Pytorch TextCNN实现中文文本分类(附完整训练代码)
Posted AI吃大瓜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch TextCNN实现中文文本分类(附完整训练代码)相关的知识,希望对你有一定的参考价值。
Pytorch TextCNN实现中文文本分类(附完整训练代码)
目录
Pytorch TextCNN实现中文文本分类(附完整训练代码)
(3)配置文件:config_textfolder.yaml
一、项目介绍
本篇将分享一个NLP项目实例,利用深度学习框架Pytorch,构建TextCNN模型(也支持TextCNN,LSTM,BiLSTM模型),实现一个简易的中文文本分类模型;基于该项目训练的TextCNN的文本分类模型,在THUCNews数据集上,训练集的Accuracy 99%左右,测试集的Accuracy在88.36%左右。
如果,你想学习中文单词预测,请参考《Pytorch LSTM实现中文单词预测(附完整训练代码)_》
【尊重原则,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/127846717
二、中文文本数据集
中文文本数据集特别多,这里仅仅介绍2个常用的文本文本分类数据集
(1)THUCNews文本数据集
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。我们在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。使用THUCTC工具包在此数据集上进行评测,准确率可以达到88.6%。
- 官方数据集下载链接: http://thuctc.thunlp.org/message
- 百度网盘下载链接: https://pan.baidu.com/s/1DT5xY9m2yfu1YGaGxpWiBQ 提取码: bbpe
THUCTC: 一个高效的中文文本分类工具包: THUCTC: 一个高效的中文文本分类工具
(2) 今日头条文本数据集
今日头条文本数据集数据来源于今日头条客户端,约382688条,分布于15个分类中。
数据格式:
6552431613437805063_!_102_!_news_entertainment_!_谢娜为李浩菲澄清网络谣言,之后她的两个行为给自己加分_!_佟丽娅,网络谣言,快乐大本营,李浩菲,谢娜,观众们
每行为一条数据,以_!_分割的个字段,从前往后分别是 新闻ID,分类code(见下文),分类名称(见下文),新闻字符串(仅含标题),新闻关键词;分类code与名称:
100 民生 故事 news_story
101 文化 文化 news_culture
102 娱乐 娱乐 news_entertainment
103 体育 体育 news_sports
104 财经 财经 news_finance
106 房产 房产 news_house
107 汽车 汽车 news_car
108 教育 教育 news_edu
109 科技 科技 news_tech
110 军事 军事 news_military
112 旅游 旅游 news_travel
113 国际 国际 news_world
114 证券 股票 stock
115 农业 三农 news_agriculture
116 电竞 游戏 news_gameGitHub - aceimnorstuvwxz/toutiao-text-classfication-dataset: 今日头条中文新闻(文本)分类数据集
(3)自定义文本数据集
如果需要新增类别数据,或者需要自定数据集进行训练,可以如下进行处理:
- Train和Test数据集:一个样本一个txt文本,要求相同类别的文本,放在同一个文件夹下;且子目录文件夹命名为类别名称,如
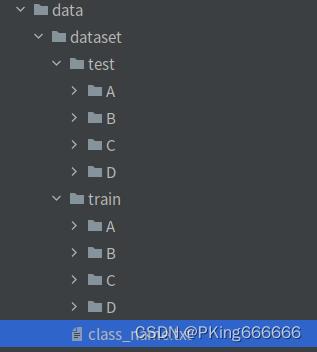
- 类别文件 class_name.txt : (一行一个列表,最后一行,请多回车一行)
A
B
C
D
- 修改配置文件数据路径:config.yaml
# 训练数据集,可支持多个数据集
train_data:
- "data/dataset/train"
# 测试数据集
test_data:
- "data/dataset/test"
vocab_file: "./data/dataset/vocabulary.json" # 字典文件(会根据训练数据集自动生成)
# 类别文件
class_name: "data/dataset/class_name.txt"三、TextCNN模型结构
(1)TextCNN模型结构
TextCNN文本分类的网络结,如下图所示,可以分为4部分:分别为输入层,CNN层,池化层和输出层:
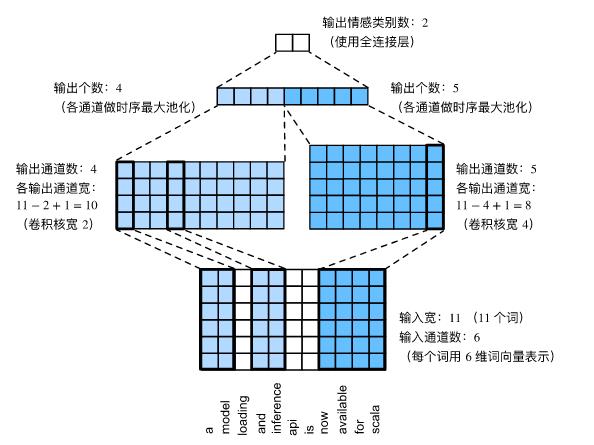
以中文文本情感分类(二分类)作为简单的例子。
- 输入层:也称embedding层,TextCNN的输入序列是一个固定长度的句子:图示中是由11个词组成一条句子(context_size=11),每个词用6维词向量表示(embedding_dim=6),即输入通道数in_channels=6。因此输入序列shape=(11,6),加上Batch这个维度,则是shape=(batch_size,context_size,embedding_dim)=(B,11,6)
- CNN层,也称卷积层,由一维卷积核(Conv1d)组成,左边的一维卷积核大小为2(kernel_size=2),输出通道数分别设为4;右边的一维卷积核大小为4(kernel_size=4),输出通道数分别设为5;卷积步长stride=1;因此,一维卷积计算后,左边一维卷积输出宽度=11−2+1=10,右边边一维卷积输出宽度11−4+1=8。
- 池化层:将CNN层的输出的9个通道经过时序最大池化(max_pool1d),并将池化输出cat连结成一个9维向量。
- 分类层:也是输出层,由简单的全连接层组成;对于简单二分类,其输出维度2,即正面情感和负面情感的预测(概率)。
(2)TextCNN实现
根据TextCNN网络结构,我们可以使用Pytorch构建一个TextCNN模型
# -*-coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
class GlobalMaxPool1d(nn.Module):
def __init__(self):
super(GlobalMaxPool1d, self).__init__()
def forward(self, x):
return F.max_pool1d(x, kernel_size=x.shape[2]) # shape: (batch_size, channel, 1)
class TextCNN(nn.Module):
def __init__(self, num_classes, num_embeddings=-1, embedding_dim=128, kernel_sizes=[3, 4, 5, 6],
num_channels=[256, 256, 256, 256], embeddings_pretrained=None):
"""
:param num_classes: 输出维度(类别数num_classes)
:param num_embeddings: size of the dictionary of embeddings,词典的大小(vocab_size),
当num_embeddings<0,模型会去除embedding层
:param embedding_dim: the size of each embedding vector,词向量特征长度
:param kernel_sizes: CNN层卷积核大小
:param num_channels: CNN层卷积核通道数
:param embeddings_pretrained: embeddings pretrained参数,默认None
:return:
"""
super(TextCNN, self).__init__()
self.num_classes = num_classes
self.num_embeddings = num_embeddings
# embedding层
if self.num_embeddings > 0:
# embedding之后的shape: torch.Size([200, 8, 300])
self.embedding = nn.Embedding(num_embeddings, embedding_dim)
if embeddings_pretrained is not None:
self.embedding = self.embedding.from_pretrained(embeddings_pretrained, freeze=False)
# 卷积层
self.cnn_layers = nn.ModuleList() # 创建多个一维卷积层
for c, k in zip(num_channels, kernel_sizes):
cnn = nn.Sequential(
nn.Conv1d(in_channels=embedding_dim,
