KMM(Kotlin Multiplatform Mobile)Welcome to Kotlin/Native World
Posted Deft_MKJing宓珂璟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KMM(Kotlin Multiplatform Mobile)Welcome to Kotlin/Native World相关的知识,希望对你有一定的参考价值。
1. 什么是Kotlin/Native
Kotlin/Native是一种将Kotlin源码编译成不需要任何VM支持的目标平台二进制数据的技术,编译后的产物可以直接运行在目标平台上,设计Kotlin/Native的目的是支持在非JVM环境下进行编程,如在嵌入式平台和ios环境下,如此一来,Kotlin就可以运行在非JVM平台环境下
1.1 编译器结构
主要包含如下两个组件:
- 1、LLVM 后端编译器
- 2、Kotlin 本地 Runtime 库

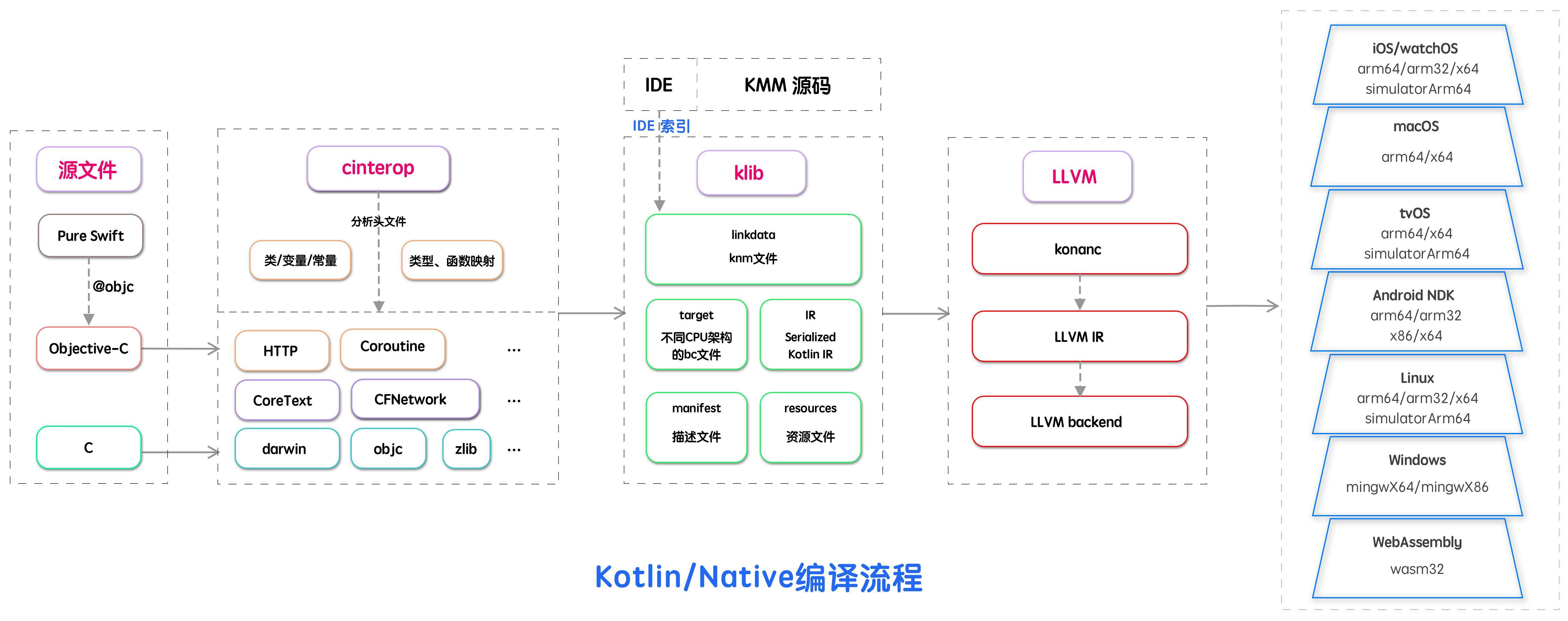
1.2 编译流程
2. 内存管理模型
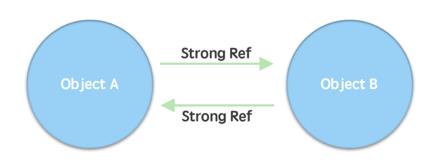
2.1 方案一(完全模仿OC引用计数)
当Kotlin/Native项目在2016年启动时,有必要设计一个内存管理方案。由于Objective-C的互操作性摆在桌面上,官方对那里的自动化内存管理工作方式使用引用计数进行了大量的思考和关注。甚至试验了一种完全模仿该模型的方法,这将提供提供最无缝的配合的好处。 然而,在Objective-C生态系统中,带有循环的对象图并不是由运行时自动管理的。程序员必须识别循环引用,并在源代码中以一种特殊的方式标记它们。
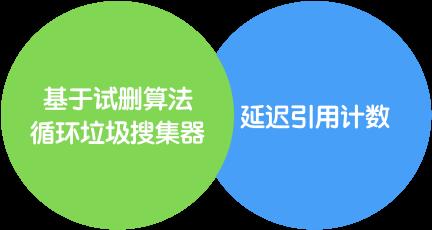
2.2 方案二(外加试删算法的循环垃圾收集器)
方案一与Kotlin的核心理念Making Development More Engoyable产生了强烈的冲突。Kotlin确实要求开发者在为了安全而需要这种精确性的地方更加明确,但在这些额外的代码只是可以由语言管理的样本模板的地方就不需要了。不过,引用计数内存管理器的编写还是很容易让Kotlin/Native项目开始的,并且加入了一个基于试删算法的循环垃圾收集器,以提供Kotlin程序员所期望的开发体验。
问题: 随着Kotlin/Native项目的成熟和广泛采用,这种基于引用计数的自动化内存管理方案的局限性开始变得更加明显。首先,对于内存分配密集型的应用,很难获得高吞吐量。但是,虽然性能很重要,但它并不是Kotlin设计的唯一因素。但是如果再把多线程和并发扔进去的时候,局限性就会变得更严重(CPU密集型操作如果在主线程就会影响用户体验)。
3. 异步并发模型
3.1 Kotlin/JVM 异步并发模型
kotlin/JVM 提供了通过编译器与线程池实现的协程来完成异步并发任务
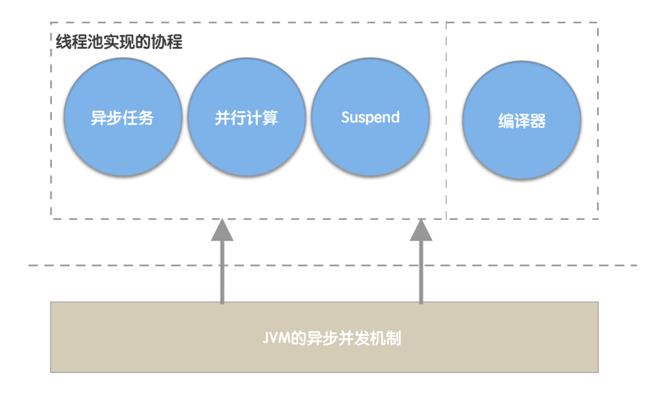
当并发竞争出现的时候,这套机制只需将协程挂起而无需阻塞线程,而对于是否发生竞争的判断可以转移到原子操作上。这样的机制避免了 JVM重量级锁的出现,个人认为也是 Kotlin/JVM 的协程相对于传统 JDK 中异步并发 API 的一个优势
3.2 Kotlin/Native 异步并发模型
没有了JVM作为基础,必须重新实现。由于 Kotlin 在编程范式上吸收了部分函数式编程的特性,因此 Kotlin/Native 的同步方案从设计思想上向函数式编程靠拢,即对象不变性,其宗旨就是如果对象本身不可变,那就不存在线程安全的问题
