Python数据分析理论与实战完整版本
Posted Geek_bao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析理论与实战完整版本相关的知识,希望对你有一定的参考价值。
Python数据分析基础
一、Python数据分析初探
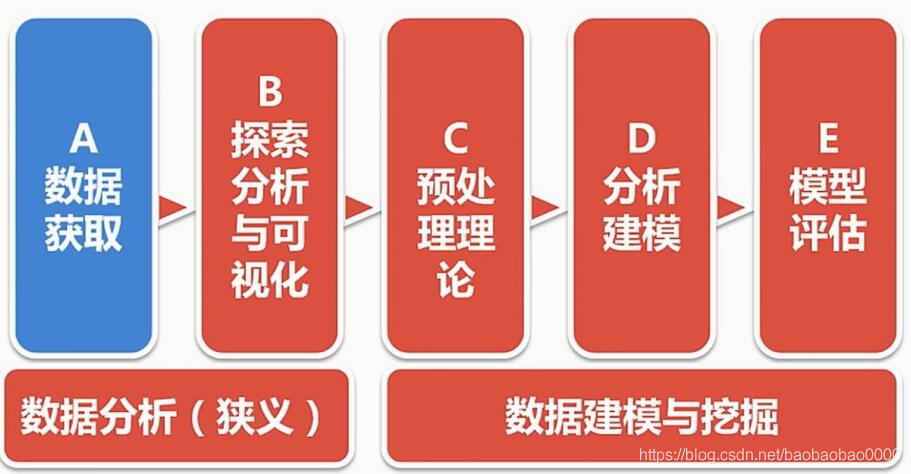
本次我们将从以上路线学习数据分析,本次课程使用python 3 编码学习。另外本章节学习所用的数据集可以kaggle上搜索HR.csv即可获得。
Python这门语言是Guido van Rossum在1989圣诞暑假研究出来的一门语言。特点是:简洁,开发效率高,运算速度慢,胶水特性。
二、数据获取
2.1 数据获取的手段
1.数据仓库
2.监测和抓取
3.填写、日志、埋点
4.计算
2.2 数据仓库
什么是数据仓库?
比如我们建立一个买书的网站,我们要建一个数据库存储各个用户信息,书籍信息,根据用户注册购买等行为,整个网站就运行起来了。网站发展很好,规模不断扩大,网站发展的方向就是一个问题。比如接下来该买什么数,给相应的用户推荐他需要的书。这就需要进行分析,数据分析仅仅依靠我们的数据库是不够的。我们需要一个东西把用户交互数据的变动信息记录下来,如记录某用户在几时几分几秒浏览的哪个页面,购买了什么书之类的。文件和日志也能完成这个记录但是不方面查找、比较和抽取特征等操作。所以我们需要一个载体记录业务流程中的每个细节,这就是数据仓库了。
将所有业务数据经汇总处理,构成数据仓库(DW)
1.全部实施的纪录
2.部分维度与数据的整理(数据集市-DM)
数据库 VS 仓库
1.数据库面向业务存储,仓库面向主题存储(主题:较高层次上对分析对象数据的一个完整并且一致的描述)
2.数据库针对应用(OLTP),仓库针对分析(OLAP)
3.数据库组织规范,仓库可能冗余,相对变化大,数据量大
2.3 检测与抓取
常用工具:
urllib、requests、scrapy
PhantomJS、beautifulSoup、Xpath
2.4 填写、埋点、日志
1.用户填写信息
2.APP或网页埋点(特点流程的信息记录点)
3.操作日志
2.5 计算
通过已有数据计算生成衍生数据
2.6 数据学习网站
数据竞赛网站(Kaggle&天池)
数据集网站(ImageNet/Open Images)
统计数据(统计局、政府机关、公司财报等)
三、单因子探索分析与可视化
3.1 理论铺垫
(1)集中趋势:均值、中位数与分位数、众数
四分位数计算方法:
Q1的位置= (n+1) × 0.25
Q2的位置= (n+1) × 0.5
Q3的位置= (n+1) × 0.75
实例1:
数据总量: 6, 47, 49, 15, 42, 41, 7, 39, 43, 40, 36
由小到大排列的结果: 6, 7, 15, 36, 39, 40, 41, 42, 43, 47, 49,一共11项
Q1 的位置=(11+1) × 0.25=3, Q2 的位置=(11+1)× 0.5=6, Q3的位置=(11+1) × 0.75=9,故
Q1 = 15,
Q2 = 40,
Q3 = 43
实例2:
数据总量: 7, 15, 36, 39, 40, 41,一共6项
数列项为偶数项时,四分位数Q2为该组数列的中数,
(n+1)/4= 7/4 =1.75,Q1在第一与第二个数字之间,
3(n+1)/4= 21/4 =5.25, Q3在第五与第六个数字之间,
Q1 = 0.7515+0.257 = 13,
Q2 = (36+39)/2= 37.5,
Q3 = 0.2541+0.7540 = 40.25.