out_channels=c,
kernel_size=k),
nn.BatchNorm1d(c),
nn.ReLU(inplace=True),
)
self.cnn_layers.append(cnn)
# 最大池化层
self.pool = GlobalMaxPool1d()
# 输出层
self.classify = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(sum(num_channels), self.num_classes)
)
def forward(self, input):
"""
:param input: (batch_size, context_size, embedding_size(in_channels))
:return:
"""
if self.num_embeddings > 0:
# 得到词嵌入(b,context_size)-->(b,context_size,embedding_dim)
input = self.embedding(input)
# (batch_size, context_size, channel)->(batch_size, channel, context_size)
input = input.permute(0, 2, 1)
y = []
for layer in self.cnn_layers:
x = layer(input)
x = self.pool(x).squeeze(-1)
y.append(x)
y = torch.cat(y, dim=1)
out = self.classify(y)
return out
if __name__ == "__main__":
device = "cuda:0"
batch_size = 4
num_classes = 2 # 输出类别
context_size = 7 # 句子长度(字词个数)
num_embeddings = 1024 # 词典的大小(vocab_size)
embedding_dim = 6 # 词向量特征长度
kernel_sizes = [2, 4] # CNN层卷积核大小
num_channels = [4, 5] # CNN层卷积核通道数
input = torch.ones(size=(batch_size, context_size)).long().to(device)
model = TextCNN(num_classes=num_classes,
num_embeddings=num_embeddings,
embedding_dim=embedding_dim,
kernel_sizes=kernel_sizes,
num_channels=num_channels,
)
model = model.to(device)
model.eval()
output = model(input)
print("-----" * 10)
print(model)
print("-----" * 10)
print(" input.shape:".format(input.shape))
print("output.shape:".format(output.shape))
print("-----" * 10)
测试模型打印结果:

四、训练词嵌入word2vec(可选)
- 不管是CNN还是RNN模型,都是无法直接处理字符类别的单词,因此需要通过某种方法把单词变成数字形式的向量才能作为模型的输入。把单词映射到向量空间中的一个向量的做法称为词嵌入(word embedding),对应的向量称为词向量(word vector)
- 上面的TextCNN模型代码中,定义了一个可学习的embedding层,即词嵌入word2vec,其作用就是将word序号ID转换为vector;当然你也可以通过gensim训练自己的word2vec模型,然后在数据处理中先将文本转换为词向量,这样TextCNN就没有必要添加embedding层了。
项目仓库中,提供了基于gensim的word2vec训练代码: word2vec.py ,用户只需要修改好数据路径即可开始训练
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : 390737991@qq.com
@Date : 2022-09-26 14:50:34
@Brief :
"""
import os
import sys
sys.path.insert(0, os.getcwd())
import random
import numpy as np
from gensim.models import word2vec
from core.utils import jieba_utils, nlp_utils
from pybaseutils import file_utils
class ChineseWord2Vector(object):
"""中文word2vec"""
def __init__(self, stop_words=[], vector_size=128, window=5, min_count=5, epochs=10, workers=4):
"""
:param stop_words: 停用词,用于ignore的字词
:param vector_size: 是每个词的向量维度embedding_size
:param window: 是词向量训练时的上下文扫描窗口大小,窗口为5就是考虑前5个词和后5个词
:param min_count: 设置最低频数,默认是5,如果一个词语在文档中出现的次数小于5,那么就会丢弃
:param epochs: Number of iterations (epochs) over the corpus. (Formerly: `iter`)
:param workers: 是训练的线程数,默认是当前运行机器的处理器核数
"""
self.stop_words = stop_words if stop_words else jieba_utils.get_common_stop_words()
self.vector_size = vector_size
self.epochs = epochs
self.window = window
self.min_count = min_count
self.workers = workers
self.model: word2vec.Word2Vec = None
def init_model(self):
self.index_to_key = self.model.wv.index_to_key
self.key_to_index = self.model.wv.key_to_index
self.embedding = self.model.wv.vectors
self.vector_size = self.model.wv.vector_size
return self.model
def cut_words_files(self, corpus: str, cutwords: str, user_file: str = "data/user_dict.txt", stop_words=[]):
"""
:param corpus: 语料文件
:param cutwords: jieba分词后保存的根目录
:param user_file: 用户自定义的文件
:param stop_words: 停用词,用于ignore的字词
:return:
"""
jieba_utils.load_userdict(user_file)
print("corpus root :".format(corpus))
print("output cutwords :".format(cutwords))
print("user_file :".format(user_file))
print("stop_words :".format(stop_words))
if not stop_words: stop_words = self.stop_words
self.stop_words = stop_words
nlp_utils.get_files_sentences_cutword(corpus, cutwords, stop_words=stop_words, block_size=10000)
# 若只有一个文件,使用LineSentence读取文件
# sentences = word2vec.LineSentence(segment_path)
# 若存在多文件,使用PathLineSentences读取文件列表
# sentences = word2vec.PathLineSentences(cutwords)
sentences = word2vec.PathLineSentences(cutwords)
return sentences
def start_train(self, sentences):
"""
:param sentences: *.txt文件路径,所有字词需要预处理并被空格分隔
