦:
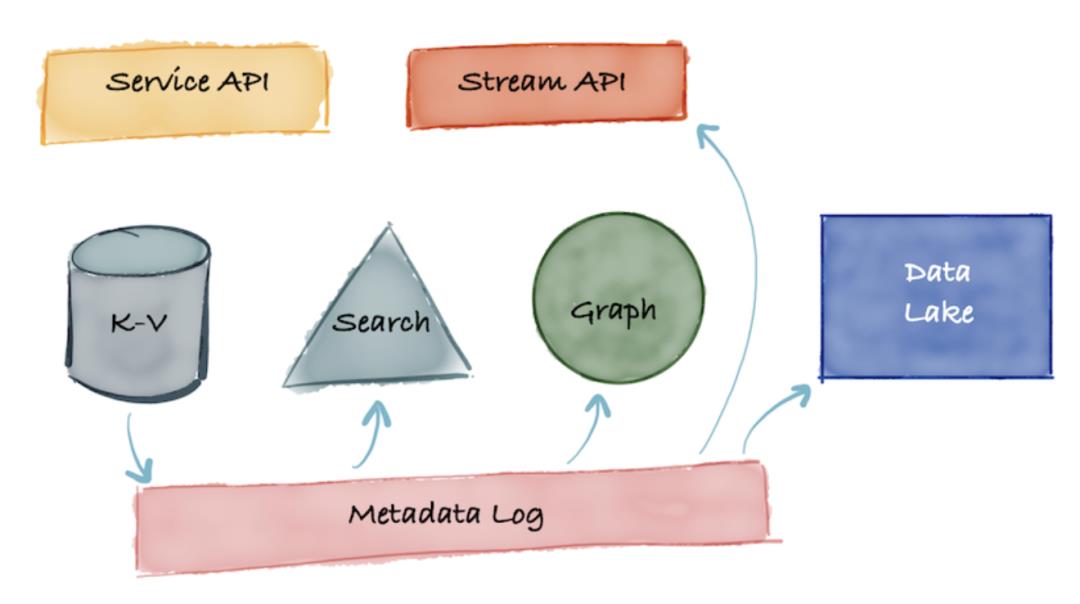
比如基于Kafka 等系统 暂存 Metadata log,下游使用方都可以同时订阅和处理元数据变更日志,比如下游应用方可以将变更日志解析后存储到在线 K-V系统,或者导入在线搜索系统或者图引擎或者流式API以及同步到数据湖中以便后续进一步分析处理。
关于元数据采集的更多信息可以参考:
https://engineering.linkedin.com/blog/2020/datahub-popular-metadata-architectures-explained
它详细介绍了元数据系统在LinkIn的发展和设计思考,它有助于理解Datahub背后的设计。
06
尾声
由于篇幅及水平等原因,本文暂写这么多,更多的内容可以参考文章链接,虽然本文主要谈了元数据模型设计和元数据采集,但是基于元数据模型的驱动设计、基于元数据的数据治理以及基于AI的元数据发现等都是很庞大的内容,需要进一步学习和分享。
以上是关于元数据系统设计理论与实践的主要内容,如果未能解决你的问题,请参考以下文章