(2)离中趋势:标准差、方差
注意:正太分布离中趋势,在-σ到σ概率未69%,在-1.96σ到1.96σ概率为95%,在-2.58σ到2.58σ概率为99%

(3)数据分布:偏态与峰态
偏态系数:数据平均值偏离状态的衡量
偏态系数 =0表示其数据分布形态与正态分布的偏斜程度相同;
偏态系数 >0表示其数据分布形态与正态分布相比为正偏(右偏),即有一条长尾巴拖在右边,数据右端有较多的极端值,数据均值右侧的离散程度强;均值相对较大。
偏态 <0表示其数据分布形态与正态分布相比为负偏(左偏),即有一条长尾拖在左边,数据左端有较多的极端值,数据均值左侧的离散程度强,均值相对较小。
举个例子,一组数,1 2 3 4 (6) 20,中位数是3,平均数是6。6比大多数数据都要大。偏态系数公式S如下:

峰态系数:数据分布集中强度的衡量,系数公式K如上。峰度又称峰态系数,表征概率密度分布曲线在平均值处峰值高低的特征数,即是描述总体中所有取值分布形态陡缓程度的统计量。直观看来,峰度反映了峰部的尖度。这个统计量需要与正态分布相比较。他的一个重要作用就是判断该分布是否是正态分布。
峰度 =0表示该总体数据分布与正态分布的陡缓程度相同;
峰度 >0表示该总体数据分布与正态分布相比较为陡峭,为尖顶峰;
峰度 <0表示该总体数据分布与正态分布相比较为平坦,为平顶峰。
峰度的绝对值数值越大表示其分布形态的陡缓程度与正态分布的差异程度越大。
(4)正态分布与三大分布
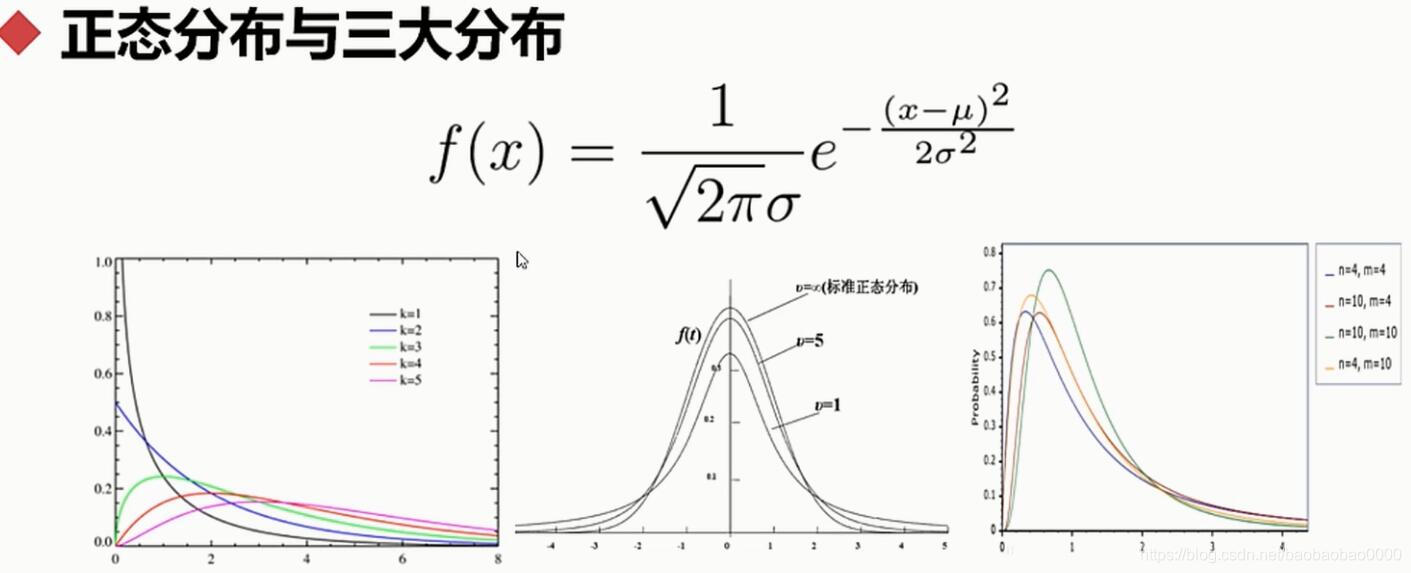
三大分布公式如下:

(5)抽样定理:抽样误差、抽样精度

δ²是总体方差,Zα 表示多少概率需要多少倍的σ,Δ²是我们要控制的方差,δ²是总体方差
下面看看实例1:

下面看看实例2:
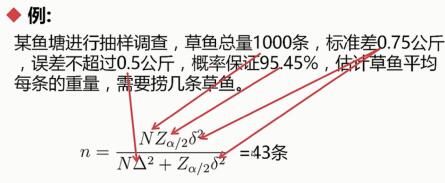
原教程视频中计算有错误,我计算的是4条。
(6)编码实践上述理论
import pandas as pd
df = pd.read_csv('HR.csv')
df
| satisfaction_level | last_evaluation | number_project | average_montly_hours | time_spend_company | Work_accident | left | promotion_last_5years | sales | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.38 | 0.53 | 2 | 157 | 3 | 0 | 1 | 0 | sales | low |
| 1 | 0.80 | 0.86 | 5 | 262 | 6 | 0 | 1 | 0 | sales | medium |
| 2 | 0.11 | 0.88 | 7 | 272 | 4 | 0 | 1 | 0 | sales | medium |
| 3 | 0.72 | 0.87 | 5 | 223 | 5 | 0 | 1 | 0 | sales | low |
| 4 | 0.37 | 0.52 | 2 | 159 | 3 | 0 | 1 | 0 | sales | low |
| 5 | 0.41 | 0.50 | 2 | 153 | 3 | 0 | 1 | 0 | sales | low |
| 6 | 0.10 | 0.77 | 6 | 247 | 4 | 0 | 1 | 0 | sales | low |
| 7 | 0.92 | 0.85 | 5 | 259 | 5 | 0 | 1 | 0 | sales | low |
| 8 | 0.89 | 1.00 | 5 | 224 | 5 | 0 | 1 | 0 | sales | low |
| 9 | 0.42 | 0.53 | 2 | 142 | 3 | 0 | 1 | 0 | sales | low |
| 10 | 0.45 | 0.54 | 2 | 135 | 3 | 0 | 1 | 0 | sales | low |
| 11 | 0.11 | 0.81 | 6 | 305 | 4 | 0 | 1 | 0 | sales | low |
| 12 | 0.84 | 0.92 | 4 | 234 | 5 | 0 | 1 | 0 | sales | low |
| 13 | 0.41 | 0.55 | 2 | 148 | 3 | 0 | 1 | 0 | sales | low |
| 14 | 0.36 | 0.56 | 2 | 137 | 3 | 0 | 1 | 0 | sales | low |
| 15 | 0.38 | 0.54 | 2 | 143 | 3 | 0 | 1 | 0 | sales | low |
| 16 | 0.45 | 0.47 | 2 | 160 | 3 | 0 | 1 | 0 | sales | low |
| 17 | 0.78 | 0.99 | 4 | 255 | 6 | 0 | 1 | 0 | sales | low |
| 18 | 0.45 | 0.51 | 2 | 160 | 3 | 1 | 1 | 1 | sales | low |
| 19 | 0.76 | 0.89 | 5 | 262 | 5 | 0 | 1 | 0 | sales | low |
| 20 | 0.11 | 0.83 | 6 | 282 | 4 | 0 | 1 | 0 | sales | low |
| 21 | 0.38 | 0.55 | 2 | 147 | 3 | 0 | 1 | 0 | sales | low |
| 22 | 0.09 | 0.95 | 6 | 304 | 4 | 0 | 1 | 0 | sales | low |
| 23 | 0.46 | 0.57 | 2 | 139 | 3 | 0 | 1 | 0 | sales | low |
| 24 | 0.40 | 0.53 | 2 | 158 | 3 | 0 | 1 | 0 | sales | low |
| 25 | 0.89 | 0.92 | 5 | 242 | 5 | 0 | 1 | 0 | sales | low |
| 26 | 0.82 | 0.87 | 4 | 239 | 5 | 0 | 1 | 0 | sales | low |