sentences可以是LineSentence或者PathLineSentences读取的文件对象,也可以是
The `sentences` iterable can be simply a list of lists of tokens,
如lists=[['我','是','中国','人'],['我','的','家乡','在','广东']]
"""
self.model = word2vec.Word2Vec(sentences,
vector_size=self.vector_size,
window=self.window,
min_count=self.min_count,
workers=self.workers,
epochs=self.epochs,
seed=2020,
)
def save_model(self, model_file) -> word2vec.Word2Vec:
file_utils.create_file_path(model_file)
self.model.save(model_file)
self.init_model()
return self.model
def load_model(self, model_file) -> word2vec.Word2Vec:
self.model = word2vec.Word2Vec.load(model_file)
self.init_model()
return self.model
def get_similarity(self, key1, key2):
"""Compute cosine similarity between two keys."""
return self.model.wv.similarity(key1, key2)
def get_index(self, key, default=None):
"""Return the integer index (slot/position) where the given key's vector is stored in the backing vectors array."""
return self.model.wv.get_index(key, default=default)
def get_vector(self, key, norm=False):
"""Get the key's vector, as a 1D numpy array."""
return self.model.wv.get_vector(key, norm=norm)
def get_text_vector(self, text, context_size=-1, pad_token='<pad>'):
"""
将句子中的所有词转为词向量
:param text:
:return: context_size 句子最大长度max_size
:return: pad_token 句子不足时,是否填充0
"""
if context_size > 0: text = text[0:min(6 * context_size, len(text))]
words = jieba_utils.cut_content_word(text, stop_words=self.stop_words)
words = jieba_utils.padding_words(words, context_size=context_size, pad_token=pad_token)
vector = self.get_words_vector(words)
return vector
def get_words_vector(self, words):
"""
将word转换为vecror
:param words:
:return:
"""
vector = []
for w in words:
try:
v = self.get_vector(w)
except Exception as e:
v = np.zeros(shape=(self.model.vector_size,), dtype=np.float32)
vector.append(v)
vector = np.asarray(vector, dtype=np.float32)
return vector
def get_words_vector_padding(self, words, context_size=256, random_crop=False, padding=True):
vector = []
for w in words:
try:
v = self.get_vector(w)
vector.append(v)
except Exception as e:
pass
if len(vector) == 0: return []
vector = np.asarray(vector, dtype=np.float32)
nums, dims = vector.shape
pad = context_size - nums
if padding and pad > 0:
zeros = np.zeros(shape=(pad, dims), dtype=np.float32)
vector = np.concatenate([vector, zeros], axis=0)
if random_crop and pad < 0:
start = random.randint(0, nums - context_size)
vector = vector[start:start + context_size, :]
else:
vector = vector[0:context_size, :]
return vector
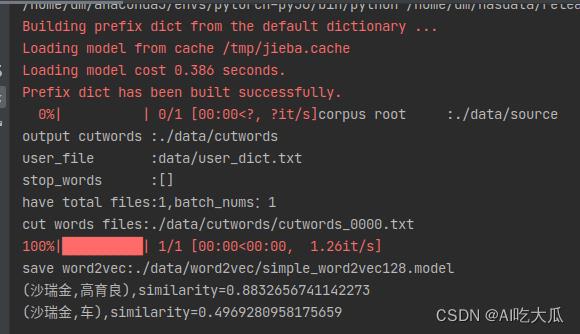
def train_simple_demo():
source = './data/source' # 文本数据路径
user_file = 'data/user_dict.txt'
cutwords = os.path.join(os.path.dirname(source), "cutwords") # 分词结果
model_file = os.path.join(os.path.dirname(source), "word2vec", "simple_word2vec128.model")
wv_trainer = ChineseWord2Vector(vector_size=128, window=10, min_count=5, epochs=10)
sentences = wv_trainer.cut_words_files(source, cutwords, user_file=user_file)
wv_trainer.start_train(sentences)
wv_trainer.save_model(model_file)
model = wv_trainer.load_model(model_file)
print("save word2vec:".format(model_file))
# 测试
w1 = '沙瑞金'
w2 = '高育良'
w3 = '车'
vector = wv_trainer.get_vector(w1)
print("(,),similarity=".format(w1, w2, model.wv.similarity(w1, w2)))
print("(,),similarity=".format(w1, w3, model.wv.similarity(w1, w3)))
# print(" shape=,vector= \\n".format(w1, vector.shape, vector))
vector = wv_trainer.get_text_vector("我是一名中国人zhongguo")
def train_THUCNews():
source = '/home/dm/nasdata/dataset/csdn/Text/THUCNews' # 文本数据路径
user_file = "./data/user_dict.txt"
cutwords = os.path.join(os.path.dirname(source), "THUCNews-cutwords") # 分词结果
model_file = os.path.join(os.path.dirname(source), "word2vec128.model")
wv_trainer = ChineseWord2Vector(vector_size=128, window=10, min_count=5, epochs=10)
sentences = wv_trainer.cut_words_files(source, cutwords, user_file=user_file)
wv_trainer.start_train(sentences)
wv_trainer.save_model(model_file)
model = wv_trainer.load_model(model_file)
print("save word2vec:".format(model_file))
