GitHub标星近1万:只需5秒音源,这个网络就能实时“克隆”你的声音
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GitHub标星近1万:只需5秒音源,这个网络就能实时“克隆”你的声音相关的知识,希望对你有一定的参考价值。

作者 | Google团队
译者 | 凯隐
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
本文中,Google 团队提出了一种文本语音合成(text to speech)神经系统,能通过少量样本学习到多个不同说话者(speaker)的语音特征,并合成他们的讲话音频。此外,对于训练时网络没有接触过的说话者,也能在不重新训练的情况下,仅通过未知说话者数秒的音频来合成其讲话音频,即网络具有零样本学习能力。
目前,已经有人将该论文实现并在 GitHub 上发布了开源项目,目前该项目标星超 9.5k,fork 数是 1.5k。
GitHub链接:
https://github.com/CorentinJ/Real-Time-Voice-Cloning?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
简介
传统的自然语音合成系统在训练时需要大量的高质量样本,通常对每个说话者,都需要成百上千分钟的训练数据,这使得模型通常不具有普适性,不能大规模应用到复杂环境(有许多不同的说话者)。而这些网络都是将语音建模和语音合成两个过程混合在一起。本文工作首先将这两个过程分开,通过第一个语音特征编码网络(encoder)建模说话者的语音特征,接着通过第二个高质量的TTS网络完成特征到语音的转换。
两个网络可以分别在不同的数据集上训练,因此对训练数据的需求量大大降低。对于特征编码网络,其关键在于声纹信息的建模,即判断两段语音为同一人所说,因此可以从语音识别(speaker verification)任务进行迁移学习,并且该网络可以在带有噪声和混响的多目标数据集上训练。
为了保证网络对未知(训练集中没有的)说话者仍然具有声音特征提取能力,编码网络在18K说话者的数据集上训练,而语音合成网络只需要在1.2K说话者的数据集上训练。
网络结构
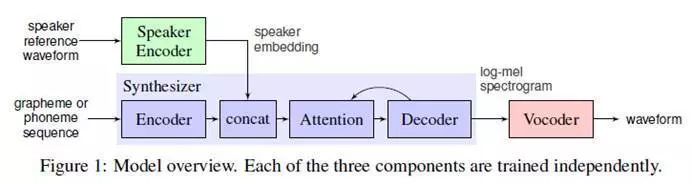
主要由三部分构成:
声音特征编码器(speaker encoder):
1. 语音编码器,提取说话者的声音特征信息。将说话者的语音嵌入编码为固定维度的向量,该向量表示了说话者的声音潜在特征。
2. 序列到序列的映射合成网络
基于Tacotron 2的映射网络,通过文本和1得到的向量来生成对数梅尔频谱图(log mel spectrogram)。
(梅尔光谱图将谱图的频率标度Hz取对数,转换为梅尔标度,使得人耳对声音的敏感度与梅尔标度承线性正相关关系)
3.基于WaveNet的自回归语音合成网络
将梅尔频谱图(谱域)转化为时间序列声音波形图(时域),完成语音的合成。
需要注意的是,这三部分网络都是独立训练的,声音编码器网络主要对序列映射网络起到条件监督作用,保证生成的语音具有说话者的独特声音特征。
1. 声音特征编码器
编码器主要将参考语音信号嵌入编码到固定维度的向量空间,并以此为监督,使映射网络能生成具有相同特征的原始声音信号(梅尔光谱图)。编码器的关键作用在于相似性度量,对于同一说话者的不同语音,其在嵌入向量空间中的向量距离(余弦夹角)应该尽可能小,而对不同说话者应该尽可能大。此外,编码器还应具有抗噪能力和鲁棒性,能够不受具体语音内容和背景噪声的影响,提取出说话者声音的潜在特征信息。这些要求和语音识别模型(speaker-discriminative)的要求不谋而合,因此可以进行迁移学习。
编码器主要由三层LSTM构成,输入是40通道数的对数梅尔频谱图,最后一层最后一帧cell对应的输出经过L2正则化处理后,即得到整个序列的嵌入向量表示。实际推理时,任意长度的输入语音信号都会被800ms的窗口分割为多段,每段得到一个输出,最后将所有输出平均叠加,得到最终的嵌入向量。这种方法和短时傅里叶变换(STFT)非常相似。
训练集包含按1.6s划分的音频样本,以及他们所对应的说话者label信息,不使用任何重复样本。
生成的嵌入空间向量可视化如下图:

可以看到不同的说话者在嵌入空间中对应不同的聚类范围,可以轻易区分,并且不同性别的说话者分别位于两侧。
然而合成语音和真实语音也比较容易区分开,合成语音离聚类中心的距离更远。这说明合成语音的真实度还不够。
2. 序列到序列的映射合成网络
在Tacotron 2的基础上,额外添加了对多个不同说话者的语音进行合成的功能。Tacotron 2包含注意力层,作者发现直接将嵌入向量作为注意力层的输入,能使网络对不同的说话者语音收敛。
该网络独立于编码器网络的训练,以音频信号和对应的文本作为输入,音频信号首先经过预训练的编码器提取特征,然后再作为attention层的输入。网络输出特征由窗口长度为50ms,步长为12.5ms序列构成,经过梅尔标度滤波器和对数动态范围压缩后,得到梅尔频谱图。为了降低噪声数据的影响,本文还对该部分的损失函数额外添加了L1正则化。
输入梅尔频谱图与合成频谱图的对比示例如下:

右图红线表示文本和频谱的对应关系。可以看到,用于参考监督的语音信号不需要与目标语音信号在文本上一致,这也是本工作的一大特色。
3. 基于WaveNet的自回归语音合成网络
在得到合成频谱图后,还需要进一步转化为时域上的声音波形图,这部分主要通过自回归WaveNet完成。由于上一个合成器生成的序列已经包含了声音合成所需的全部信息,因此这部分不需要编码器进行监督。
4.零样本推断
除了以上三部分,网络还具备零样本推断能力。即对于不在训练集内的说话者(不可见),只需要该说话者几秒的音频段,编码器就能提取出说话者的关键语音特征,并用来辅助映射网络合成序列。并且不需要这段语音与待合成的语音具有相同文本。
实验结果
主要在VCTK和LibriSpeech两个大型数据集上训练。
语音自然度
首先评估了模型合成语音的自然度(即真实度),构建了一个具有100个句子的验证集(不在训练集中),然后对每个数据集,都选择一定数量的可见和不可见说话者,对每个说话者随机选择一个句子作为编码器的输入,然后对该说话者的所有句子进行合成,再与原来的真值进行对比:

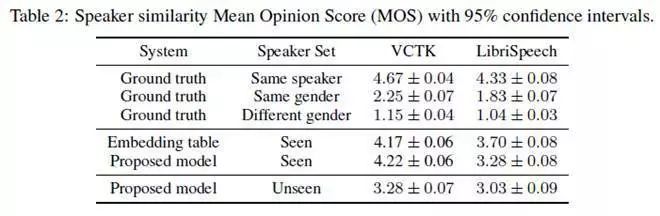
语音相似度
为了验证合成语音与原始说话者语音是否相似,对每个说话者的每段语音,都随机选择另一段语音作为真值,然后评估他们的相似度:

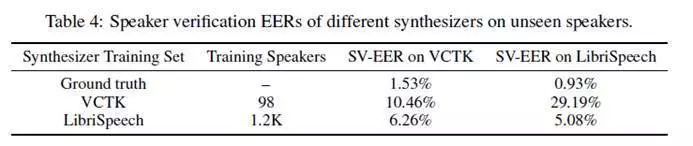
说话人认证
该指标与前面两个指标相反,旨在验证语音识别系统能否有效区分合成语音和真实语音:
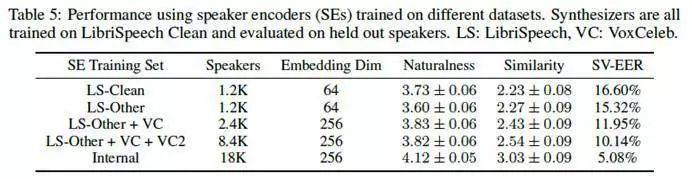
语音编码器评估
语音编码器是本文工作的核心网络,训练编码器所用的数据集对网络整体性能有较大影响:
总结
本文提出的语音合成网络,能对训练不可见的说话者进行声音合成,并且仅仅依赖于说话者的一小段语音,这使得该网络能够大规模应用于实际环境,也使得语音造假的成本大大降低,类似于之前的deepfake网络。
作者指出该网络生成的合成语音和真实语音仍然是可以区分的,这是因为训练集的数量不足(避免太逼真带来的安全问题)。如果要生成非常逼真的声音,对每个目标说话,仍然需要数十分钟的语音。
论文链接:https://arxiv.org/pdf/1806.04558.pdf
(*本文为AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。6.6 折票限时特惠(立减1400元),学生票仅 599 元!
推荐阅读
以上是关于GitHub标星近1万:只需5秒音源,这个网络就能实时“克隆”你的声音的主要内容,如果未能解决你的问题,请参考以下文章
非科班出身,自学撸出中文分词库,GitHub标星1.7万,这是他入门NLP的秘籍
GPT版超级马里奥来了!输入文本即可自定义游戏关卡 | GitHub标星500+