1、Mutable state == 1 thread
2、Immutable state == many thread
3.3 异步并发方案
1)基于宿主环境(操作系统)实现。例如与使用 POSIX C 编写原生程序一样。直接使用相关操作系统平台提供的 API 来自己开启线程,在 POSIX 标准的系统上,手动调用 pthread_create函数来创建线程。但是这样的代码实现违反了平台通用性的原则,可移植性太差。
2)多线程版协程kotlinx-coroutines-mt,如果使用该版本会遇到的问题就是同一份代码在能通过编译的情况下,在 android 端可以正常运行,但在 iOS 端则会 crash。除此之外它还产生了一系列的连带或相关问题包括:
- 协程在 Kotlin/Native 上没有调度器 Dispatchers.IO。
- 协程调度器 Dispatchers.Default 在 Kotlin/JVM 上是线程池实现,而在 Kotlin/Native 上是单后台线程实现(multi-thread 版本)。
- 我们在 Kotlin/Native 上也无法自己编写基于池化技术的协程调度器,因为它可能会因为挂起时与恢复时所在线程不同而 crash。
- 此前协程挂起锁 Mutex 在 Kotlin/Native 上有 bug,无法正常生效(kotlinx.coroutines 1.4.2 版本后已修复)。
3)Worker,Worker 与 Kotlin/Native 的异步并发模型紧密相连,做到了既能利用 CPU 多核能力,又能保障线程安全(虽然做法略微粗暴)。
3.4、Workder方案介绍
什么是Worker
Worker 与线程类似,通过打印线程 id 进行验证发现,一个 Worker 基本对应一个线程。在编写程序时,如果需要开启线程,就应该创建一个 Worker 。Kotlin/Native 对跨线程/Worker 访问对象拥有严格的限制,因此对象在一定维度上又分为两种状态,即 Freeze(冻结)与 Unfreeze(非冻结)。
冻结的对象是编译期即可证明为不可变的对象,或者是手动显式添加 @SharedImmutable 注解的对象,系统默认这类对象不可变,可以在任意的线程/Worker 中访问,而非冻结对象通常不可在创建它之外的线程/Worker 中访问。Kotlin/Native通过给对象生成对象子图(subgraph)的方式,然后在运行时遍历对象子图来检测是否发生了跨线程/Worker 访问。
什么是对象子图
“在我们使用 Worker 的时候, Worker 会将 producer 返回的对象进行包装,生成一个对象子图(subgraph),我们可以将对象子图理解为一个对象,或是将它理解为一个对象头(因为这看起来有点类似在 TCP/IP报文头上添加 HTTP 报文头的感觉),它与原对象相互引用。每次在线程中访问对象的时候,都会通过 O(N) 复杂度的算法来检测该对象是否在多个线程内可见。上面讨论的对象冻结,也是通过对象子图来实现的。”
什么是对象子图分离
对象子图在某些特殊的情况下可以与对象分离,从而让我们可以自由的让对象在多个线程间访问
什么是对象冻结
对象冻结,即一个对象被创建之后即与当前线程/Worker 绑定,在不加特殊标记的情况下,在其他线程/Worker 访问该对象(无论是读还是写)就会抛出异常。但是存在另外一种对象,它们在编译期即可被证明是不可变的,这类对象就被称为冻结的对象。因此冻结对象可以在任意线程内访问,目前冻结对象有:
- 枚举类型
- 不加特殊修饰的单例对象(即使用 object 关键字声明的)
- 所有使用 val 修饰的原生类型变量与 String(这种情况也就包含了 const 修饰的常量)
Kotlin/Native 的异步并发模型受对象子图机制的约束,这与 Kotlin/JVM 可以自由的编写异步并发代码完全不同,对象子图机制可以总结为以下几点:
1)每个对象都与其诞生时所在的线程绑定,一旦在其他线程访问该对象,即监测到该对象的对象子图中记录的线程 id 与当前线程不一致,程序立刻 crash。
2)要在多线程中访问同一个对象,只能将该对象做对象子图分离与重新绑定。
3)冻结对象,冻结对象可以在任意线程访问,但冻结对象不可进行“写”操作,一但进行“写”操作立刻 crash,且冻结对象不可解冻。
Common层定义
/**
* Author: mikejing
* Create On: 2022/2/15 6:39 下午
* Usage: TODO
* Description: TODO
*/
expect class Worker()
fun <T> runBackground(backJob: () -> T): Future<T>
fun requestTermination()
expect class Future<T>
fun consume(): T
sealed class JobResult<out B:Any>
data class Success<out B:Any>(val result: B) : JobResult<B>()
data class Error(val thrown: Throwable) : JobResult<Nothing>()
expect fun <B:Any> Worker.backgroundTask(backJob: () -> B, mainJob: (JobResult<B>) -> Unit)
iOS实现
/**
* Author: mikejing
* Create On: 2022/2/15 6:40 下午
* Usage: TODO
* Description: TODO
*/
actual class Worker actual constructor()
private val worker = kotlin.native.concurrent.Worker.start()
actual fun <T> runBackground(backJob: () -> T): Future<T>
return com.tencent.util.Future(worker.execute(
TransferMode.SAFE,
backJob.freeze() )
it()
)
actual fun requestTermination()
worker.requestTermination().result
actual class Future<T>(private val future: kotlin.native.concurrent.Future<T>)
actual fun consume():T = future.result
actual fun <B:Any> Worker.backgroundTask(backJob: () -> B, mainJob: (JobResult<B>) -> Unit)
val ref = StableRef.create(mainJob).freeze()
