YOLO(一) 算法的原理及演变
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLO(一) 算法的原理及演变相关的知识,希望对你有一定的参考价值。
参考技术A第一次接触到yolo这个算法是通过吴恩达的教学视频了解到的,当时其实也算是第一次接触到目标检测算法。这里我们主要介绍下YOLO(You Only Look Once)。现在已经进化到了V3版本了。它不同于Faster RCNN这个分支走的两部策略先进行前景识别在进行目标检测,它是直接一步到位进行目标检测。因此在识别的速度上优于Faster RCNN(5 FPS), 而 YOLO_v1基础版在Titan X GPU上可以达到45帧/s; 快速版可以达到150帧/s。但是在准确率上YOLO是稍差与Faster RCNN这个在之后会详细介绍。顺便提下如果想了解Faster RCNN原理可以参考 Faster-RCNN的原理及演变 。
我们知道YOLO其实就是 You Only Look Once, 意思是只需要看一眼就知道位置及对象,个人觉得蛮形象的。他不需要Faster RCNN的RPN结构,他其实选取anchor是预订了候选框,将图片划分为7x7的网格,每个网格允许有2个不同的bounding box. 这样一开始我们就有7x7x2个候选框(bounding box), 大致粗略覆盖了图像的整个区域。他的思想就是Faster RCNN在第一阶段就算有了回归框,在第二阶段还是需要进行精调,那还不如就先生成大致回归框就ok了。
下面我们就来好好介绍一下这个模型。
一、模型结构
其实将这个模型简单话为:
那30又是如何形成的通道大小的呢?
a. 2个bounding box的位置(8个通道)
每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,bounding box的宽度,高度),2个bounding box共需要8个数值来表示其位置。
b. 2个bounding box 置信度(2个通道)
c. 20分类概率(20个通道)
下面我们来说一下剩下20维度的分类通道。每一个通道代表一个类别的分类概率。因为YOLO支持识别20种不同的对象(人、鸟、猫、汽车、椅子等),所以这里有20个值表示该网格位置存在任一种对象的概率。 但是我们一组图片只能预测49个对象,可以理解为一个grid2个achor只能有一个预测准的对象(即计算IOU比例最大的那个anchor),所以7x7个对象 。
图中将自行车的位置放在bounding box1,但实际上是在训练过程中等网络输出以后,比较两个bounding box与自行车实际位置的IOU,自行车的位置(实际bounding box)放置在IOU比较大的那个bounding box(图中假设是bounding box1),且该bounding box的置信度设为1
二、 损失函数
总的来说,就是用网络输出与样本标签的各项内容的误差平方和作为一个样本的整体误差。
损失函数中的几个项是与输出的30维向量中的内容相对应的。
三、 YOLO v1 缺陷
注意:
细节:
YOLO的最后一层采用线性激活函数,其它层都是Leaky ReLU。训练中采用了drop out和数据增强(data augmentation)来防止过拟合。更多细节请参考原论文
在67 FPS,YOLOv2在PASCAL VOC 2007上获得76.8%的mAP。在40 FPS时,YOLOv2获得78.6%mAP,这比使用ResNet和SSD 更快的R-CNN更好。凭借如此优异的成绩,YOLOv2于2017年CVPR发布并获得超过1000次引用。YOLO有两个缺点:一个缺点在于定位不准确,另一个缺点在于和基于region proposal的方法相比召回率较低。因此YOLOv2主要是要在这两方面做提升。另外YOLOv2并不是通过加深或加宽网络达到效果提升,反而是简化了网络。
下面主要从两点来介绍下YOLO v2的提升之处。分别是Better以及Faster.