# 测试
w1 = '北京'
w2 = '上海'
w3 = '吃饭'
vector = wv_trainer.get_vector(w1)
print("(,),similarity=".format(w1, w2, model.wv.similarity(w1, w2)))
print("(,),similarity=".format(w1, w3, model.wv.similarity(w1, w3)))
# print(" shape=,vector= \\n".format(w1, vector.shape, vector))
vector = wv_trainer.get_text_vector("我是一名中国人zhongguo")
if __name__ == '__main__':
# 简单的训练词嵌入模型
train_simple_demo()
# 使用THUCNews数据训练词嵌入模型
# train_THUCNews()
样例中,使用小说《人民名义》 训练一个word2vec模型,训练完成后,测试单词(沙瑞金,高育良)的相似性similarity=0.8832;而(沙瑞金,车)的相似性similarity=0.4969。
五、文本预处理
Pytorch的提供文本处理工具torchtext;该工具功能非常强大,提供了很多nlp方面的数据集,可以直接加载使用,也提供了不少训练好的词向量之类的;但该工具封装的太高级了,实际使用起来,限制也太多了,灵活性不高,导致这个模块使用起来特别的别扭。所有后面干脆自己写Dataset数据处理方式了;
对于中文文本数据预处理,主要有两部分:句子分词处理(英文文本不需要分词),特殊字符处理
(1)句子分词处理:jieba中文分词
本博客使用jieba工具进行中文分词,工具比较简单,就不单独说明了,安装方法:
pip install jieba
(2)特殊字符处理
jieba分词后,会出现很多特殊字符,需要进一步做一些的处理
- 一些换行符,空格等特殊字符,以及一些标点符号(,。!?《》)等,这些特殊的字符称为stop_words,需要剔除
- 一些英文字母大小需要转换统一为小写
- 一些繁体字统一转换为简体字等
- 一些专有名词,比如地名,人名这些,分词时需要整体切词:jieba.load_userdict(file)
(3)文本数据增强
在计算机视觉图像识别任务中,图像数据增强主要有:裁剪、翻转、旋转、⾊彩变换等⽅式,其目的增加数据的多样性,提高模型的泛化能力。但是NLP任务中的数据是离散的,无法像操作图片一样连续的方式操作文字,这导致我们⽆法对输⼊数据进⾏直接简单地转换,换掉⼀个词就有可能改变整个句⼦的含义。
常用的NLP文本数据增强方法主要有:
- 随机截取: 随机截取文本一个片段
- 同义词替换(SR: Synonyms Replace):不考虑stopwords,在句⼦中随机抽取n个词,然后从同义词词典中随机抽取同义词,并进⾏替换。
- 随机插⼊(RI: Randomly Insert):不考虑stopwords,随机抽取⼀个词,然后在该词的同义词集合中随机选择⼀个,插⼊原句⼦中的随机位置。
- 随机交换(RS: Randomly Swap):句⼦中,随机选择两个词,位置交换。
- 随机删除(RD: Randomly Delete):句⼦中的每个词,以概率p随机删除
项目已经实现:随机截取,随机插⼊,随机删除等几种文本数据增强方式:
# -*- coding: utf-8 -*-
import math
import random
from typing import List
def random_text_crop(text: List, label, context_size, token="<pad>", p=0.5):
"""
句⼦中的每个词,以概率p随机截取
:param text:
:param label:
:param context_size:
:param token:
:param p:
:return:
"""
context_size = int(context_size)
nums = len(text)
pad = context_size - nums
if pad > 0 and token:
text = [token] * pad + text
if random.random() < p and pad < 0:
start = random.randint(0, nums - context_size)
text = text[start:start + context_size]
elif len(text) > context_size:
text = text[0:context_size]
return text, label
def random_text_mask(text: List, label, len_range=(0, 2), token="<pad>", p=0.5):
"""
句⼦中的每个词,以概率p替换成token
:param text:
:param label:
:param len_range:
:param p:
:return:
"""
if random.random() < p and len(text) > 2 * len_range[1]:
nums = math.ceil(random.uniform(len_range[0], len_range[1]))
for i in range(nums):
index = int(random.uniform(0, len(text) - 1))
text[index] = token
return text, label
def random_text_delete(text: List, label, len_min, p=0.5):
"""
句⼦中的每个词,以概率p随机删除
:param text:
:param label:
:param len_min: 句子最小长度,低于该值,不会删除
:param p:
:return:
"""
if random.random() < p and len(text) > len_min:
nums = int(random.uniform(0, len(text) - len_min))
for i in range(nums):
index = int(random.uniform(0, len(text)))
del text[index]
return text, label
def random_text_insert(text: List, label, len_range=(0, 2), token="<pad>", p=0.5):
"""
句⼦中的每个词,以概率p随机插入
:param text:
:param label:
:param len_range:
:param p:
:return:
"""
if random.random() < p and len(text) > 2 * len_range[1]:
nums = math.ceil(random.uniform(len_range[0], len_range[1]))
for i in range(nums):
index = int(random.uniform(0, len(text) - 1))
text.insert(index, token)
return text, label
if __name__ == '__main__':
label = 1
context_size = 10
pad_token = "<pad>"
p = 10
for i in range(10):
text = "我是一名中国人,我爱中国,我的家乡在广东"
text = "_".join(text).split("_")
len_range = (0, context_size // 4)
# text, label = random_text_crop(text, label, 1.8 * context_size, token=None, p=0.8)
# text, label = random_text_delete(text, label, len_min=1.5 * context_size)
text, label = random_text_insert(text, label, len_range=len_range, token=pad_token)
# text, label = random_text_mask(text, label, len_range=len_range, token=pad_token)
# text, label = random_text_crop(text, label, context_size, token=pad_token, p=0.8)
print(text, len(text))
六、训练过程
项目以THUCNews文本分类数据集为作为训练数据,训练一个基于TextCNN的文本分类模型;这里为了简单,没有使用gensim训练word2vec词向量模型,而是在TextCNN模型代码中,定义了一个可学习的embedding层,用于代替word2vec
(1)项目框架说明
.