| 27 | 0.40 | 0.49 | 2 | 135 | 3 | 0 | 1 | 0 | sales | low |
| 28 | 0.41 | 0.46 | 2 | 128 | 3 | 0 | 1 | 0 | accounting | low |
| 29 | 0.38 | 0.50 | 2 | 132 | 3 | 0 | 1 | 0 | accounting | low |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 14971 | 0.39 | 0.45 | 2 | 140 | 3 | 0 | 1 | 0 | sales | medium |
| 14972 | 0.11 | 0.97 | 6 | 310 | 4 | 0 | 1 | 0 | accounting | medium |
| 14973 | 0.36 | 0.52 | 2 | 143 | 3 | 0 | 1 | 0 | accounting | medium |
| 14974 | 0.36 | 0.54 | 2 | 153 | 3 | 0 | 1 | 0 | accounting | medium |
| 14975 | 0.10 | 0.79 | 7 | 310 | 4 | 0 | 1 | 0 | hr | medium |
| 14976 | 0.40 | 0.47 | 2 | 136 | 3 | 0 | 1 | 0 | hr | medium |
| 14977 | 0.81 | 0.85 | 4 | 251 | 6 | 0 | 1 | 0 | hr | medium |
| 14978 | 0.40 | 0.47 | 2 | 144 | 3 | 0 | 1 | 0 | hr | medium |
| 14979 | 0.09 | 0.93 | 6 | 296 | 4 | 0 | 1 | 0 | technical | medium |
| 14980 | 0.76 | 0.89 | 5 | 238 | 5 | 0 | 1 | 0 | technical | high |
| 14981 | 0.73 | 0.93 | 5 | 162 | 4 | 0 | 1 | 0 | technical | low |
| 14982 | 0.38 | 0.49 | 2 | 137 | 3 | 0 | 1 | 0 | technical | medium |
| 14983 | 0.72 | 0.84 | 5 | 257 | 5 | 0 | 1 | 0 | technical | medium |
| 14984 | 0.40 | 0.56 | 2 | 148 | 3 | 0 | 1 | 0 | technical | medium |
| 14985 | 0.91 | 0.99 | 5 | 254 | 5 | 0 | 1 | 0 | technical | medium |
| 14986 | 0.85 | 0.85 | 4 | 247 | 6 | 0 | 1 | 0 | technical | low |
| 14987 | 0.90 | 0.70 | 5 | 206 | 4 | 0 | 1 | 0 | technical | low |
| 14988 | 0.46 | 0.55 | 2 | 145 | 3 | 0 | 1 | 0 | technical | low |
| 14989 | 0.43 | 0.57 | 2 | 159 | 3 | 1 | 1 | 0 | technical | low |
| 14990 | 0.89 | 0.88 | 5 | 228 | 5 | 1 | 1 | 0 | support | low |
| 14991 | 0.09 | 0.81 | 6 | 257 | 4 | 0 | 1 | 0 | support | low |
| 14992 | 0.40 | 0.48 | 2 | 155 | 3 | 0 | 1 | 0 | support | low |
| 14993 | 0.76 | 0.83 | 6 | 293 | 6 | 0 | 1 | 0 | support | low |
| 14994 | 0.40 | 0.57 | 2 | 151 | 3 | 0 | 1 | 0 | support | low |
| 14995 | 0.37 | 0.48 | 2 | 160 | 3 | 0 | 1 | 0 | support | low |
| 14996 | 0.37 | 0.53 | 2 | 143 | 3 | 0 | 1 | 0 | support | low |
| 14997 | 0.11 | 0.96 | 6 | 280 | 4 | 0 | 1 | 0 | support | low |
| 14998 | 0.37 | 0.52 | 2 | 158 | 3 | 0 | 1 | 0 | support | low |
| 14999 | NaN | 0.52 | 2 | 223 | 5 | 0 | 1 | 0 | support | low |
| 15000 | NaN | 999999.00 | 2 | 159 | 3 | 0 | 1 | 0 | support | nme |
15001 rows × 10 columns
type(df)
pandas.core.frame.DataFrame
type(df["satisfaction_level"])
pandas.core.series.Series
df.mean()
satisfaction_level 0.612834
last_evaluation 67.378197
number_project 3.802813
average_montly_hours 201.048997
time_spend_company 3.498300
Work_accident 0.144590
left 0.238184
promotion_last_5years 0.021265
dtype: float64
type(df.mean())
pandas.core.series.Series
df["satisfaction_level"].mean()
0.6128335222348166
