基于MapReduce的手机上网流量统计分析
Posted 一只懒得睁眼的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于MapReduce的手机上网流量统计分析相关的知识,希望对你有一定的参考价值。
Hadoop简介:适合大数据的分布式存储与计算平台。
运行在Hadoop之上的大型服务器集群:

数据情况:(摘取部分)
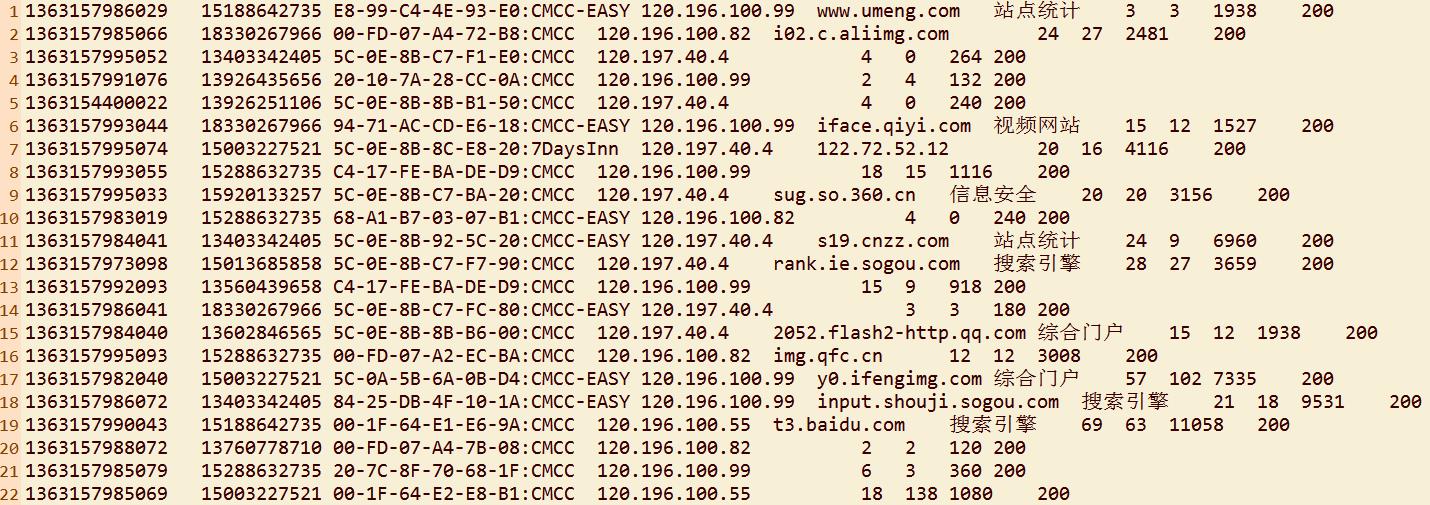
字段描述:时间戳、手机号码、AP mac、AP mac、访问的网址、网址种类、上行数据包、下行数据包、流量、访问状态。
手机上网流量统计结果:(先展示统计部分结果)

MapReduce程序开发步骤:
1、maper函数的编写
2、reducer函数的编写
3、MapReduce程序驱动的编写
mapper函数、reducer函数、驱动具体编写步骤:
map函数编写的基本原则是:MapReduce每读一行文本就调用一次我们的map函数,拿到日志中的一行数据,切分各个字段,从中抽选出我们需要的字段.然后封装成键值对进行处理.简单来说map函数的逻辑就是读行局部处理.
reduce函数编写的基本原则是MapReduce每传递一组数据
package IT;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FlowCount extends Configured implements Tool
public static String path1="";
public static String path2="";
public int run(String[] arg0) throws Exception
path1=arg0[0];
path2=arg0[1];
Job job = new Job(new Configuration(),"FlowCount");
job.setJarByClass(FlowCount.class);//jar包
//编写驱动
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.setOutputFormatClass(TextOutputFormat.class);
//向yarn平台提交任务
job.waitForCompletion(true);
return 0;
public static void main(String[] args) throws Exception
ToolRunner.run(new FlowCount(), args);
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
String[] splited = v1.toString().split("\\t");
String str1 = splited[1];//获取手机号
String str2 = splited[8];//获取单行流量
Text k2 = new Text(str1);
LongWritable v2 = new LongWritable(Long.parseLong(str2));
context.write(k2, v2);
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>
protected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)throws IOException, InterruptedException
long sum = 0L;
for (LongWritable v2 : v2s)
sum +=v2.get();
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
context.write(k3, v3);
2、导出jar包
最终通过eclipse导出jar包:

3、在linux文件系统中通过shell命令将流量数据上传到HDFS中

4、在linux中运行jar包,即运行MapReduce程序

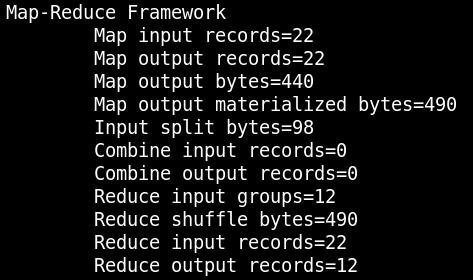
5、MapReduce程序运行完之后核实内置计数器进行校验
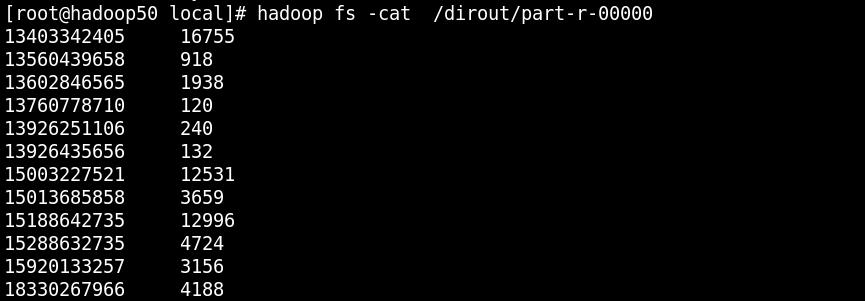
6、通过shell命令查看运行结果
综上:当给定我们一个业务后,如何用MapReduce实现某个业务?
1>给的原始数据相当于告诉了我们键值对
以上是关于基于MapReduce的手机上网流量统计分析的主要内容,如果未能解决你的问题,请参考以下文章