runBackground
val result = try
Success(backJob())
catch (t: Throwable)
Error(t)
val pair = Pair(result, ref).freeze()
dispatch_async_f(dispatch_get_main_queue(), DetachedObjectGraph
pair
.asCPointer(), staticCFunction it: COpaquePointer? ->
initRuntimeIfNeeded()
val pair = DetachedObjectGraph<Any>(it).attach() as Pair<JobResult<B>, StableRef<(JobResult<B>) -> Unit>>
val result = pair.first
val stableRef = pair.second
val job = stableRef.get()
stableRef.dispose()
job(result)
)
Android实现
/**
* Author: mikejing
* Create On: 2022/2/15 6:56 下午
* Usage: TODO
* Description: TODO
*/
actual class Worker actual constructor()
private val executor = Executors.newSingleThreadExecutor()
actual fun <T> runBackground(backJob: () -> T): Future<T>
return Future(executor.submit(backJob) as java.util.concurrent.Future<T>)
actual fun requestTermination()
executor.shutdown()
executor.awaitTermination(30, TimeUnit.SECONDS)
actual class Future<T>(private val future: java.util.concurrent.Future<T>)
actual fun consume():T = future.get()
actual fun <B:Any> Worker.backgroundTask(
backJob: () -> B,
mainJob: (JobResult<B>) -> Unit
)
val result = try
Success(backJob())
catch (t: Throwable)
Error(t)
as JobResult<B>
Handler(Looper.getMainLooper()).post
mainJob(result)
更加轻量级,更加适合现有方案
轻量级:轻量级的自定义方案更适合现阶段
低风险:跨平台多线程库各自存在诸多缺点,根据序列化工具经验,尽可能不引入三方库,避免引入库带来未知风险
方便切换:由于Kotlin 1.6后 发布了新内存模型,新的GC进入预览,等待统一多线程方案后,方便快速过渡
3.5、总结
上述有两种方案,都有各自的优缺点,多线程协程的方案官方在不断迭代,可以直接使用,不过会有一些多线程问题,如果遇到了只能等官方修复。Worker就需要自己封装一套高阶API,而且使用条件有严格限制,因此两者在使用之前团队内需要研究和评估。
为什么如此设计?