df.median()
satisfaction_level 0.64
last_evaluation 0.72
number_project 4.00
average_montly_hours 200.00
time_spend_company 3.00
Work_accident 0.00
left 0.00
promotion_last_5years 0.00
dtype: float64
df["satisfaction_level"].median()
0.64
df.quantile(q=0.25)
satisfaction_level 0.44
last_evaluation 0.56
number_project 3.00
average_montly_hours 156.00
time_spend_company 3.00
Work_accident 0.00
left 0.00
promotion_last_5years 0.00
Name: 0.25, dtype: float64
df["satisfaction_level"].quantile(q=0.25)
0.44
df.mode()
| satisfaction_level | last_evaluation | number_project | average_montly_hours | time_spend_company | Work_accident | left | promotion_last_5years | sales | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.1 | 0.55 | 4.0 | 135 | 3.0 | 0.0 | 0.0 | 0.0 | sales | low |
| 1 | NaN | NaN | NaN | 156 | NaN | NaN | NaN | NaN | NaN | NaN |
df["satisfaction_level"].mode()
0 0.1
dtype: float64
df["sales"].mode()
0 sales
dtype: object
df.std()
satisfaction_level 0.248631
last_evaluation 8164.679648
number_project 1.232686
average_montly_hours 49.941272
time_spend_company 1.460096
Work_accident 0.351699
left 0.425987
promotion_last_5years 0.144272
dtype: float64
df["satisfaction_level"].std()
0.2486306510611418
df.var()
satisfaction_level 6.181720e-02
last_evaluation 6.666199e+07
number_project 1.519515e+00
average_montly_hours 2.494131e+03
time_spend_company 2.131880e+00
Work_accident 1.236922e-01
left 1.814645e-01
promotion_last_5years 2.081443e-02
dtype: float64
df["satisfaction_level"].var()
0.061817200647087255
df.sum()
satisfaction_level 9191.89
last_evaluation 1.01074e+06
number_project 57046
average_montly_hours 3015936
time_spend_company 52478
Work_accident 2169
left 3573
promotion_last_5years 319
sales salessalessalessalessalessalessalessalessaless...
salary lowmediummediumlowlowlowlowlowlowlowlowlowlowl...
dtype: object
df["satisfaction_level"].sum()
9191.89
df.skew()
satisfaction_level -0.476360
last_evaluation 122.478569
number_project 0.337751
average_montly_hours 0.052887
time_spend_company 1.853157
Work_accident 2.021370
left 1.229385
promotion_last_5years 6.637440
dtype: float64
df["satisfaction_level"].skew() # 偏态系数
-0.4763603412839644
df.kurt() # 峰态系数
satisfaction_level -0.670859
last_evaluation 15000.999987
number_project -0.495699
average_montly_hours -1.134916
time_spend_company 4.772766
Work_accident 2.086216
left -0.488677
promotion_last_5years 42.061224
dtype: float64
df["satisfaction_level"].kurt()
-0.6708586220574557
import scipy.stats as ss
ss.norm # 生成一个正态分布
<scipy.stats._continuous_distns.norm_gen at 0x2cf966c7f60>
ss.norm.stats(moments='mvsk')
# mvsk
# m mean
# v var
# s skew
# k kurt
# 下面输出的是标准正太分布的相关参数
(array(0.), array(1.), array(0.), array(0.))