├── configs # 训练配置文件
├── core # 模型和训练相关工具
├── data # 相关数据
├── modules # 相关依赖包模块
├── work_space # 训练模型输出文件目录
├── README.md # 项目工程说明文档
├── requirements.txt # 相关依赖包版本说明,请用pip安装
├── word2vec.py # 训练词嵌入模型
├── classifier.py # 测试文本分类脚本
└── train.py # 训练文件
项目依赖的python包,请使用pip安装对应版本
numpy==1.16.3
matplotlib==3.1.0
Pillow==6.0.0
easydict==1.9
opencv-contrib-python==4.5.2.52
opencv-python==4.5.1.48
pandas==1.1.5
PyYAML==5.3.1
scikit-image==0.17.2
scikit-learn==0.24.0
scipy==1.5.4
seaborn==0.11.2
tensorboard==2.5.0
tensorboardX==2.1
torch==1.7.1+cu110
torchvision==0.8.2+cu110
tqdm==4.55.1
xmltodict==0.12.0
basetrainer
pybaseutils==0.6.9
jieba==0.42.1
gensim==4.2.0
(2)准备Train和Test文本数据
下载THUCNews文本数据集,并解压;由于原始数据没有划分训练集和测试集,需要自己手动划分,项目随机抽取每类的100张文本作为测试集,其余的为训练集;
然后根据自己的保存的数据路径,修改配置文件数据路径:config_textfolder.yaml
# 训练数据集,可支持多个数据集
train_data:
- "/path/to/dataset/THUCNews/train"
# 测试数据集
test_data:
- "/path/to/dataset/THUCNews/test"
vocab_file: "./data/vocabulary/vocabulary.json" # 字典文件(会根据训练数据集自动生成),或者word2vec文件
# 类别文件
class_name: "path/to/dataset/THUCNews/class_name.txt"
(3)配置文件:config_textfolder.yaml
# 训练数据集,可支持多个数据集
train_data:
- "/path/to/dataset/THUCNews/train"
# 测试数据集
test_data:
- "/path/to/dataset/THUCNews/test"
vocab_file: "./data/vocabulary/vocabulary.json" # 字典文件(会根据训练数据集自动生成),或者word2vec文件
# 类别文件
class_name: "path/to/dataset/THUCNews/class_name.txt"
data_type: "textfolder" # 加载数据DataLoader方法:word2vec,textfolder
flag: "" # 输出目录标识
resample: True # 是否进行重采样
work_dir: "work_space" # 保存输出模型的目录
net_type: "TextCNN" # 骨干网络,支持:TextCNN,TextCNNv2,LSTM,BiLSTM等
context_size: 300 # 句子长度
topk: [ 1, ] # 计算topK的准确率
batch_size: 128 # 批训练大小
lr: 0.001 # 初始学习率
optim_type: "Adam" # 选择优化器,SGD,Adam
loss_type: "CELoss" # 选择损失函数:支持CrossEntropyLoss(CELoss)
momentum: 0.9 # SGD momentum
num_epochs: 160 # 训练循环次数
num_workers: 12 # 加载数据工作进程数
weight_decay: 0.00005 # weight_decay,默认5e-4
#weight_decay: 0.0 # weight_decay,默认5e-4
scheduler: "multi-step" # 学习率调整策略
milestones: [ 90,120,140 ] # 下调学习率方式
gpu_id: [ 0,1 ] # GPU ID
log_freq: 10 # LOG打印频率
pretrained: True # 是否使用pretrained模型
finetune: False # 是否进行finetune- 目标支持模型主要有:TextCNN,LSTM,BiLSTM等,详见模型等 ,其他模型可以自定义添加
- 训练参数可以通过config.yaml配置文件
| 参数 | 类型 | 参考值 | 说明 |
|---|---|---|---|
| train_data | str, list | - | 训练数据文件,可支持多个文件 |
| test_data | str, list | - | 测试数据文件,可支持多个文件 |
| vocab_file | str | - | 字典文件(会根据训练数据集自动生成),或者word2vec文件 |
| class_name | str | - | 类别文件 |
| data_type | str | - | 加载数据DataLoader方法 |
| resample | bool | True | 是否进行重采样 |
| work_dir | str | work_space | 训练输出工作空间 |
| net_type | str | TextCNN | 骨干网络,支持:TextCNN,LSTM,BiLSTM等 |
| context_size | int | 128 | 句子长度 |
| topk | list | [1,3,5] | 计算topK的准确率 |
| batch_size | int | 32 | 批训练大小 |
| lr | float | 0.1 | 初始学习率大小 |
| optim_type | str | SGD | 优化器,SGD,Adam |
| loss_type | str | CELoss | 损失函数 |
| scheduler | str | multi-step | 学习率调整策略,multi-step,cosine |
| milestones | list | [30,80,100] | 降低学习率的节点,仅仅scheduler=multi-step有效 |
| momentum | float | 0.9 | SGD动量因子 |
| num_epochs | int | 120 | 循环训练的次数 |
| num_workers | int | 12 | DataLoader开启线程数 |
| weight_decay | float | 5e-4 | 权重衰减系数 |
| gpu_id | list | [ 0 ] | 指定训练的GPU卡号,可指定多个 |
| log_freq | int | 20 | 显示LOG信息的频率 |
| finetune | str | model.pth | finetune的模型 |
(4)开始训练
整套训练代码非常简单操作,用户只需要将相同类别的数据放在同一个目录下,并填写好对应的数据路径,即可开始训练了。
- 如果你想验证项目可不可以训练,请运行下面命令开始训练;项目自带了小批量的文本数据,方便测试项目代码;正确情况下,可以获得99%的文本分类准确率
python train.py -c configs/config.yaml
- 如果你想正式在THUCNews数据集上,训练TextCNN文本分类模型,请运行:
python train.py -c configs/config_textfolder.yaml以下是训练代码:
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : 390737991@qq.com
@Date : 2022-09-26 14:50:34
@Brief :
"""
import os
import torch
import argparse
import torch.nn as nn
import numpy as np
import tensorboardX as tensorboard
from tqdm import tqdm
from torch.utils import data as data_utils
from core.dataloader import build_dataset
from core.models import build_models
from core.criterion.build_criterion import get_criterion
from core.utils import torch_tools, metrics, log
from pybaseutils import file_utils, config_utils
from pybaseutils.metrics import class_report
class Trainer(object):