1、Darknet-19
在YOLO v1中,作者采用的训练网络是基于GooleNet,这里作者将GooleNet和VGG16做了简单的对比,GooleNet在计算复杂度上要优于VGG16(8.25 billion operation VS 30.69 billion operation),但是前者在ImageNet上的top-5准确率要稍低于后者(88% VS 90%)。而在YOLO v2中,作者采用了新的分类模型作为基础网络,那就是Darknet-19。Table6是最后的网络结构:Darknet-19只需要5.58 billion operation。这个网络包含19个卷积层和5个max pooling层,而在YOLO v1中采用的GooleNet,包含24个卷积层和2个全连接层,因此Darknet-19整体上卷积卷积操作比YOLO v1中用的GoogleNet要少,这是计算量减少的关键。最后用average pooling层代替全连接层进行预测。这个网络在ImageNet上取得了top-5的91.2%的准确率。
2、Training for Classification
这里的2和3部分在前面有提到,就是训练处理的小trick。这里的training for classification都是在ImageNet上进行预训练,主要分两步:1、从头开始训练Darknet-19,数据集是ImageNet,训练160个epoch,输入图像的大小是224 224,初始学习率为0.1。另外在训练的时候采用了标准的数据增加方式比如随机裁剪,旋转以及色度,亮度的调整等。2、再fine-tuning 网络,这时候采用448 448的输入,参数的除了epoch和learning rate改变外,其他都没变,这里learning rate改为0.001,并训练10个epoch。结果表明fine-tuning后的top-1准确率为76.5%,top-5准确率为93.3%,而如果按照原来的训练方式,Darknet-19的top-1准确率是72.9%,top-5准确率为91.2%。因此可以看出第1,2两步分别从网络结构和训练方式两方面入手提高了主网络的分类准确率。
3、Training for Detection
在前面第2步之后,就开始把网络移植到detection,并开始基于检测的数据再进行fine-tuning。首先把最后一个卷积层去掉,然后添加3个3 3的卷积层,每个卷积层有1024个filter,而且每个后面都连接一个1 1的卷积层,1 1卷积的filter个数根据需要检测的类来定。比如对于VOC数据,由于每个grid cell我们需要预测5个box,每个box有5个坐标值和20个类别值,所以每个grid cell有125个filter(与YOLOv1不同,在YOLOv1中每个grid cell有30个filter,还记得那个7 7 30的矩阵吗,而且在YOLOv1中,类别概率是由grid cell来预测的,也就是说一个grid cell对应的两个box的类别概率是一样的,但是在YOLOv2中,类别概率是属于box的,每个box对应一个类别概率,而不是由grid cell决定,因此这边每个box对应25个预测值(5个坐标加20个类别值),而在YOLOv1中一个grid cell的两个box的20个类别值是一样的)。另外作者还提到将最后一个3 3*512的卷积层和倒数第二个卷积层相连。最后作者在检测数据集上fine tune这个预训练模型160个epoch,学习率采用0.001,并且在第60和90epoch的时候将学习率除以10,weight decay采用0.0005。
这里yolo v3相对于yolo v2有三点:1. 利用多尺度特征进行对象检测 2. 调整基础网络结构
yolo算法是啥?
Yolo是一种目标检测算法。
目标检测的任务是从图片中找出物体并给出其类别和位置,对于单张图片,输出为图片中包含的N个物体的每个物体的中心位置(x,y)、宽(w)、高(h)以及其类别。
Yolo的预测基于整个图片,一次性输出所有检测到的目标信号,包括其类别和位置。Yolo首先将图片分割为sxs个相同大小的grid。

介绍
Yolo只要求grid中识别的物体的中心必须在这个grid内(具体来说,若某个目标的中心点位于一个grid内,该grid输出该目标类别的概率为1,所有其他grid对该目标预测概率设置为0)。
实现方法:让sxs个框每个都预测出B个boungding box,bounding box有5个量,分别为物体的x,y,h,w和预测的置信度;每个grid预测B个bounding box和物体类别,类别使用one-hot表示。
参考技术AYOLO是一种目标检测的算法。
YOLO将对象检测重新定义为一个回归问题,所以它非常快,不需要复杂的管道。它比“R-CNN”快1000倍,比“Fast R-CNN”快100倍。能够处理实时的视频流,延迟能够小于25毫秒,精度是以前实时系统的两倍多,YOLO遵循的是“端到端深度学习”的实践。它将单个卷积神经网络(CNN)应用于整个图像,将图像分成网格,并预测每个网格的类概率和边界框。
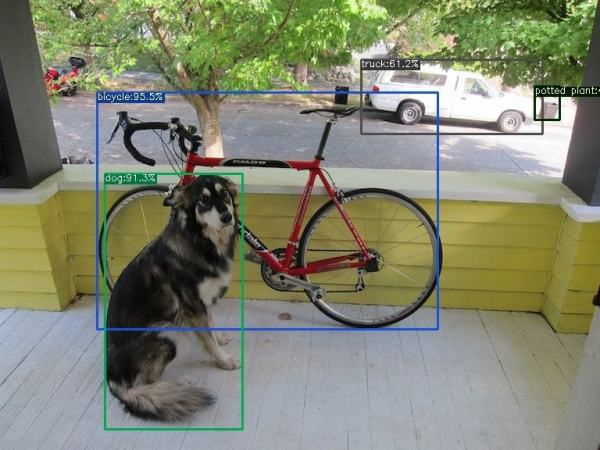
例如,以一个100x100的图像为例。我们把它分成网格,比如7x7。然后,对于每个网格,网络都会预测一个边界框和与每个类别(汽车,行人,交通信号灯等)相对应的概率。
以上是关于YOLO(一) 算法的原理及演变的主要内容,如果未能解决你的问题,请参考以下文章
深度学习之目标检测常用算法原理+实践精讲 YOLO / Faster RCNN / SSD / 文本检测 / 多任务网络