计算机视觉算法——基于深度学习的高精地图算法(HDMapNet / VectorMapNet / MapTR / VectorNet)
Posted Leo-Peng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉算法——基于深度学习的高精地图算法(HDMapNet / VectorMapNet / MapTR / VectorNet)相关的知识,希望对你有一定的参考价值。
计算机视觉算法——基于深度学习的高精地图算法(HDMapNet / VectorMapNet / MapTR / VectorNet)
- 计算机视觉算法——基于深度学习的高精地图算法(HDMapNet / VectorMapNet / MapTR / VectorNet)
计算机视觉算法——基于深度学习的高精地图算法(HDMapNet / VectorMapNet / MapTR / VectorNet)
高精地图广泛应用于自动驾驶领域,传统的高精地图构建和使用算法通常是基于SLAM实现的,但是最近两年出现了很多基于深度学习的方法,例如HDMapNet、VectorMapNet和MapTR就介绍了如何通过NN直接利用感知信息构建矢量化的高精地图,而VectorNet介绍了如何使用NN直接对矢量化的高精地图信息进行编码,从而能高效地作为一路输入被系统所利用。下面
1. HDMapNet
HDMapNet为2021年发表的文章,原论文名为《HDMapNet: An Online HD Map Construction and Evaluation Framework》,该论文的主要目的是利用自动驾驶车辆上的环视相机和激光雷达对BEV视角下的地图元素进行矢量化。
1.1 网络结构及特点
网络结构如下图所示:
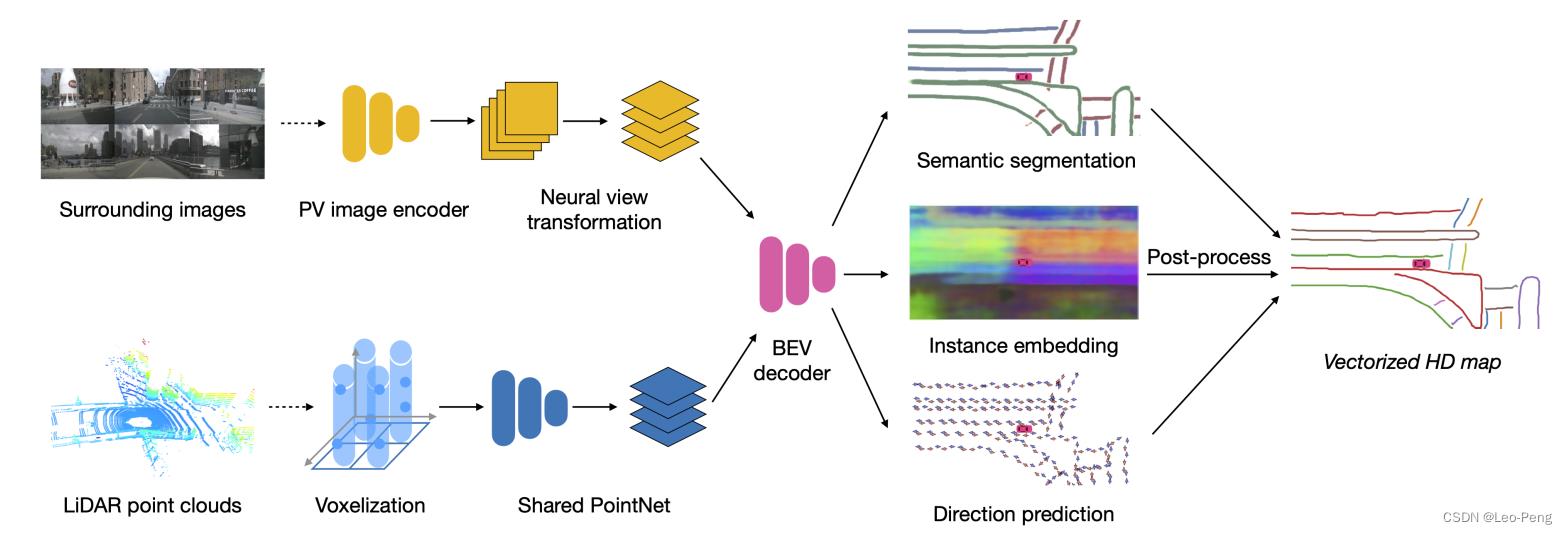
整个网络结构主要有Image and Point Cloud Encoder和Bird’s-eye View Decoder构成,输出分割结构后通过后处理输出结构化地图元素。
1.1.1 Image and Point Cloud Encoder
相机输入图片通过一个权重共享的特征提取网络编码为特征图 F I i p v ⊆ R H p v × W p v × K \\mathcalF_\\mathcalI_i^\\mathrmpv \\subseteq \\mathbbR^H_\\mathrmpv \\times W_\\mathrmpv \\times K FIipv⊆RHpv×Wpv×K,然后通过MLP将特征图映射到BEV下,方法类似VPN,不同的是在本论文中显示地使用了相机的外参: F I i c [ h ] [ w ] = ϕ V i h w ( F I i p v [ 1 ] [ 1 ] , … , F I i p v [ H p v ] [ W p v ] ) \\mathcalF_\\mathcalI_i^c[h][w]=\\phi_\\mathcalV_i^h w\\left(\\mathcalF_\\mathcalI_i^\\mathrmpv[1][1], \\ldots, \\mathcalF_\\mathcalI_i^\\mathrmpv\\left[H_\\mathrmpv\\right]\\left[W_\\mathrmpv\\right]\\right) FIic[h][w]=ϕVihw(FIipv[1][1],…,FIipv[Hpv][Wpv])其中 ϕ V i h w \\phi_\\mathcalV_i^h w ϕVihw建立了从前视图特征到BEV特征的映射关系,最后在BEV下通过相机的外参将各个相机的特征进行加权平均。