def __init__(self, cfg):
torch_tools.set_env_random_seed()
# 设置输出路径
time = file_utils.get_time()
flag = [n for n in [cfg.net_type, cfg.loss_type, cfg.flag, time] if n]
cfg.work_dir = os.path.join(cfg.work_dir, "_".join(flag))
cfg.model_root = os.path.join(cfg.work_dir, "model")
cfg.log_root = os.path.join(cfg.work_dir, "log")
file_utils.create_dir(cfg.work_dir)
file_utils.create_dir(cfg.model_root)
file_utils.create_dir(cfg.log_root)
file_utils.copy_file_to_dir(cfg.config_file, cfg.work_dir)
config_utils.save_config(cfg, os.path.join(cfg.work_dir, "setup_config.yaml"))
self.cfg = cfg
self.topk = self.cfg.topk
# 配置GPU/CPU运行设备
self.gpu_id = cfg.gpu_id
self.device = torch.device("cuda:".format(cfg.gpu_id[0]) if torch.cuda.is_available() else "cpu")
# 设置Log打印信息
self.logger = log.set_logger(level="debug", logfile=os.path.join(cfg.log_root, "train.log"))
# 构建训练数据和测试数据
self.train_loader = self.build_train_loader()
self.test_loader = self.build_test_loader()
# 构建模型
self.model = self.build_model()
# 构建损失函数
self.criterion = self.build_criterion()
# 构建优化器
self.optimizer = self.build_optimizer()
# 构建学习率调整策略
self.scheduler = torch.optim.lr_scheduler.MultiStepLR(self.optimizer, cfg.milestones)
# 使用tensorboard记录和可视化Loss
self.writer = tensorboard.SummaryWriter(cfg.log_root)
# 打印信息
self.num_samples = len(self.train_loader.sampler)
self.logger.info("=" * 60)
self.logger.info("work_dir :".format(cfg.work_dir))
self.logger.info("config_file :".format(cfg.config_file))
self.logger.info("gpu_id :".format(cfg.gpu_id))
self.logger.info("main device :".format(self.device))
self.logger.info("num_samples(train):".format(self.num_samples))
self.logger.info("num_classes :".format(cfg.num_classes))
self.logger.info("mean_num :".format(self.num_samples / cfg.num_classes))
self.logger.info("=" * 60)
def build_optimizer(self, ):
"""build_optimizer"""
if self.cfg.optim_type.lower() == "SGD".lower():
optimizer = torch.optim.SGD(params=self.model.parameters(), lr=self.cfg.lr,
momentum=self.cfg.momentum, weight_decay=self.cfg.weight_decay)
elif self.cfg.optim_type.lower() == "Adam".lower():
optimizer = torch.optim.Adam(self.model.parameters(), lr=self.cfg.lr, weight_decay=self.cfg.weight_decay)
else:
optimizer = None
return optimizer
def build_train_loader(self, ) -> data_utils.DataLoader:
"""build_train_loader"""
self.logger.info("build_train_loader,context_size:".format(self.cfg.context_size))
dataset = build_dataset.load_dataset(data_type=self.cfg.data_type,
filename=self.cfg.train_data,
vocab_file=self.cfg.vocab_file,
context_size=self.cfg.context_size,
class_name=self.cfg.class_name,
resample=self.cfg.resample,
phase="train",
shuffle=True)
shuffle = True
sampler = None
self.logger.info("use resample:".format(self.cfg.resample))
# if self.cfg.resample:
# weights = torch.DoubleTensor(dataset.classes_weights)
# sampler = torch.utils.data.sampler.WeightedRandomSampler(weights, len(weights))
# shuffle = False
loader = data_utils.DataLoader(dataset=dataset, batch_size=self.cfg.batch_size, sampler=sampler,
shuffle=shuffle, num_workers=self.cfg.num_workers)
self.cfg.num_classes = dataset.num_classes
self.cfg.num_embeddings = dataset.num_embeddings
self.cfg.class_name = dataset.class_name
file_utils.copy_file_to_dir(self.cfg.vocab_file, cfg.work_dir)
return loader
def build_test_loader(self, ) -> data_utils.DataLoader:
"""build_test_loader"""
self.logger.info("build_test_loader,context_size:".format(cfg.context_size))
dataset = build_dataset.load_dataset(data_type=self.cfg.data_type,
filename=self.cfg.test_data,
vocab_file=self.cfg.vocab_file,
context_size=self.cfg.context_size,
class_name=self.cfg.class_name,
phase="test",
resample=False,
shuffle=False)
loader = data_utils.DataLoader(dataset=dataset, batch_size=self.cfg.batch_size,
shuffle=False, num_workers=self.cfg.num_workers)
self.cfg.num_classes = dataset.num_classes
self.cfg.num_embeddings = dataset.num_embeddings
self.cfg.class_name = dataset.class_name
return loader
def build_model(self, ) -> nn.Module:
"""build_model"""
self.logger.info("build_model,net_type:".format(self.cfg.net_type))