采用锁的方式来保证并发安全容易出错,因此想把对象跨线程访问的操作全部显式的暴露在编译期,官方的想法是好的,但是效果有点不理想。。。。。。
问题点:
1、对那些习惯于能在多线程中共享数据的开发者无法适应
2、Kotlin 并非纯函数式编程语言,抛弃可变状态不适合UI编程
3、与Kotlin/JVM 差异过大,导致代码复用受阻
4、Current Koltin/Native MM 和 Multi-thread Coroutines 存在内存泄露
5、社区普遍不认可官方设计对象子图机制
总体来说,在混合编程中,多线程是Kotlin/Native中坑最多的地方,也是对开发者最不友好的地方。
3.6、未来
Welcome to the Kotlin/Native world
meikiemi 2022年01月09日 15:05 浏览(173) 收藏(8) 评论(3)
分享
编辑
1、什么是Kotlin/Native
作为一个iOS开发,最近在开发KMM,十分感谢微信读书的lightshou的帮助,感恩~~
Kotlin/Native是一种将Kotlin源码编译成不需要任何VM支持的目标平台二进制数据的技术,编译后的产物可以直接运行在目标平台上,设计Kotlin/Native的目的是支持在非JVM环境下进行编程,如在嵌入式平台和iOS环境下,如此一来,Kotlin就可以运行在非JVM平台环境下
1.1、编译器结构
主要包含如下两个组件:
1、LLVM 后端编译器
2、Kotlin 本地 Runtime 库
1.2、编译流程
2、内存管理模型
2.1 、方案一(完全模仿OC引用技术)
当Kotlin/Native项目在2016年启动时,有必要设计一个内存管理方案。由于Objective-C的互操作性摆在桌面上,官方对那里的自动化内存管理工作方式使用引用计数进行了大量的思考和关注。甚至试验了一种完全模仿该模型的方法,这将提供提供最无缝的配合的好处。 然而,在Objective-C生态系统中,带有循环的对象图并不是由运行时自动管理的。程序员必须识别循环引用,并在源代码中以一种特殊的方式标记它们。
2.2、方案二(外加试删算法的循环垃圾收集器)
方案一与Kotlin的核心理念Making Development More Engoyable产生了强烈的冲突。Kotlin确实要求开发者在为了安全而需要这种精确性的地方更加明确,但在这些额外的代码只是可以由语言管理的样本模板的地方就不需要了。不过,引用计数内存管理器的编写还是很容易让Kotlin/Native项目开始的,并且加入了一个基于试删算法的循环垃圾收集器,以提供Kotlin程序员所期望的开发体验。
问题: 随着Kotlin/Native项目的成熟和广泛采用,这种基于引用计数的自动化内存管理方案的局限性开始变得更加明显。首先,对于内存分配密集型的应用,很难获得高吞吐量。但是,虽然性能很重要,但它并不是Kotlin设计的唯一因素。但是如果再把多线程和并发扔进去的时候,局限性就会变得更严重(CPU密集型操作如果在主线程就会影响用户体验)。
3、异步并发模型
3.1、Kotlin/JVM 异步并发模型
Kotlin/JVM 提供了通过编译器与线程池实现的协程来完成异步并发任务
当并发竞争出现的时候,这套机制只需将协程挂起而无需阻塞线程,而对于是否发生竞争的判断可以转移到原子操作上。这样的机制避免了 JVM重量级锁的出现,个人认为也是 Kotlin/JVM 的协程相对于传统 JDK 中异步并发 API 的一个优势
3.2、Kotlin/Native 异步并发模型
没有了JVM作为基础,必须重新实现。由于 Kotlin 在编程范式上吸收了部分函数式编程的特性,因此 Kotlin/Native 的同步方案从设计思想上向函数式编程靠拢,即对象不变性,其宗旨就是如果对象本身不可变,那就不存在线程安全的问题
1、Mutable state == 1 thread
2、Immutable state == many thread
3.3、异步并发方案
1)基于宿主环境(操作系统)实现。例如与使用 POSIX C 编写原生程序一样。直接使用相关操作系统平台提供的 API 来自己开启线程,在 POSIX 标准的系统上,手动调用 pthread_create函数来创建线程。但是这样的代码实现违反了平台通用性的原则,可移植性太差。
2)多线程版协程kotlinx-coroutines-mt,如果使用该版本会遇到的问题就是同一份代码在能通过编译的情况下,在 Android 端可以正常运行,但在 iOS 端则会 crash。除此之外它还产生了一系列的连带或相关问题包括:
协程在 Kotlin/Native 上没有调度器 Dispatchers.IO。
协程调度器 Dispatchers.Default 在 Kotlin/JVM 上是线程池实现,而在 Kotlin/Native 上是单后台线程实现(multi-thread 版本)。
我们在 Kotlin/Native 上也无法自己编写基于池化技术的协程调度器,因为它可能会因为挂起时与恢复时所在线程不同而 crash。
此前协程挂起锁 Mutex 在 Kotlin/Native 上有 bug,无法正常生效(kotlinx.coroutines 1.4.2 版本后已修复)。
3)Worker,Worker 与 Kotlin/Native 的异步并发模型紧密相连,做到了既能利用 CPU 多核能力,又能保障线程安全(虽然做法略微粗暴)。
3.4、Workder方案介绍
资料来源
什么是Worker
Worker 与线程类似,通过打印线程 id 进行验证发现,一个 Worker 基本对应一个线程。在编写程序时,如果需要开启线程,就应该创建一个 Worker 。Kotlin/Native 对跨线程/Worker 访问对象拥有严格的限制,因此对象在一定维度上又分为两种状态,即 Freeze(冻结)与 Unfreeze(非冻结)。
冻结的对象是编译期即可证明为不可变的对象,或者是手动显式添加 @SharedImmutable 注解的对象,系统默认这类对象不可变,可以在任意的线程/Worker 中访问,而非冻结对象通常不可在创建它之外的线程/Worker 中访问。Kotlin/Native通过给对象生成对象子图(subgraph)的方式,然后在运行时遍历对象子图来检测是否发生了跨线程/Worker 访问。
什么是对象子图
“在我们使用 Worker 的时候, Worker 会将 producer 返回的对象进行包装,生成一个对象子图(subgraph),我们可以将对象子图理解为一个对象,或是将它理解为一个对象头(因为这看起来有点类似在 TCP/IP报文头上添加 HTTP 报文头的感觉),它与原对象相互引用。每次在线程中访问对象的时候,都会通过 O(N) 复杂度的算法来检测该对象是否在多个线程内可见。上面讨论的对象冻结,也是通过对象子图来实现的。”
什么是对象子图分离
对象子图在某些特殊的情况下可以与对象分离,从而让我们可以自由的让对象在多个线程间访问
什么是对象冻结
对象冻结,即一个对象被创建之后即与当前线程/Worker 绑定,在不加特殊标记的情况下,在其他线程/Worker 访问该对象(无论是读还是写)就会抛出异常。但是存在另外一种对象,它们在编译期即可被证明是不可变的,这类对象就被称为冻结的对象。因此冻结对象可以在任意线程内访问,目前冻结对象有:
- 枚举类型
- 不加特殊修饰的单例对象(即使用 object 关键字声明的)
- 所有使用 val 修饰的原生类型变量与 String(这种情况也就包含了 const 修饰的常量)
对象子图分离原理
Kotlin/Native 的异步并发模型受对象子图机制的约束,这与 Kotlin/JVM 可以自由的编写异步并发代码完全不同,对象子图机制可以总结为以下几点:
1)每个对象都与其诞生时所在的线程绑定,一旦在其他线程访问该对象,即监测到该对象的对象子图中记录的线程 id 与当前线程不一致,程序立刻 crash。
2)要在多线程中访问同一个对象,只能将该对象做对象子图分离与重新绑定。
3)冻结对象,冻结对象可以在任意线程访问,但冻结对象不可进行“写”操作,一但进行“写”操作立刻 crash,且冻结对象不可解冻。
参考实现方案一:
现有实现方案二:
更加轻量级,更加适合现有方案
轻量级:轻量级的自定义方案更适合现阶段
低风险:跨平台多线程库各自存在诸多缺点,根据序列化工具经验,尽可能不引入三方库,避免引入库带来未知风险
方便切换:由于Kotlin 1.6后 发布了新内存模型,新的GC进入预览,等待统一多线程方案后,方便快速过渡
3.5、总结
上述有两种方案,都有各自的优缺点,多线程协程的方案官方在不断迭代,可以直接使用,不过会有一些多线程问题,如果遇到了只能等官方修复。Worker就需要自己封装一套高阶API,而且使用条件有严格限制,因此两者在使用之前团队内需要研究和评估。
为什么如此设计?
采用锁的方式来保证并发安全容易出错,因此想把对象跨线程访问的操作全部显式的暴露在编译期,官方的想法是好的,但是效果有点不理想。。。。。。
问题点:
1、对那些习惯于能在多线程中共享数据的开发者无法适应
2、Kotlin 并非纯函数式编程语言,抛弃可变状态不适合UI编程
3、与Kotlin/JVM 差异过大,导致代码复用受阻
4、Current Koltin/Native MM 和 Multi-thread Coroutines 存在内存泄露
5、社区普遍不认可官方设计对象子图机制
总体来说,在混合编程中,多线程是Kotlin/Native中坑最多的地方,也是对开发者最不友好的地方。
3.6、未来
不过这有问题吗,这没有问题,Kotlin 目前的 roadmap 中,新的 GC 将在 1.6 版本进入预览版,1.6.20 版本后进入 stable 状态,届时 Kotlin/Native 的对象子图机制将提供开关以进行关闭,而开发者将通过协程的 Mutex 等机制来保障并发安全。直接重写,那是相当的重视了,大趋势大趋势,松弟们,不要慌,冲冲冲!!!~
核心就是现代跟踪垃圾搜集算法和配套设施
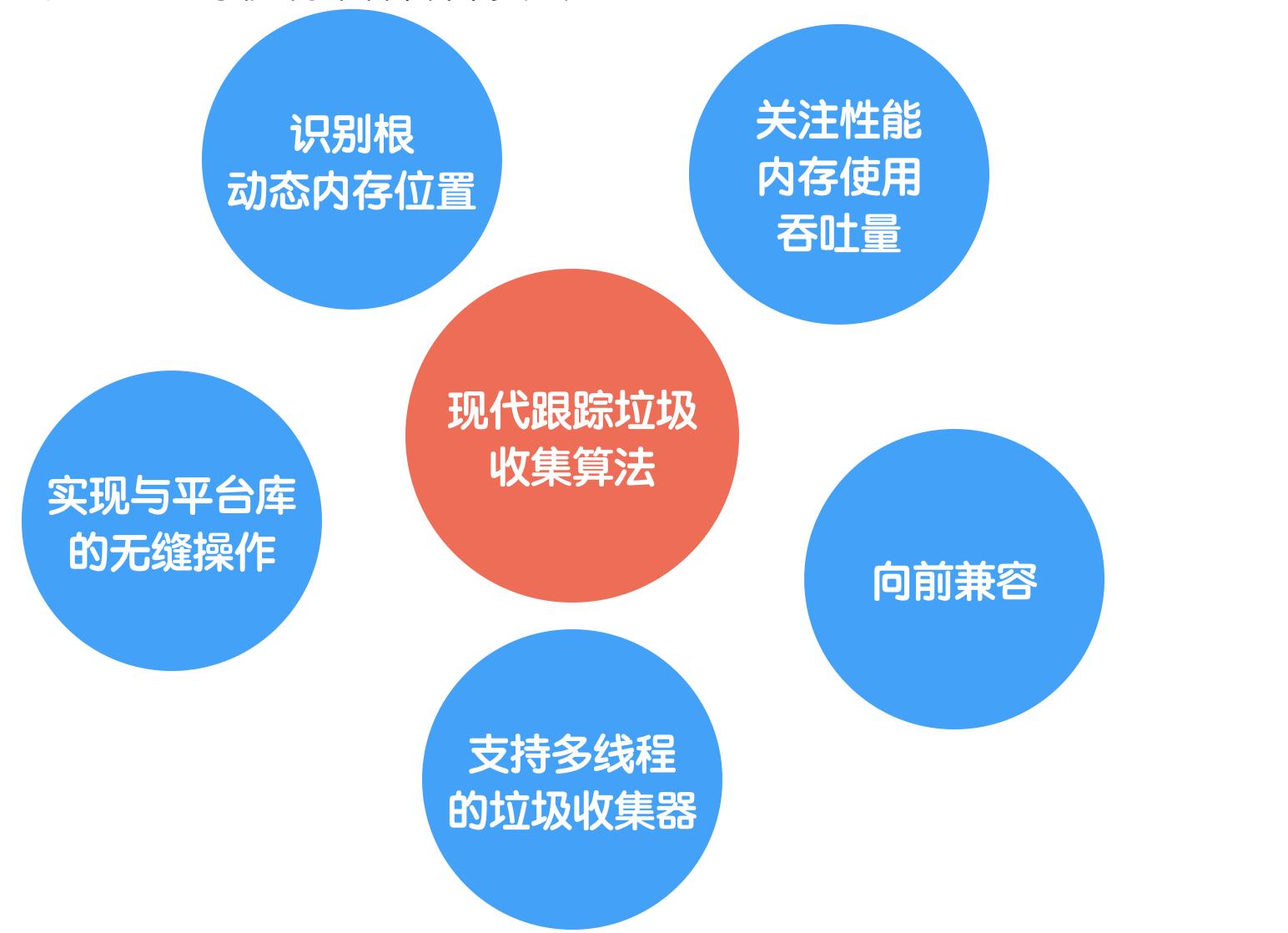
4. 方案选型
由于篇幅问题,太长也不合适,这里先给出使用KMM作为跨平台的一些结论,后续再单独写个文章对比
目标:
1、持续关注研发效率,降本提效
2、一套代码多端运行提升多端业务逻辑的一致性
3、跨端技术方案带来高效运维和缺陷修复
在选择不涉及界面跨平台的基础技术时,如果稳定性、可靠性、成熟度是最需要关心的,那已经发展地十分成熟的C++跨平台成为首选。但考虑建设初期,开发门槛和逻辑效率比较重要,团队需要较为快速验证技术可行性和收益度,后期如果需要大规模推广,对于移动开发人员来说,需要一种更现代的语言,更低学习接入成本的方式,,所以选择 Kotlin Multiplatform 技术作为主要开发方式。
参考
https://github.com/JetBrains/kotlin/blob/master/kotlin-native/README.md#building-from-source
https://blog.jetbrains.com/kotlin/2021/05/kotlin-native-memory-management-update/#kn-gc
https://dev.to/touchlab/practical-kotlin-native-concurrency-ac7
https://kotlinlang.org/docs/native-libraries.html#library-format
以上是关于KMM(Kotlin Multiplatform Mobile)Welcome to Kotlin/Native World的主要内容,如果未能解决你的问题,请参考以下文章