ss.norm.pdf(0.0) # 0.39894228.... pdf 是输入横坐标,输出纵坐标,分布函数在0处的值
0.3989422804014327
ss.norm.ppf(0.9) # 输入参数必须0-1之间。
# 1.28155... ppf 是一个累积值,从负无穷大到某点积分是0.9,这个点是多少。
# 负无穷到正无穷是1,当时0.9的时候,是多少
1.2815515655446004
ss.norm.cdf(2) # 从负无穷到2,它的累积概率是多少
0.9772498680518208
ss.norm.cdf(2) - ss.norm.cdf(-2) # 0.95
0.9544997361036416
ss.norm.rvs(size=10) # 得到10个符合正太分布的数字
array([-0.57057331, -0.7166785 , 0.87394188, 0.24162614, -0.55360322,
2.09826541, 0.40785991, -0.02672143, -0.73308176, -1.1403666 ])
ss.chi2 # 卡方分布,操作和正态分布一样。pdf,ppf等
<scipy.stats._continuous_distns.chi2_gen at 0x2cf966f5940>
ss.t # t分布,操作和正态分布一样。pdf,ppf等
<scipy.stats._continuous_distns.t_gen at 0x2cf96764f28>
ss.f # F分布,操作和正态分布一样。pdf,ppf等
<scipy.stats._continuous_distns.f_gen at 0x2cf96707198>
df.sample(n=10) # 抽样10个
| satisfaction_level | last_evaluation | number_project | average_montly_hours | time_spend_company | Work_accident | left | promotion_last_5years | sales | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 12129 | 0.37 | 0.45 | 2 | 151 | 3 | 0 | 1 | 0 | support | low |
| 959 | 0.10 | 0.94 | 7 | 281 | 4 | 0 | 1 | 0 | technical | medium |
| 13851 | 0.51 | 0.52 | 3 | 188 | 3 | 0 | 0 | 0 | technical | high |
| 3398 | 0.64 | 0.50 | 3 | 238 | 4 | 0 | 0 | 0 | technical | low |
| 7820 | 0.12 | 0.84 | 4 | 218 | 6 | 0 | 0 | 0 | technical | medium |
| 9174 | 0.62 | 0.75 | 4 | 183 | 4 | 1 | 0 | 0 | sales | low |
| 14469 | 0.88 | 0.88 | 5 | 232 | 5 | 1 | 1 | 0 | accounting | medium |
| 2096 | 0.86 | 1.00 | 4 | 256 | 3 | 0 | 0 | 0 | technical | medium |
| 12619 | 0.43 | 0.51 | 2 | 141 | 3 | 0 | 1 | 0 | sales | low |
| 1406 | 0.15 | 0.62 | 4 | 257 | 3 | 0 | 1 | 0 | hr | low |
df.sample(frac=0.01) # 按百分比抽样
| satisfaction_level | last_evaluation | number_project | average_montly_hours | time_spend_company | Work_accident | left | promotion_last_5years | sales | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 13585 | 0.98 | 0.89 | 4 | 218 | 2 | 0 | 0 | 0 | sales | medium |
| 14226 | 0.38 | 0.54 | 2 | 143 | 3 | 0 | 1 | 0 | sales | low |
| 8034 | 0.90 | 0.53 | 3 | 270 | 3 | 0 | 0 | 0 | sales | medium |
| 2327 | 0.38 | 0.64 | 3 | 111 | 3 | 0 | 0 | 0 | technical | medium |
| 4455 | 0.68 | 1.00 | 6 | 258 | 5 | 0 | 0 | 0 | sales | low |
| 10915 | 0.98 | 0.67 | 4 | 209 | 6 | 0 | 0 | 0 | marketing | low |
| 14868 | 0.43 | 0.55 | 2 | 130 | 3 | 0 | 1 | 0 | support | high |
| 256 | 0.11 | 0.81 | 6 | 266 | 4 | 1 | 1 | 0 | sales | medium |
| 7548 | 0.96 | 0.78 | 3 | 209 | 2 | 0 | 0 | 0 | product_mng | high |
| 11487 | 0.75 | 0.53 | 4 | 224 | 4 | 1 | 0 | 0 | support | medium |
| 11448 | 0.57 | 0.46 | 3 | 186 | 3 | 1 | 0 | 0 | IT | medium |
| 7752 | 0.13 | 0.74 | 6 | 132 | 4 | 1 | 0 | 0 | technical | medium |
| 859 | 0.10 | 0.93 | 6 | 270 | 4 | 0 | 1 | 0 | sales | low |
| 2908 | 0.73 | 0.75 | 3 | 259 | 4 | 0 | 0 | 0 | marketing | medium |
| 8519 | 0.50 | 0.59 | 4 | 157 | 2 | 0 | 0 | 0 | technical | low |
| 6031 | 0.23 | 0.88 | 5 | 156 | 4 | 0 | 0 | 0 | sales | low |
| 13139 | 0.98 | 0.58 | 3 | 183 | 3 | 0 | 0 | 0 | sales | low |
| 5357 | 0.53 | 0.82 | 5 | 184 | 3 | 0 | 0 | 0 | sales | medium |
| 13446 | 0.65 | 0.62 | 4 | 258 | 2 | 0 | 0 | 0 | support | high |
| 13858 | 0.31 | 0.63 | 4 | 104 | 7 | 1 | 0 | 0 | sales | medium |
| 7008 | 0.56 | 0.68 | 3 | 109 | 3 | 0 | 0 | 0 | IT | low |
| 14682 | 0.44 | 0.53 | 2 | 149 | 3 | 0 | 1 | 0 | sales | low |
| 7519 | 0.18 | 0.86 | 6 | 264 | 3 | 0 | 0 | 0 | technical | high |
| 5014 | 0.92 | 1.00 | 3 | 212 | 2 | 0 | 0 | 0 | support | low |
| 2526 | 0.62 | 0.49 | 4 | 218 | 4 | 0 | 0 | 0 | sales | medium |
| 12563 | 0.10 | 0.77 | 7 | 291 | 4 | 0 | 1 | 0 | accounting | low |
| 11022 | 0.96 | 0.89 | 3 | 142 | 4 | 0 | 0 | 0 | sales | medium |
| 3440 | 0.96 | 0.61 | 3 | 140 | 3 | 0 | 0 | 0 | marketing | low |
| 11761 | 0.88 | 0.83 | 4 | 273 | 10 | 0 | 0 | 0 | sales | medium |
| 42 | 0.40 | 0.46 | 2 | 127 | 3 | 0 | 1 | 0 | technical | low |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3556 | 0.75 | 0.66 | 4 | 202 | 2 | 0 | 0 | 0 | support | low |
| 12170 | 0.81 | 0.99 | 4 | 259 | 5 | 0 | 1 | 0 | sales | low |
| 1724 | 0.92 | 0.89 | 4 | 241 | 5 | 0 | 1 | 0 | technical | low |
| 1867 | 0.44 | 0.48 | 2 | 158 | 3 | 0 | 1 | 0 | technical | low |
| 2117 | 0.78 | 0.72 | 5 | 270 | 3 | 1 | 0 | 0 | technical | low |
| 12660 | 0.44 | 0.50 | 2 | 130 | 3 | 0 | 1 | 0 | support | medium |
| 10126 | 0.93 | 0.71 | 4 | 272 | 2 | 0 | 0 | 0 | support | medium |
| 12949 | 0.68 | 0.84 | 3 | 270 | 3 | 0 | 0 | 0 | support | high |
| 14244 | 0.45 | 0.55 | 2 | 140 | 3 | 0 | 1 | 0 | hr | low |
| 14276 | 0.81 | 0.70 | 6 | 161 | 4 | 0 | 1 | 0 | IT | medium |
| 11376 | 0.95 | 0.52 | 3 | 183 | 2 | 1 | 0 | 0 | sales | low |
| 13005 | 0.66 | 0.80 | 4 | 192 | 3 | 0 | 0 | 0 | hr | medium |
| 709 | 0.42 | 0.48 | 2 | 140 | 3 | 0 | 1 | 0 | sales | low |
| 4094 | 0.30 | 0.80 | 6 | 250 | 3 | 0 | 0 | 0 | support | low |
| 4843 | 0.70 | 0.98 | 4 | 176 | 5 | 0 | 0 | 0 | technical | low |
| 268 | 0.38 | 0.56 | 2 | 156 | 3 | 0 | 1 | 0 | technical | low |
| 13334 | 0.99 | 0.86 | 3 | 167 | 2 | 0 | 0 | 0 | sales | low |
| 1154 | 0.39 | 0.53 | 2 | 131 | 3 | 0 | 1 | 0 | sales | medium |
| 5528 | 0.79 | 0.71 | 4 | 222 | 3 | 0 | 0 | 1 | hr | high |
| 2005 | 0.36 | 0.95 | 3 | 206 | 4 | 0 | 0 | 0 | sales | low |
| 2603 | 0.99 | 0.78 | 4 | 140 | 3 | 0 | 0 | 0 | sales | medium |
| 7789 | 0.77 | 0.78 | 2 | 271 | 3 | 0 | 0 | 0 | management | low |
| 11862 | 0.92 | 1.00 | 4 | 261 | 4 | 0 | 0 | 0 | sales | medium |
| 11388 | 0.52 | 0.80 | 3 | 252 | 4 | 0 | 0 | 0 | product_mng | low |
| 12168 | 0.32 | 0.50 | 2 | 135 | 5 | 0 | 1 | 0 | sales | low |
| 8909 | 0.68 | 0.85 | 3 | 250 | 3 | 0 | 0 | 0 | support | low |
| 12594 | 0.10 | 0.77 | 6 | 255 | 4 | 0 | 1 | 0 | management | low |
| 5498 | 0.97 | 1.00 | 5 | 251 | 2 | 0 | 0 | 0 | accounting | medium |
| 10947 | 0.94 | 0.73 | 3 | 196 | 3 | 0 | 0 | 0 | hr | medium |
| 2593 | 0.57 | 0.90 | 3 | 256 | 4 | 0 | 0 | 0 | RandD | low |
150 rows × 10 columns
df["satisfaction_level"].sample(10)
2512 0.22
3650 0.72
2121 0.75
8606 0.91
11965 0.84
13601 0.49
4951 0.50
12429 0.41
8820 0.23
2712 0.92
Name: satisfaction_level, dtype: float64
3.2 数据分类
定类(类别):根据事物离散、无差别属性进行的分类,如:民族
定序(顺序):可以界定数据的大小,但不能测定差值:如:收入的低、中、高
定距(间隔):可以界定数据大小的同时,可测定差值,但无绝对零点(乘除法之类的无意义),如:温度
定比(比率):可以界定数据大小,可测定差值,有绝对零点
3.3 单属性分析
(1)异常值分析
异常值有:离散异常值,连续异常值,知识异常值。
离散异常值:离散属性定义范围外的所有值均为异常值。比如空值;收入的中高低(如果出现其他结果就是异常值),可以标记出来单独处理。
知识异常值:在限定知识与常识范围外的所有值均为异常值。如身高10米的人。
连续异常值:通过四分位数确定。上界Q3 + k(Q3-Q1)> 正常值 >下界Q1 - k(Q3-Q1),k取1.5-3。连续异常值可以舍弃或用边界值代替,具体业务具体分析。
(2)对比分析
通过比较的方式达到认识事实与了解数据的方法。
比什么:比较的对象是数,绝对数与相对数比较。绝对数就是绝对的数字,比如比较收入,比较身高等。相对数是把几个有联系的指标构成一个数,这个数就是相对数,相对数种类较多,常见的有:
结构相对数,创建的各种率,考试通过率,产品合格率等
比例相对数,总体内用不同部分的数值进行比较。比如传统三大产业的比例
比较相对数,同一时空下的相似或同质的指标进行对比,比如不同时期下同一商品的价格。
动态相对数:一般是有时间概念在里面,物理上的速度等
强度相对数:性质不同但有相互联系的属性进行联合,比如人均概念,我们GDP世界第二,人均就十几名了。
怎么比:
时间维度:同比是和去年同时期比较,环比就是和本年度上个月进行比较。
空间维度:现实方位空间(不同国家,城市等),逻辑空间(同公司不同部门)
经验与计划:经验比较,比如失业率达到多少就会社会大乱,我们需要警戒这个数据。
(3)结构分析
可以看成对比分析中比例相对数的分析,主要有两类,静态结构分析和动态结构分析。
静态结构分析就是直接分析总体的组成,比如我国三大产业的比例,即可了解我国产业结构。
动态结构分析就是以时间为轴,分析结构变化趋势。比如三大产业结构从一个五年计划到下一个五年计划占比变化。
(4)分布分析
1.直接获得概率分布:得到的数排列一下,得到一个分布。
2.判断是不是正态分布,如果是可以用正态分布结论分析该问题。可以通过偏态和峰态判断。
3.极大似然:顾名思义极大相似的样子,相似程度的衡量。给出一串数字,如果我们知道它属于正态分布,那一定可以确定一个均值一个方差。在该均值和方差确定的正态分布下,这串数字的这几个点在这个分布的取值也就是他们的概率,这些值的和或积是最大的,这个和或者积(要取对数)就叫做极大似然。确定是正态分布还是T分布或者F分布,那就比较他们在各自分布下的极大似然,哪个极大似然越大就更接近哪个分布。
3.4 单因子分析实战
这里我们对HR.csv进行分析实战
(1)satisfaction_level 的分析
import numpy as np
import pandas as pd
df = pd.read_csv("HR.csv")
df
| satisfaction_level | last_evaluation | number_project | average_montly_hours | time_spend_company | Work_accident | left | promotion_last_5years | sales | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.38 | 0.53 | 2 | 157 | 3 | 0 | 1 | 0 | sales | low |
| 1 | 0.80 | 0.86 | 5 | 262 | 6 | 0 | 1 | 0 | sales | medium |
| 2 | 0.11 | 0.88 | 7 | 272 | 4 | 0 | 1 | 0 | sales | medium |
| 3 | 0.72 | 0.87 | 5 | 223 | 5 | 0 | 1 | 0 | sales | low |
| 4 | 0.37 | 0.52 | 2 | 159 | 3 | 0 | 1 | 0 | sales | low |
| 5 | 0.41 | 0.50 | 2 | 153 | 3 | 0 | 1 | 0 | sales | low |
| 6 | 0.10 | 0.77 | 6 | 247 | 4 | 0 | 1 | 0 | sales | low |
| 7 | 0.92 | 0.85 | 5 | 259 | 5 | 0 | 1 | 0 | sales | low |
| 8 | 0.89 | 1.00 | 5 | 224 | 5 | 0 | 1 | 0 | sales | low |
| 9 | 0.42 | 0.53 | 2 | 142 | 3 | 0 | 1 | 0 | sales | low |
| 10 | 0.45 | 0.54 | 2 | 135 | 3 | 0 | 1 | 0 | sales | low |
| 11 | 0.11 | 0.81 | 6 | 305 | 4 | 0 | 1 | 0 | sales | low |
| 12 | 0.84 | 0.92 | 4 | 234 | 5 | 0 | 1 | 0 | sales | low |
| 13 | 0.41 | 0.55 | 2 | 148 | 3 | 0 | 1 | 0 | sales | low |
| 14 | 0.36 | 0.56 | 2 | 137 | 3 | 0 | 1 | 0 | sales | low |
| 15 | 0.38 | 0.54 | 2 | 143 | 3 | 0 | 1 | 0 | sales | low |
| 16 | 0.45 | 0.47 | 2 | 160 | 3 | 0 | 1 | 0 | sales | low |
| 17 | 0.78 | 0.99 | 4 | 255 | 6 | 0 | 1 | 0 | sales | low |
| 18 | 0.45 | 0.51 | 2 | 160 | 3 | 1 | 1 | 1 | sales | low |
| 19 | 0.76 | 0.89 | 5 | 262 | 5 | 0 | 1 | 0 | sales | low |
| 20 | 0.11 | 0.83 | 6 | 282 | 4 | 0 | 1 | 0 | sales | low |
| 21 | 0.38 | 0.55 | 2 | 147 | 3 | 0 | 1 | 0 | sales | low |
| 22 | 0.09 | 0.95 | 6 | 304 | 4 | 0 | 1 | 0 | sales | low |
| 23 | 0.46 | 0.57 | 2 | 139 | 3 | 0 | 1 | 0 | sales | low |
| 24 | 0.40 | 0.53 | 2 | 158 | 3 | 0 | 1 | 0 | sales | low |
| 25 | 0.89 | 0.92 | 5 | 242 | 5 | 0 | 1 | 0 | sales | low |
| 26 | 0.82 | 0.87 | 4 | 239 | 5 | 0 | 1 | 0 | sales | low |
| 27 | 0.40 | 0.49 | 2 | 135 | 3 | 0 | 1 | 0 | sales | low |
| 28 | 0.41 | 0.46 | 2 | 128 | 3 | 0 | 1 | 0 | accounting | low |
| 29 | 0.38 | 0.50 | 2 | 132 | 3 | 0 | 1 | 0 | accounting | low |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 14971 | 0.39 | 0.45 | 2 | 140 | 3 | 0 | 1 | 0 | sales | medium |
| 14972 | 0.11 | 0.97 | 6 | 310 | 4 | 0 | 1 | 0 | accounting | medium |
| 14973 | 0.36 | 0.52 | 2 | 143 | 3 | 0 | 1 | 0 | accounting | medium |
| 14974 | 0.36 | 0.54 | 2 | 153 | 3 | 0 | 1 | 0 | accounting | medium |
| 14975 | 0.10 | 0.79 | 7 | 310 | 4 | 0 | 1 | 0 | hr | medium |
| 14976 | 0.40 | 0.47 | 2 | 136 | 3 | 0 | 1 | 0 | hr | medium |
| 14977 | 0.81 | 0.85 | 4 | 251 | 6 | 0 | 1 | 0 | hr | medium |
| 14978 | 0.40 | 0.47 | 2 | 144 | 3 | 0 | 1 | 0 | hr | medium |
| 14979 | 0.09 | 0.93 | 6 | 296 | 4 | 0 | 1 | 0 | technical | medium |
| 14980 | 0.76 | 0.89 | 5 | 238 | 5 | 0 | 1 | 0 | technical | high |
| 14981 | 0.73 | 0.93 | 5 | 162 | 4 | 0 | 1 | 0 | technical | low |
| 14982 | 0.38 | 0.49 | 2 | 137 | 3 | 0 | 1 | 0 | technical | medium |
| 14983 | 0.72 | 0.84 | 5 | 257 | 5 | 0 | 1 | 0 | technical | medium |
| 14984 | 0.40 | 0.56 | 2 | 148 | 3 | 0 | 1 | 0 | technical | medium |
| 14985 | 0.91 | 0.99 | 5 | 254 | 5 | 0 | 1 | 0 | technical | medium |
| 14986 | 0.85 | 0.85 | 4 | 247 | 6 | 0 | 1 | 0 | technical | low |
| 14987 | 0.90 | 0.70 | 5 | 206 | 4 | 0 | 1 | 0 | technical | low |
| 14988 | 0.46 | 0.55 | 2 | 145 | 3 | 0 | 1 | 0 | technical | low |
| 14989 | 0.43 | 0.57 | 2 | 159 | 3 | 1 | 1 | 0 | technical | low |
| 14990 | 0.89 | 0.88 | 5 | 228 | 5 | 1 | 1 | 0 | support | low |
| 14991 | 0.09 | 0.81 | 6 | 257 | 4 | 0 | 1 | 0 | support | low |
| 14992 | 0.40 | 0.48 | 2 | 155 | 3 | 0 | 1 | 0 | support | low |
| 14993 | 0.76 | 0.83 | 6 | 293 | 6 | 0 | 1 | 0 | support | low |
| 14994 | 0.40 | 0.57 | 2 | 151 | 3 | 0 | 1 | 0 | support | low |
| 14995 | 0.37 | 0.48 | 2 | 160 | 3 | 0 | 1 | 0 | support | low |
| 14996 | 0.37 | 0.53 | 2 | 143 | 3 | 0 | 1 | 0 | support | low |
| 14997 | 0.11 | 0.96 | 6 | 280 | 4 | 0 | 1 | 0 | support | low |
| 14998 | 0.37 | 0.52 | 2 | 158 | 3 | 0 | 1 | 0 | support | low |
| 14999 | NaN | 0.52 | 2 | 223 | 5 | 0 | 1 | 0 | support | low |
| 15000 | NaN | 999999.00 | 2 | 159 | 3 | 0 | 1 | 0 | support | nme |
15001 rows × 10 columns
# 提取出列satisfaction_level数据
sl_s = df["satisfaction_level"]
sl_s
0 0.38
1 0.80
2 0.11
3 0.72
4 0.37
5 0.41
6 0.10
7 0.92
8 0.89
9 0.42
10 0.45
11 0.11
12 0.84
13 0.41
14 0.36
15 0.38
16 0.45
17 0.78
18 0.45
19 0.76
20 0.11
21 0.38
22 0.09
23 0.46
24 0.40
25 0.89
26 0.82
27 0.40
28 0.41
29 0.38
...
14971 0.39
14972 0.11
14973 0.36
14974 0.36
14975 0.10
14976 0.40
14977 0.81
14978 0.40
14979 0.09
14980 0.76
14981 0.73
14982 0.38
14983 0.72
14984 0.40
14985 0.91
14986 0.85
14987 0.90
14988 0.46
14989 0.43
14990 0.89
14991 0.09
14992 0.40
14993 0.76
14994 0.40
14995 0.37
14996 0.37
14997 0.11
14998 0.37
14999 NaN
15000 NaN
Name: satisfaction_level, Length: 15001, dtype: float64
# 看看有没有异常值
sl_s[sl_s.isnull()]
14999 NaN
15000 NaN
Name: satisfaction_level, dtype: float64
# 看一下该行所有数据
df[df["satisfaction_level"].isnull()]
| satisfaction_level | last_evaluation | number_project | average_montly_hours | time_spend_company | Work_accident | left | promotion_last_5years | sales | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 14999 | NaN | 0.52 | 2 | 223 | 5 | 0 | 1 | 0 | support | low |
| 15000 | NaN | 999999.00 | 2 | 159 | 3 | 0 | 1 | 0 | support | nme |
sl_s = sl_s.dropna() # 丢弃异常值
sl_s
0 0.38
1 0.80
2 0.11
3 0.72
4 0.37
5 0.41
6 0.10
7 0.92
8 0.89
9 0.42
10 0.45
11 0.11
12 0.84
13 0.41
14 0.36
15 0.38
16 0.45
17 0.78
18 0.45
19 0.76
20 0.11
21 0.38
22 0.09
23 0.46
24 0.40
25 0.89
26 0.82
27 0.40
28 0.41
29 0.38
...
14969 0.43
14970 0.78
14971 0.39
14972 0.11
14973 0.36
14974 0.36
14975 0.10
14976 0.40
14977 0.81
14978 0.40
14979 0.09
14980 0.76
14981 0.73
14982 0.38
14983 0.72
14984 0.40
14985 0.91
14986 0.85
14987 0.90
14988 0.46
14989 0.43
14990 0.89
14991 0.09
14992 0.40
14993 0.76
14994 0.40
14995 0.37
14996 0.37
14997 0.11
14998 0.37
Name: satisfaction_level, Length: 14999, dtype: float64
sl_s.mean() # 均值
0.6128335222348166
sl_s.std() # 标准差
0.2486306510611418
sl_s.quantile(q=0.25) # 四分位数
0.44
sl_s.skew() # 偏度
-0.4763603412839644
sl_s.kurt() # 峰度
-0.6708586220574557
np.histogram(sl_s.values, bins=np.arange(0.0,