model = build_models.get_models(net_type=self.cfg.net_type,
num_classes=self.cfg.num_classes,
num_embeddings=self.cfg.num_embeddings,
embedding_dim=128,
is_train=True,
)
if self.cfg.finetune:
self.logger.info("finetune:".format(self.cfg.finetune))
state_dict = torch_tools.load_state_dict(self.cfg.finetune)
model.load_state_dict(state_dict)
model = model.to(self.device)
model = nn.DataParallel(model, device_ids=self.gpu_id, output_device=self.device)
return model
def build_criterion(self, ):
"""build_criterion"""
self.logger.info(
"build_criterion,loss_type:, num_embeddings:".format(self.cfg.loss_type, self.cfg.num_embeddings))
criterion = get_criterion(self.cfg.loss_type, self.cfg.num_embeddings, device=self.device)
# criterion = torch.nn.CrossEntropyLoss()
return criterion
def train(self, epoch):
"""训练"""
train_losses = metrics.AverageMeter()
train_accuracy = k: metrics.AverageMeter() for k in self.topk
self.model.train() # set to training mode
log_step = max(len(self.train_loader) // cfg.log_freq, 1)
for step, data in enumerate(tqdm(self.train_loader)):
inputs, target = data
inputs, target = inputs.to(self.device), target.to(self.device)
outputs = self.model(inputs)
loss = self.criterion(outputs, target)
self.optimizer.zero_grad() # 反馈
loss.backward()
self.optimizer.step() # 更新
train_losses.update(loss.cpu().data.item())
# 计算准确率
target = target.cpu()
outputs = outputs.cpu()
outputs = torch.nn.functional.softmax(outputs, dim=1)
pred_score, pred_index = torch.max(outputs, dim=1)
acc = metrics.accuracy(outputs.data, target, topk=self.topk)
for i in range(len(self.topk)):
train_accuracy[self.topk[i]].update(acc[i].data.item(), target.size(0))
if step % log_step == 0:
lr = self.scheduler.get_last_lr()[0] # 获得当前学习率
topk_acc = "top".format(k): v.avg for k, v in train_accuracy.items()
self.logger.info(
"train /epoch::0=3d,lr::3.4f,loss::3.4f,acc:".format(step, epoch, lr, train_losses.avg,
topk_acc))
topk_acc = "top".format(k): v.avg for k, v in train_accuracy.items()
self.writer.add_scalar("train-loss", train_losses.avg, epoch)
self.writer.add_scalars("train-accuracy", topk_acc, epoch)
self.logger.info("train epoch::0=3d,loss::3.4f,acc:".format(epoch, train_losses.avg, topk_acc))
return topk_acc["top".format(self.topk[0])]
def test(self, epoch):
"""测试"""
test_losses = metrics.AverageMeter()
test_accuracy = k: metrics.AverageMeter() for k in self.topk
true_labels = np.ones(0)
pred_labels = np.ones(0)
self.model.eval() # set to evaluates mode
with torch.no_grad():
for step, data in enumerate(tqdm(self.test_loader)):
inputs, target = data
inputs, target = inputs.to(self.device), target.to(self.device)
outputs = self.model(inputs)
loss = self.criterion(outputs, target)
test_losses.update(loss.cpu().data.item())
# 计算准确率
target = target.cpu()
outputs = outputs.cpu()
outputs = torch.nn.functional.softmax(outputs, dim=1)
pred_score, pred_index = torch.max(outputs, dim=1)
acc = metrics.accuracy(outputs.data, target, topk=self.topk)
true_labels = np.hstack([true_labels, target.numpy()])
pred_labels = np.hstack([pred_labels, pred_index.numpy()])
for i in range(len(self.topk)):
test_accuracy[self.topk[i]].update(acc[i].data.item(), target.size(0))
report = class_report.get_classification_report(true_labels, pred_labels, target_names=self.cfg.class_name)
topk_acc = "top".format(k): v.avg for k, v in test_accuracy.items()
lr = self.scheduler.get_last_lr()[0] # 获得当前学习率
self.writer.add_scalar("test-loss", test_losses.avg, epoch)
self.writer.add_scalars("test-accuracy", topk_acc, epoch)
self.logger.info("test epoch::0=3d,lr::3.4f,loss::3.4f,acc:".format(epoch, lr, test_losses.avg, topk_acc))
self.logger.info("".format(report))
return topk_acc["top".format(self.topk[0])]
def run(self):
"""开始运行"""
self.max_acc = 0.0
for epoch in range(self.cfg.num_epochs):
train_acc = self.train(epoch) # 训练模型
test_acc = self.test(epoch) # 测试模型
self.scheduler.step() # 更新学习率
lr = self.scheduler.get_last_lr()[0] # 获得当前学习率
self.writer.add_scalar("lr", lr, epoch)
self.save_model(self.cfg.model_root, test_acc, epoch)
self.logger.info("epoch:, lr:, train acc::3.4f, test acc::3.4f".
