BEVDistill:Cross-Modal BEV Distillation for Multi-View 3D Object Detection——论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BEVDistill:Cross-Modal BEV Distillation for Multi-View 3D Object Detection——论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:BEVDistill
1. 概述
介绍:基于相机的BEV感知算法可以从周视图像中获取丰富语义信息,但是缺乏深度信息的,对此一些方法中通过深度估计的形式对这部分缺乏的深度信息进行补充,从而实现网络性能的提升。使用深度估计需要添加对应网络模块和标签数据,也会带来不少的工作量。对此,可以从知识蒸馏的角度从Lidar点云数据中去弥补图像中缺失的信息,这篇文章中检测网络的角度探讨了3D检测下的知识蒸馏(核心在于怎么实现不同模态数据的信息蒸馏),给出从BEV特征dense蒸馏和实例蒸馏的方法。
2. 方法实现
2.1 整体方案
在下图中展示了文章方法的整体方案结构图:
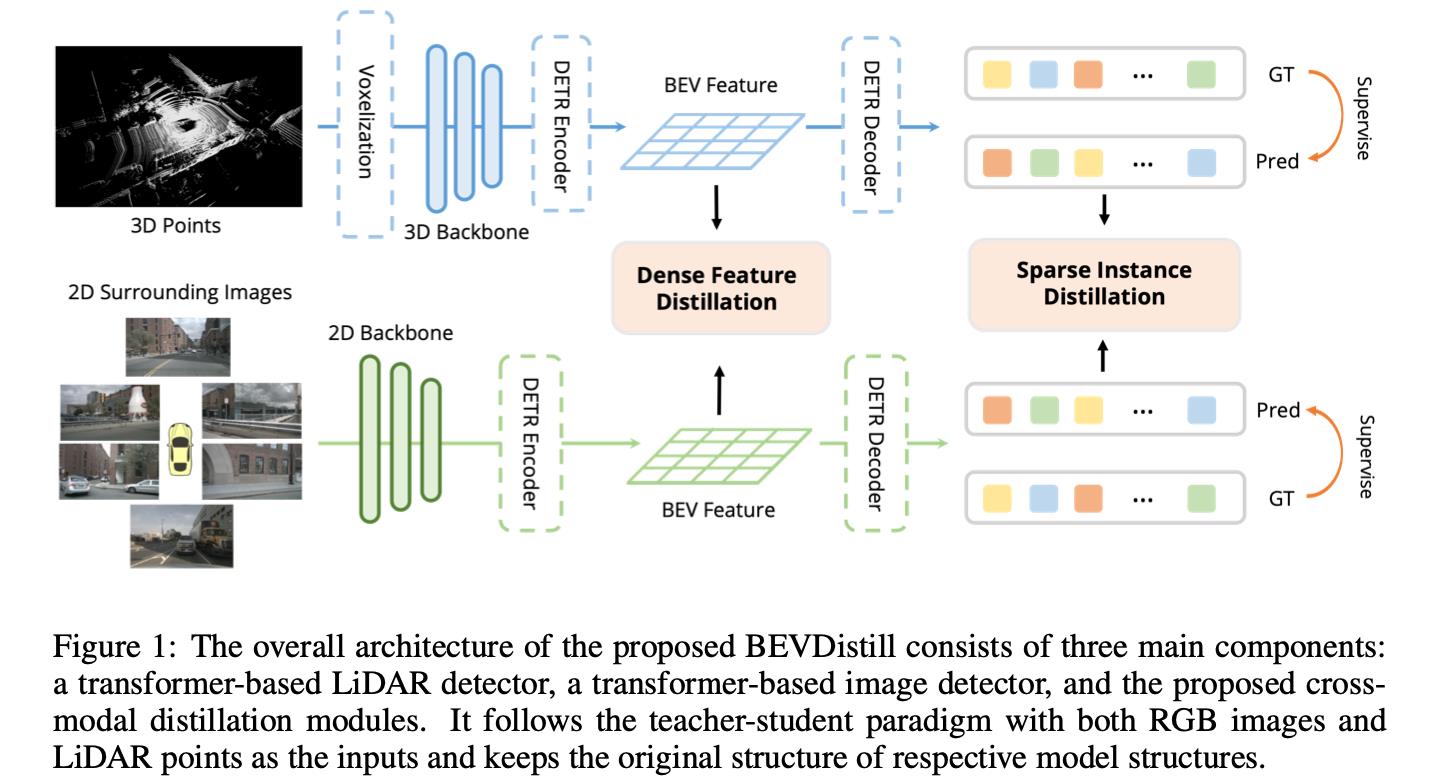
在上图中分别用Lidar和多视图相机构建了对应3D检测算法,并在空间特征对齐的BEV特征下做基于object的dense蒸馏,在检测头中基于匹配做inst级别的稀疏蒸馏。
2.2 基于object BEV的dense蒸馏
这部分对BEV特征的蒸馏是比较具有通用价值的,可以迁移到其它任务场景下去。对于Lidar和相机生成的BEV特征描述为
F
3
D
,
F
2
D
F^3D,F^2D
F3D,F2D,则套用原本的蒸馏方法直接减少对应特征图的差异Loss:
L
f
e
a
t
=
1
H
W
∑
i
H
∑
j
W
∣
∣
F
i
j
3
D
−
F
i
j
2
D
∣
∣
2
L_feat=\\frac1HW\\sum_i^H\\sum_j^W||F_ij^3D-F_ij^2D||_2
Lfeat=HW1i∑Hj∑W∣∣Fij3D−Fij2D∣∣2
但是,由于Lidar和相机之间数据的模态差异较大,直接进行蒸馏会引入很多无关噪声。对此,一种一种解决方案便是在目标区域(object area)上去做特征差异最小化,这里去第
i
i
i个object的中心为
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),则以该中心构造二维高斯分布:
w
i
,
x
,
y
=
e
x
p
(
−
(
x
i
−
x
^
i
)
2
+
(
y
i
−
y
^
i
)
2
2
σ
i
2
)
w_i,x,y=exp(-\\frac(x_i-\\hatx_i)^2+(y_i-\\haty_i)^22\\sigma_i^2)
wi,x,y=exp(−2σi2(xi−x^i)2+(yi−y^i)2)
对于上述高斯分布会在不同object上存在重叠的情况,那么重叠部分去最大值参与后续计算,也就是描述为:
L
f
e
a
t
=
1
H
W
⋅
∑
m
a
x
(
w
i
j
)
∑
i
H
∑
j
W
m
a
x
(
w
i
j
∣
∣
F
i
j
3
D
−
F
i
j
2
D
∣
∣
2
)
L_feat=\\frac1HW\\cdot\\sum max(w_ij)\\sum_i^H\\sum_j^Wmax(w_ij||F_ij^3D-F_ij^2D||_2)
Lfeat=HW⋅∑max(wij)1i∑Hj∑Wmax(wij∣∣Fij3D−Fij2D∣∣2)
2.3 基于inst的稀疏蒸馏
这部分的蒸馏涉及到了具体的预测实例,对于teacher网络输出的分类和检测框结果为
c
i
T
,
b
i
T
c_i^T,b_i^T
ciT,biT,对于student网络输出的分类和检测框结果为
c
i
S
,
b
i
S
c_i^S,b_i^S
ciS,biS 。那么需要对其进行蒸馏首先就需要完成student和teacher网络结果的匹配:
σ
^
=
arg min
∑
i
N
L
m
a
t
c
h
(
y
i
,
y
^
i
)
,
L
m
a
t
c
h
(
y
i
,
y
^
i
)
=
−
l
o
g
c
σ
(
i
)
S
(
c
i
T
)
+
∣
∣
b
i
T
,
b
σ
(
i
)
S
∣
∣
1
\\hat\\sigma=\\argmin \\sum_i^NL_match(y_i,\\haty_i),\\ L_match(y_i,\\haty_i)=-logc_\\sigma(i)^S(c_i^T)+||b_i^T,b_\\sigma(i)^S||_1
σ^=argmini∑NLmatch(yi,y^i), Lmatch(yi,y^i)=−logcσ(i)S(ciT)+∣∣biT,bσ(i)S∣∣1
上面的匹配过程知识考虑了student和teacher之间的match程度,但是实际的检测质量是未知的,因而这里有必要引入GT来度量匹配重要性,也就是给一个权重因子:
q
i
=
(
c
i
)
γ
⋅
I
O
U
(
b
i
G
T
,
b
i
p
r
e
d
)
1
−
γ
q_i=(c_i)^\\gamma\\cdot IOU(b_i^GT,b_i^pred)^1-\\gamma
qi=(ci)γ⋅IOU(biGT,bipred)1−γ
得到权重因子之后接下来就是去减少对应特征的差异了,也就是减少实例上的Loss:
L
i
n
s
t
=
∑
i
N
−
q
i
(
α
L
c
l
s
(
c
σ
(
i
)
S
,
c
i
T
)
+
β
L
b
o
x
(
b
i
T
,
b
σ
(
i
)
S
)
)
L_inst=\\sum_i^N-q_i(\\alpha L_cls(c_\\sigma(i)^S,c_i^T)+\\beta L_box(b_i^T,b_\\sigma(i)^S))
L