激光的编码使用的PointPillar的方法,首先将三维空间划分为多个Pillar,使用PointNet将同一个Pillar中的激光点处理成特征: f j pillar = PN ( f p ∣ ∀ p ∈ P j ) f_j^\\text pillar =\\operatornamePN\\left(\\left\\f_p \\mid \\forall p \\in P_j\\right\\\\right) fjpillar =PN(fp∣∀p∈Pj)最后通过卷积网络 ϕ pillar \\phi_\\text pillar ϕpillar 在BEV下对Pillar进行进一步特征提取得到 F P b e v \\mathcalF_P^\\mathrmbev FPbev。
1.1.3 Bird’s-eye View Decoder
解码部分使用的Backbone是FCN,然后接三个输出头,其中第一个输出头进行车道语义分割;第二个输出头进行车道实例分割;第三输出头进行车道方向预测,这里我们详细介绍下车道实例分割和车道方向预测的设计:
车道实例分割是基于Instance Embedding实现,即同一个车道实例网络应该输出相同或接近的Instance Embedding,Instance Embedding的Loss定义如下:
L
v
a
r
=
1
C
∑
c
=
1
C
1
N
c
∑
j
=
1
N
c
[
∥
μ
c
−
f
j
i
n
s
t
a
n
c
e
∥
−
δ
v
]
+
2
L_v a r=\\frac1C \\sum_c =1^C \\frac1N_c \\sum_j=1^N_c\\left[\\left\\|\\mu_c-f_j^\\mathrminstance\\right\\|-\\delta_v\\right]_+^2
Lvar=C1c=1∑CNc1j=1∑Nc[
μc−fjinstance
−δv]+2
L
d
i
s
t
=
1
C
(
C
−
1
)
∑
c
A
≠
c
B
∈
C
[
2
δ
d
−
∥
μ
c
A
−
μ
c
B
∥
]
+
2
,
L_d i s t=\\frac1C(C-1) \\sum_c_A \\neq c_B \\in C\\left[2 \\delta_d-\\left\\|\\mu_c_A-\\mu_c_B\\right\\|\\right]_+^2,
Ldist=C(C−1)1cA=cB∈C∑[2δd−∥μcA−μcB∥]+2,
L
=
α
L
v
a
r
+
β
L
dist
.
L=\\alpha L_v a r+\\beta L_\\text dist .
L=αLvar+βLdist .其中
L
v
a
r
L_v a r
Lvar为方差损失,
L
d
i
s
t
L_d i s t
Ldist为距离损失。
C
C
C为真值中车道实例的个数,
f
j
i
n
s
t
a
n
c
e
f_j^\\mathrminstance
fjinstance为第
j
j
j个预测为实例
c
c
c的Instance Embedding,
N
c
N_c
Nc为预测为第c个车道实例中的像素个数,
μ
c
\\mu_c