format(epoch, lr, train_acc, test_acc))
def save_model(self, model_root, value, epoch):
"""保存模型"""
# 保存最优的模型
if value >= self.max_acc:
self.max_acc = value
model_file = os.path.join(model_root, "best_model_:0=3d_:.4f.pth".format(epoch, value))
file_utils.remove_prefix_files(model_root, "best_model_*")
torch.save(self.model.module.state_dict(), model_file)
self.logger.info("save best model file:".format(model_file))
# 保存最新的模型
name = "model_:0=3d_:.4f.pth".format(epoch, value)
model_file = os.path.join(model_root, "latest_".format(name))
file_utils.remove_prefix_files(model_root, "latest_*")
torch.save(self.model.module.state_dict(), model_file)
self.logger.info("save latest model file:".format(model_file))
self.logger.info("-------------------------" * 4)
def get_parser():
# cfg_file = "configs/config_textfolder.yaml"
cfg_file = "configs/config.yaml"
parser = argparse.ArgumentParser(description="Training Pipeline")
parser.add_argument("-c", "--config_file", help="configs file", default=cfg_file, type=str)
cfg = config_utils.parser_config(parser.parse_args(), cfg_updata=True)
return cfg
if __name__ == "__main__":
cfg = get_parser()
train = Trainer(cfg)
train.run()
(5)可视化训练过程
训练过程可视化工具是使用Tensorboard,使用方法:
# 基本方法
tensorboard --logdir=path/to/log/
# 例如(请修改自己的训练的模型路径)
tensorboard --logdir=work_space/TextCNN_CELoss_20230106152138/log
可视化效果
 |  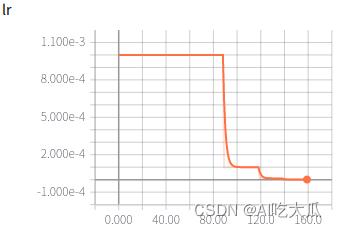 |
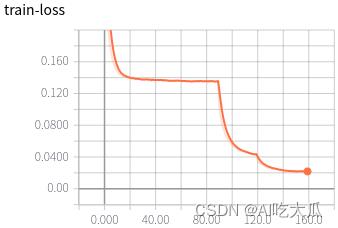 |  |
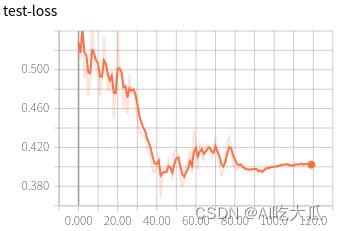 |  |
(6)一些优化建议
训练完成后,目前,基于TextCNN的文本分类识别,在THUCNews数据集上,训练集的Accuracy 99%左右,测试集的Accuracy在88.36%左右;如果想进一步提高准确率,可以尝试:
- 数据整合:部分分类之间本身模棱两可,例如体育和娱乐、教育和科技本身类别就有很多相似之处,导致模型分类困难;THUCNews数据量虽然庞大,但不是十分干净,有很多脏数据;建议你,训练前,清洗或整合部分数据集,不然会影响模型的识别的准确率。
- 增加TextCNN参数量:比如将TextCNN的num_channels设置大一点;当然模型越复杂,越容易过拟合;
- 增加pretrained模型:项目构建TextCNN模型,随机初始化了一个可学习的二维矩阵:Embedding,该Embedding模型没有增加pretrained的,若能加入pretrained,其准确率会好很多。
- 文本数据增强:如同义词替换,文本随机插入,随机删除等处理,增强模型泛化能力
- 样本均衡:数据不均衡,部分类目数据太少; 建议进行样本均衡处理,减少长尾问题的影响
- 超参调优: 比如学习率调整策略,优化器(SGD,Adam等)
- 损失函数: 目前训练代码已经支持:交叉熵,LabelSmoothing,可以尝试FocalLoss等损失函数
七. 模型测试效果
classifier.py文件用于模型推理和测试脚本,填写好配置文件,模型文件以及测试文本路径即可运行测试了
def get_parser():
model_file = "work_space/TextCNN_CELoss_20221226114529/model/latest_model_159_0.8714.pth"
config_file = os.path.join(os.path.dirname(os.path.dirname(model_file)), "config_textfolder.yaml")
vocab_file = os.path.join(os.path.dirname(os.path.dirname(model_file)), "vocabulary.json")
text_dir = "data/test-text"
parser = argparse.ArgumentParser(description="Inference Argument")
parser.add_argument("-c", "--config_file", help="configs file", default=config_file, type=str)
parser.add_argument("-m", "--model_file", help="model_file", default=model_file, type=str)
parser.add_argument("-v", "--vocab_file", help="vocab_file", default=vocab_file, type=str)
parser.add_argument("--device", help="cuda device id", default="cuda:0", type=str)
parser.add_argument("--text_dir", help="text", default=text_dir, type=str)
return parser在项目根目录终端运行命令(\\表示换行符):
#!/usr/bin/env bash
# Usage:
# python classifier.py -c "path/to/config.yaml" -m "path/to/model.pth" -v "path/to/vocabulary.json" --text_dir "path/to/text_dir"
python classifier.py \\
-c "work_space/TextCNN_CELoss_20221226114529/config_textfolder.yaml" \\
-m "work_space/TextCNN_CELoss_20221226114529/model/latest_model_159_0.8714.pth" \\
-v "work_space/TextCNN_CELoss_20221226114529/vocabulary.json" \\
--text_dir "data/test-text"运行测试结果:
