python数据挖掘——文本分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python数据挖掘——文本分析相关的知识,希望对你有一定的参考价值。
作者 | zhouyue65 来源 | 君泉计量 文本挖掘:从大量文本数据中抽取出有价值的知识,并且利用这些知识重新组织信息的过程。 一
参考技术A作者 | zhouyue65
来源 | 君泉计量
文本挖掘:从大量文本数据中抽取出有价值的知识,并且利用这些知识重新组织信息的过程。
一、语料库(Corpus)
语料库是我们要分析的所有文档的集合。
二、中文分词
2.1 概念:
中文分词(Chinese Word Segmentation):将一个汉字序列切分成一个一个单独的词。
eg:我的家乡是广东省湛江市-->我/的/家乡/是/广东省/湛江市
停用词(Stop Words):
数据处理时,需要过滤掉某些字或词
√泛滥的词,如web、网站等。
√语气助词、副词、介词、连接词等,如 的,地,得;
2.2 安装Jieba分词包:
最简单的方法是用CMD直接安装:输入pip install jieba,但是我的电脑上好像不行。
后来在这里:https://pypi.org/project/jieba/#files下载了jieba0.39解压缩后 放在Python36Libsite-packages里面,然后在用cmd,pip install jieba 就下载成功了,不知道是是什么原因。
然后我再anaconda 环境下也安装了jieba,先在Anaconda3Lib这个目录下将jieba0.39的解压缩文件放在里面,然后在Anaconda propt下输入 pip install jieba,如下图:
2.3 代码实战:
jieba最主要的方法是cut方法:
jieba.cut方法接受两个输入参数:
1) 第一个参数为需要分词的字符串
2)cut_all参数用来控制是否采用全模式
jieba.cut_for_search方法接受一个参数:需要分词的字符串,该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
注意:待分词的字符串可以是gbk字符串、utf-8字符串或者unicode
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(unicode),也可以用list(jieba.cut(...))转化为list代码示例( 分词 )
输出结果为: 我 爱
Python
工信处
女干事
每月 经过 下属 科室 都 要 亲口
交代
24 口 交换机 等 技术性 器件 的 安装
工作
分词功能用于专业的场景:
会出现真武七截阵和天罡北斗阵被分成几个词。为了改善这个现象,我们用导入词库的方法。
但是,如果需要导入的单词很多,jieba.add_word()这样的添加词库的方法就不高效了。
我们可以用jieba.load_userdict(‘D:PDM2.2金庸武功招式.txt’)方法一次性导入整个词库,txt文件中为每行一个特定的词。
2.3.1 对大量文章进行分词
先搭建语料库:
分词后我们需要对信息处理,就是这个分词来源于哪个文章。
四、词频统计
3.1词频(Term Frequency):
某个词在该文档中出现的次数。
3.2利用Python进行词频统计
3.2.1 移除停用词的另一种方法,加if判断
代码中用到的一些常用方法:
分组统计:
判断一个数据框中的某一列的值是否包含一个数组中的任意一个值:
取反:(对布尔值)
四、词云绘制
词云(Word Cloud):是对文本中词频较高的分词,给与视觉上的突出,形成“关键词渲染”,从而国旅掉大量的文本信息,使浏览者一眼扫过就可以领略文本的主旨。
4.1 安装词云工具包
这个地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/ ,可以搜到基本上所有的Python库,进去根据自己的系统和Python的版本进行下载即可。
在python下安装很方便,在anaconda下安装费了点劲,最终将词云的文件放在C:UsersAdministrator 这个目录下才安装成功。
五、美化词云(词云放入某图片形象中)
六、关键词提取
结果如下:
七、关键词提取实现
词频(Term Frequency):指的是某一个给定的词在该文档中出现的次数。
计算公式: TF = 该次在文档中出现的次数
逆文档频率(Inverse Document Frequency):IDF就是每个词的权重,它的大小与一个词的常见程度成反比
计算公式:IDF = log(文档总数/(包含该词的文档数 - 1))
TF-IDF(Term Frequency-Inverse Document Frequency):权衡某个分词是否关键词的指标,该值越大,是关键词的可能性就越大。
计算公式:TF - IDF = TF * IDF
7.1文档向量化
7.2代码实战
Python——用户评论情绪分析
介绍
在该节中我们将对用户产生的真实评论数据进行情绪分析。
知识点
- 文本分词
- Word2Vec 方法
- 决策树分类
本文所涉及到情绪分析,又称为文本情绪分析,这是自然语言处理和文本挖掘过程中涉及到的一块内容。简而言之,我们通过算法去判断一段文本、评论的情绪偏向,从而快速地了解表达这段文本的原作者的主观情绪。
现实中,当我们在陈述一段内容时,可能会出现的情绪有:高兴、兴奋、激动、没感觉、失落、压抑、紧张、疑惑等。而在自然语言处理的世界里,我们尚且达不到如此细小的分类。所以,往往在针对文本进行情绪分析时,只处理两种情绪状态:积极和消极。
当然,上面提到的计算机无法处理更细分的情绪类别其实并不准确。因为,算法原则上是能够区分更多的情绪类别,关键在于我们需要提供一个人工标注过的复杂情绪训练集,而这是非常难做到的。所以,目前我们在进行情绪分析时,只处理积极和消极两种状态。
基于词典的方法
目前,针对文本情绪分析的方法有两种,一种基于词典,另一种基于机器学习方法。首先,我们来叙述一下基于词典的文本情绪分析原理。
基于词典的情绪分析是非常简单和易于理解的一种方法。概括来讲,我们首先有一个人工标注好的词典。词典中的每一个此都对应这消极或积极的标签。词典举例如下:
| 词语 | 标签 |
|---|---|
| 很好 | 积极 |
| 不好 | 消极 |
| 高兴 | 积极 |
| 难受 | 消极 |
| 爱你 | 积极 |
| 讨厌 | 消极 |
| …… | …… |
然后,这个词典可能有上万条或者几十万条,当然是越多越好。有了词典之后,我们就可以开始进行文本情绪分析了。
现在,我们收到一条用户评论:
这门课程很好啊!
然后,我们可以对这句话进行分词。分词结果如下:
[‘这门‘, ‘课程‘, ‘很‘, ‘好‘, ‘啊‘, ‘!‘]
接下来,我们拿分好的词依次去匹配词典。匹配的方法很简单:
- 如果词典中存在该词且为积极标签,那么我们记 +1+1;
- 如果词典中存在该词且为消极标签,那么我们记 -1?1;
- 如果词典中不存在该词,我们记 00。
匹配完一个句子之后,我们就可以计算整个句子的得分。总得分 >0>0 表示该句子情绪为积极,总得分小于零代表该句子为消极,总得分 =0=0 表示无法判断情绪。通过词典进行情绪分析的方法很简单,但缺点也很明显。我们往往需要一个很大的词典,且不断更新。这对人力物力都是极大的考验。
除此之外,该方法还有无法通过扩充词典解决的情绪判断问题。例如,当我们人类在判断一句话的清晰时,我们会往往更偏向于从整体把握(语言环境),尤其是在乎一些语气助词对情绪的影响。而基于词典进行情绪分析的方法就做不到这一点,将句子拆成词,就会影响句子的整体情绪表达。
目前,针对中文做情绪标注的词典少之又少。比较常用的有:
- 台湾大学 NTUSD 情绪词典。
- 《知网》情绪分析用 词语集。
以《知网》情绪词典举例,它包含有 5 个文件,分别列述了正面与负面的情绪词语以及程度词汇。
- “正面情感”词语,如:爱,赞赏,快乐,感同身受,好奇,喝彩,魂牵梦萦,嘉许 ...
- “负面情感”词语,如:哀伤,半信半疑,鄙视,不满意,不是滋味儿,后悔,大失所望 ...
- “正面评价”词语,如:不可或缺,部优,才高八斗,沉鱼落雁,催人奋进,动听,对劲儿 ...
- “负面评价”词语,如:丑,苦,超标,华而不实,荒凉,混浊,畸轻畸重,价高,空洞无物 ...
- “程度级别”词语,
- “主张”词语
由于上面介绍的这种简单的词典对比方法准确率并不高,所以本不会通过这种方法来实现用户评论情绪分析。
基于词袋或 Word2Vec 的方法
词袋模型
除了基于词典对评论进行情绪分析,我们还有一种方法称之为词袋模型。词袋不再将一句话看做是单个词汇构成,而是当作一个 1 imes N1×N 的向量。举个例子,我们现在有两句话需要处理,分别是:
我爱你,我非常爱你。 我喜欢你,我非常喜欢你。
我们针对这两句话进行分词之后,去重处理为一个词袋:
[‘我‘, ‘爱‘, ‘喜欢‘, ‘你‘, ‘非常‘]
然后,根据词袋,我们对原句子进行向量转换。其中,向量的长度 N 为词袋的长度,而向量中每一个数值依次为词袋中的词出现在该句子中的次数。
我爱你,我非常爱你。 → [2, 2, 0, 2, 1]
我喜欢你,我非常喜欢你。 → [2, 0, 2, 2, 1]
有了词袋,有了已经人工标注好的句子,就组成了我们的训练数据。再根据机器学习方法来构建分类预测模型。从而判断新输入句子的情绪。
你会发现,词袋模型和我们之前提到的独热编码非常相似。其实这里就是将之前独热编码里的词变成了句子而已。
词袋模型固然比简单的词典对比方法更好,但独热编码无法度量上下文之间的距离,也就无法结合上下文进行情绪判断。下面,我们介绍一种词向量的 Word2Vec 处理方法,就会很好地克服这个缺点。
Word2Vec
Word2Vec,故名思意就是将句子转换为向量,也就是词向量。Word2Vec 最早由 Google 在 2013 年开源,它是由浅层神经网络组成的词向量转换模型。
Word2Vec 的输入一般为规模庞大的语料库,输出为向量空间。Word2Vec 的特点在于,语料库中的每个词都对应了向量空间中的一个向量,拥有上下文关系的词,映射到向量空间中的距离会更加接近。
Word2Vec 的主要结构是 CBOW(Continuous Bag-of-Words Model)模型和 Skip-gram(Continuous Skip-gram)模型结合在一起。简单来讲,二者都是想通过上下文得到一个词出现的概率。
CBOW 模型通过一个词的上下文(各 N 个词)预测当前词。而 Skip-gram 则恰好相反,他是用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。
CBOW(N=2)和 Skip-gram 的结构如下图所示:
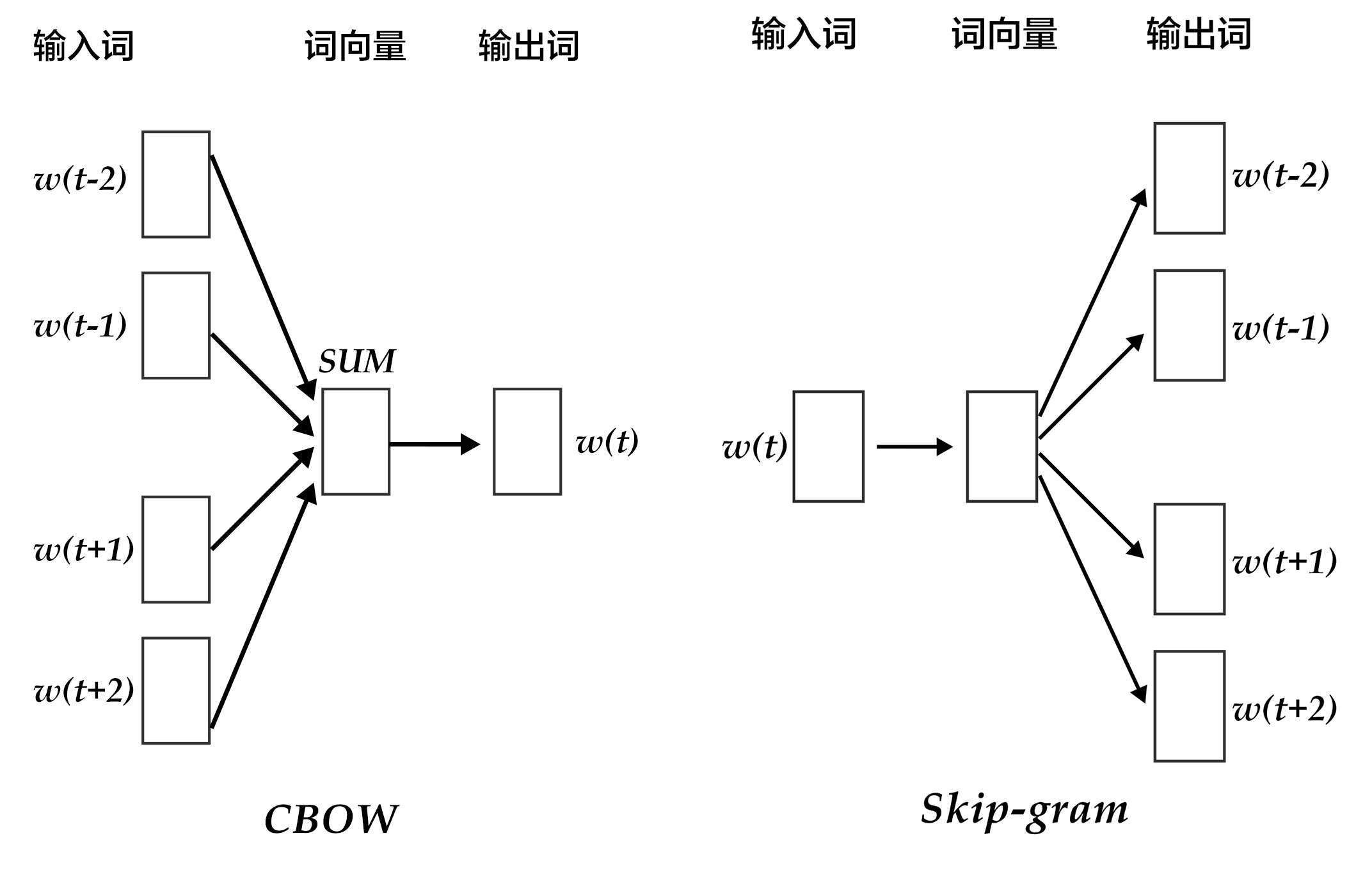
图中 w(t)w(t) 表示当前的词汇,而 w(t?n)w(t?n),w(t+n)w(t+n) 等则用来表示上下文词汇。
用户评论情绪分析
为了保证良好的准确度,本次我们选用了 Word2Vec 结合决策树的文本情绪分析方法。首先,我们需要使用 Word2Vec 来建立向量空间,之后再使用决策树训练文本情绪分类模型。
由于我们未人工针对评论进行语料库标注,所以这里需要选择其他的已标注语料库进行模型训练。这里,我们选用了网友苏剑林提供的语料库。该语料库整合了书籍、计算机等 7 个领域的评论数据。
你可以通过下面网盘链接下载本次所需要的数据集:
链接:https://pan.baidu.com/s/1qpy23EDHG2rea9SzxphIsQ 提取码:g837
三个数据文件的预览如下。
其中,消极情绪文本 neg.xls 共有 10428 行。
import pandas as pd
pd.read_excel("data_09/data/neg.xls", header=None).head()积极情绪文本 pos.xls 共有 10679 行。
pd.read_excel("data_09/data/pos.xls", header=None).head()用户评论文本 comments.csv 共有 12377 行。
pd.read_csv("data_09/comments.csv").head()语料库分词处理
在使用 Word2Vec 之前,我们需要先对训练语料库进行分词处理。这里依旧使用 jieba 分词。
import jieba
import numpy as np
# 加载语料库文件,并导入数据
neg = pd.read_excel('data_09/data/neg.xls', header=None, index=None)
pos = pd.read_excel('data_09/data/pos.xls', header=None, index=None)
# jieba 分词
def word_cut(x): return jieba.lcut(x)
pos['words'] = pos[0].apply(word_cut)
neg['words'] = neg[0].apply(word_cut)
# 使用 1 表示积极情绪,0 表示消极情绪,并完成数组拼接
x = np.concatenate((pos['words'], neg['words']))
y = np.concatenate((np.ones(len(pos)), np.zeros(len(neg))))
# 将 Ndarray 保存为二进制文件备用
np.save('X_train.npy', x)
np.save('y_train.npy', y)
print('done.')
你可以预览一下数组的形状,以 x 为例:
np.load('X_train.npy', allow_pickle=True)Word2Vec 处理
有了分词之后的数组,我们就可以开始 Word2Vec 处理,将其转换为词向量了。目前,很多开源工具都提供了 Word2Vec 方法,比如 Gensim,TensorFlow,PaddlePaddle 等。这里我们使用 Gensim。
from gensim.models.word2vec import Word2Vec
import warnings
warnings.filterwarnings('ignore') # 忽略警告
# 导入上面保存的分词数组
X_train = np.load('X_train.npy', allow_pickle=True)
# 训练 Word2Vec 浅层神经网络模型
w2v = Word2Vec(size=300, min_count=10)
w2v.build_vocab(X_train)
w2v.train(X_train, total_examples=w2v.corpus_count, epochs=w2v.epochs)
def sum_vec(text):
# 对每个句子的词向量进行求和计算
vec = np.zeros(300).reshape((1, 300))
for word in text:
try:
vec += w2v[word].reshape((1, 300))
except KeyError:
continue
return vec
# 将词向量保存为 Ndarray
train_vec = np.concatenate([sum_vec(z) for z in X_train])
# 保存 Word2Vec 模型及词向量
w2v.save('w2v_model.pkl')
np.save('X_train_vec.npy', train_vec)
print('done.')Word2Vec 过程可能需要几分钟。
训练情绪分类模型
有了词向量,我们就有了机器学习模型的输入,那么就可以训练情绪分类模型。这一块内容你应该很熟悉,选择速度较快的决策树方法,并使用 scikit-learn 完成。
from sklearn.externals import joblib
from sklearn.tree import DecisionTreeClassifier
# 导入词向量为训练特征
X = np.load('X_train_vec.npy')
# 导入情绪分类作为目标特征
y = np.load('y_train.npy')
# 构建支持向量机分类模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X, y)
# 保存模型为二进制文件
joblib.dump(model, 'dt_model.pkl')执行决策树分类,该过程持续时间较长。
对评判进行情绪判断
有了 Word2Vec 模型以及支持向量机情绪分类模型。接下来,我们就可以对的用户评论进行情绪预测了。
# 读取 Word2Vec 并对新输入进行词向量计算
def sum_vec(words):
# 读取 Word2Vec 模型
w2v = Word2Vec.load('w2v_model.pkl')
vec = np.zeros(300).reshape((1, 300))
for word in words:
try:
vec += w2v[word].reshape((1, 300))
except KeyError:
continue
return vec对评论进行情绪判断:
# 读取评论
df = pd.read_csv("data_09/comments.csv", header=0)
comment_sentiment = []
for string in df['评论内容']:
# 对评论分词
words = jieba.lcut(str(string))
words_vec = sum_vec(words)
# 读取支持向量机模型
model = joblib.load('dt_model.pkl')
result = model.predict(words_vec)
comment_sentiment.append(result[0])
# 实时返回积极或消极结果
if int(result[0]) == 1:
print(string, '[积极]')
else:
print(string, '[消极]')
# 将情绪结果合并到原数据文件中
merged = pd.concat([df, pd.Series(comment_sentiment, name='用户情绪')], axis=1)
pd.DataFrame.to_csv(merged, 'comment_sentiment.csv') # 储存文件以备后用最后,我们可以通过饼状图看一下用户的情绪分布。总体看来,73% 都为积极评论,正能量满满。
总结
本章节,我们使用机器学习方法对用户真实评论进行了情绪分析。内容涉及比较多,尤其是 Word2Vec 处理。鉴于本课程的目的,我们并没有针对 Word2Vec 进行太详细的介绍。如果你对自然语言处理感兴趣,Word2Vec 一定是需要理解透彻的方法。除了使用机器学习方法,在文本情绪分析时。我们往往会用到 LSTM(Long Short Term Memory networks)长短期记忆递归神经网络训练分类模型,在大规模语料数据中,应用效果可能会更优于支持向量机等方法。学有余力时,也可以自行了解学习。
除此之外,由于本次所用语料库来源于第三方购物网站的评论。所以,其训练的模型在预测用户情绪方面,可能并没有太好的泛化能力。如果能针对现有数据进行人工标注,对于预测以后的数据,结果应该会更好。
以上是关于python数据挖掘——文本分析的主要内容,如果未能解决你的问题,请参考以下文章