自己动手写编译器:从NFA到DFA
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自己动手写编译器:从NFA到DFA相关的知识,希望对你有一定的参考价值。
上一节我们完成了使用NFA来识别字符串的功能。NFA有个问题就是其状态节点太多,使用起来效率不够好。本节我们介绍一种叫“子集构造”的算法,将拥有多个节点的NFA转化为DFA。在上一节我们描述的epsilon闭包操作可以看到,实际上所有由epsilon边连接在一起的节点其实都能看作是一个状态节点,由此我们就能通过epsilon操作将多个节点转化为一个DFA节点,同时epsilon闭包操作所得的节点集合中,每一个节点发出的边都可以看作是新DFA节点发出的边。
我们用上一节完成的NFA状态机来看看具体过程:
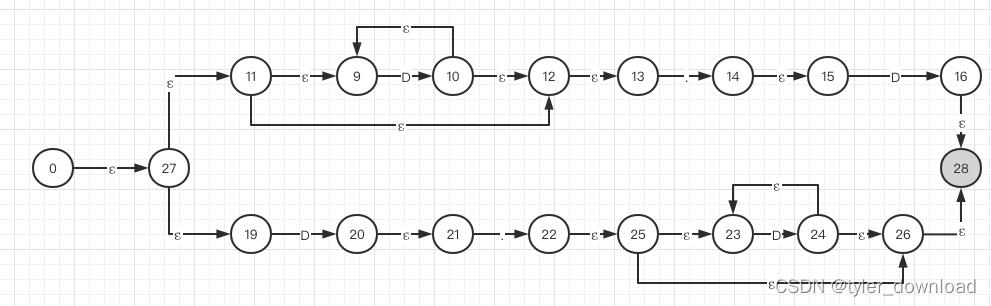
从节点0开始做epsilon操作所得结果为:
epsilon-closure(0) = 0, 27, 11, 19, 9, 12, 13, 由此我们把这些节点合成一个新节点,我们标记为DFA state 0。
接着我们对集合0, 27, 11, 19, 9, 12做move操作有:
move(0, 27, 11, 19, 9, 12, 14, D = 10, 20, 于是可以把节点10,20合成新节点,记做"DFA state 1", 因为有:
move(0, 27, 11, 19, 9, 12, . = 14, 于是我们把节点14看做新节点,记做"DFA state 2",这么一来我们就得到如下DFA状态机:
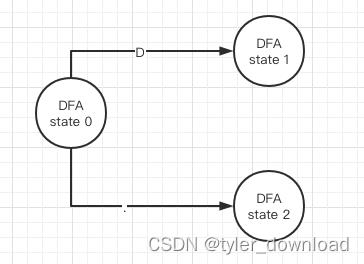
接下来我们继续对10, 20进行epsilon闭包操作,epsilon-closure(10, 20)=10, 20, 9,12,13,21,然后再对这个结果做move操作有:
move(10, 20, 9,12,13,21, D) = 10 , 于是我们再产生一个新DFA节点记作DFA state 3, move(10, 20, 9,12,13,21, . = 14, 22 于是我们再产生新的DFA节点记作DFA state 4,于是就有:
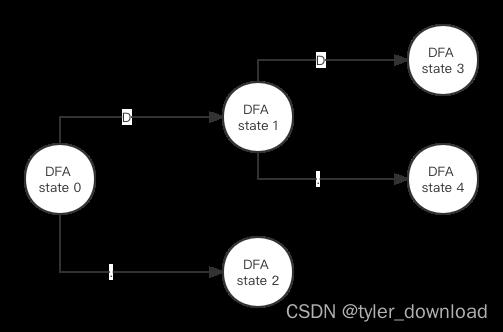
这个过程以此类推,这里需要注意的是如果epsilon闭包操作后所得的节点集合中有NFA状态机的终结节点,那么其对应的DFA节点就是一个终结节点。接下来看看代码如何实现,我们添加一个名为nfa_to_dfa.go的文件,然后添加代码如下:
import "fmt"
const (
DFA_MAX = 254 //DFA 最多节点数
F = -1 //用于初始化跳转表
MAX_CHARS = 128 //128个ascii字符
)
type ACCEPT struct
acceptString string //接收节点对应的执行代码字符串
anchor Anchor
type DFA struct
group int //后面执行最小化算法时有用
mark bool //当前节点是否已经设置好接收字符对应的边
anchor Anchor
set []*NFA //dfa节点对应的nfa节点集合
state int //dfa 节点号码
acceptString string
这里我们先定义基本的数据结构,在转换的DFA状态机中,它最多包含254个节点,同时状态机只接收来自ascii表中数值从0到128的字符,这次我们构造的DFA状态机将不像上次构造的NFA状态机那样使用链表结构,这次我们使用跳转表结构,我们将构造一个二维数组dtrans,假设状态节点1接收字符“.“后,跳转到状态节点2,由于字符”."对应的ascii数值为46,那么就有dtrans[1][46] = 2.
在上面代码中我们定义了DFA节点,由于一个DFA节点由一组NFA节点转换而来,因此在它的定义中有一个NFA节点的指针数组。接下来我们设计用于将NFA转换成DFA的类,其代码为:
type NfaDfaConverter struct
nstates int //当前dfa 节点计数
lastMarked int //下一个需要处理的dfa节点
dtrans [][]int //dfa状态机的跳转表
accepts []*ACCEPT
dstates []DFA //所有dfa节点的集合
func NewNfaDfaConverter() *NfaDfaConverter
n := &NfaDfaConverter
nstates: 0,
lastMarked: 0,
dtrans: make([][]int, DFA_MAX),
dstates: make([]DFA, DFA_MAX),
for i := range n.dtrans
n.dtrans[i] = make([]int, MAX_CHARS)
return n
在定义中有几个变量需要注意,其中dtrans是用于构造DFA跳转表的二维数组, nstates用于记录当前已经生成的DFA节点数量,lastMarked用于指向下一个要创建其跳转逻辑的DFA节点编号,dstates用于存储当前已经创建了的DFA节点。下面我们看看转换逻辑的实现:
func (n *NfaDfaConverter) getUnMarked() *DFA
for ; n.lastMarked < n.nstates; n.lastMarked++
debug := 0
if n.dstates[n.lastMarked].state == 5
debug = 1
fmt.Printf("debug: %d", debug)
if n.dstates[n.lastMarked].mark == false
return &n.dstates[n.lastMarked]
return nil
func (n *NfaDfaConverter) compareNfaSlice(setOne []*NFA, setTwo []*NFA) bool
//比较两个集合的元素是否相同
if len(setOne) != len(setTwo)
return false
equal := false
for _, nfaOne := range setOne
for _, nfaTwo := range setTwo
if nfaTwo == nfaOne
equal = true
break
if equal != true
return false
return true
func (n *NfaDfaConverter) hasDfaContainsNfa(nfaSet []*NFA) (bool, int)
//查看是否存在dfa节点它对应的nfa节点集合与输入的集合相同
for _, dfa := range n.dstates
if n.compareNfaSlice(dfa.set, nfaSet) == true
return true, dfa.state
return false, -1
func (n *NfaDfaConverter) addDfaState(epsilonResult *EpsilonResult) int
//根据当前nfa节点集合构造一个新的dfa节点
nextState := F
if n.nstates >= DFA_MAX
panic("Too many DFA states")
nextState = n.nstates
n.nstates += 1
n.dstates[nextState].set = epsilonResult.results
n.dstates[nextState].mark = false
n.dstates[nextState].acceptString = epsilonResult.acceptStr
n.dstates[nextState].anchor = epsilonResult.anchor
n.dstates[nextState].state = nextState //记录当前dfa节点的编号s
n.printDFAState(&n.dstates[nextState])
fmt.Print("\\n")
return nextState
func (n *NfaDfaConverter) printDFAState(dfa *DFA)
fmt.Printf("DFA state : %d, it is nfa are: ", dfa.state)
for _, nfa := range dfa.set
fmt.Printf("%d,", nfa.state)
fmt.Printf("")
func (n *NfaDfaConverter) MakeDTran(start *NFA)
//根据输入的nfa状态机起始节点构造dfa状态机的跳转表
startStates := make([]*NFA, 0)
startStates = append(startStates, start)
statesCopied := make([]*NFA, len(startStates))
copy(statesCopied, startStates)
//先根据起始状态的求Epsilon闭包操作的结果,由此获得第一个dfa节点
epsilonResult := EpsilonClosure(statesCopied)
n.dstates[0].set = epsilonResult.results
n.dstates[0].anchor = epsilonResult.anchor
n.dstates[0].acceptString = epsilonResult.acceptStr
n.dstates[0].mark = false
//debug purpose
n.printDFAState(&n.dstates[0])
fmt.Print("\\n")
nextState := 0
n.nstates = 1 //当前已经有一个dfa节点
//先获得第一个没有设置其跳转边的dfa节点
current := n.getUnMarked()
for current != nil
current.mark = true
for c := 0; c < MAX_CHARS; c++
nfaSet := move(current.set, c)
if len(nfaSet) > 0
statesCopied = make([]*NFA, len(nfaSet))
copy(statesCopied, nfaSet)
epsilonResult = EpsilonClosure(statesCopied)
nfaSet = epsilonResult.results
if len(nfaSet) == 0
nextState = F
else
//如果当前没有那个dfa节点对应的nfa节点集合和当前nfaSet相同,那么就增加一个新的dfa节点
isExist, state := n.hasDfaContainsNfa(nfaSet)
if isExist == false
nextState = n.addDfaState(epsilonResult)
else
nextState = state
//设置dfa跳转表
n.dtrans[current.state][c] = nextState
current = n.getUnMarked()
func (n *NfaDfaConverter) PrintDfaTransition()
for i := 0; i < DFA_MAX; i++
if n.dstates[i].mark == false
break
for j := 0; j < MAX_CHARS; j++
if n.dtrans[i][j] != F
n.printDFAState(&n.dstates[i])
fmt.Print(" jump to : ")
n.printDFAState(&n.dstates[n.dtrans[i][j]])
fmt.Printf("by character %s\\n", string(j))
前面我们看到,一个DFA节点本质上对应一组NFA节点,因此当我们使用move 和epsilon闭包操作得到一组NFA节点后,我们需要看看是不是已经有DFA节点对应到了生成的NFA节点集合,如果有了,说明对应的DFA节点已经生成,这个操作由函数compareNfaSlice和hasDfaContainsNfa完成,如果当前得到的NFA节点集合没有对应的DFA节点,那么就使用addDfaState函数去创建一个新的DFA节点,然后将其加入到dstates数组中。
每新建一个DFA节点时,它的mark标志位会设置成false,这表明我们还没有为它设置跳转边,函数getUnMarked用于将当前所有mark设置为false的DFA节点中找出创建时间最早的那个。上面代码的算法核心在函数MakeDTran,它执行了我们上面提到的算法,首先获得NFA状态机的起始节点,然后通过epsilon闭包操作获得一组NFA节点,用这组节点创建一个对应的DFA节点。接着使用move操作得到第二组NFA节点,然后再次使用epsilon闭包操作获得新一组NFA节点,然后创建第二个DFA节点,最后根据这两个节点对应的编号在二维表dtrans中设置跳转逻辑。
接下来我们在主函数中调用上面实现代码看看结果,在mai.go中输入代码如下:
package main
import (
"nfa"
)
func main()
lexReader, _ := nfa.NewLexReader("input.lex", "output.py")
lexReader.Head()
parser, _ := nfa.NewRegParser(lexReader)
start := parser.Parse()
parser.PrintNFA(start)
//str := "3.14"
//if nfa.NfaMatchString(start, str)
// fmt.Printf("string %s is accepted by given regular expression\\n", str)
//
nfaConverter := nfa.NewNfaDfaConverter()
nfaConverter.MakeDTran(start)
nfaConverter.PrintDfaTransition()
上面代码运行后输出结果如下:
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9,
DFA state : 1, it is nfa are: 14,15,
DFA state : 2, it is nfa are: 10,9,12,13,20,21,
DFA state : 3, it is nfa are: 16,28,
DFA state : 4, it is nfa are: 22,25,26,28,23,14,15,
DFA state : 5, it is nfa are: 10,9,12,13,
DFA state : 6, it is nfa are: 16,28,24,23,26,28,
DFA state : 7, it is nfa are: 24,23,26,28,
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 1, it is nfa are: 14,15,by character .
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 0
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 1
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 2
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 3
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 4
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 5
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 6
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 7
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 8
DFA state : 0, it is nfa are: 0,27,19,11,12,13,9, jump to : DFA state : 2, it is nfa are: 10,9,12,13,20,21,by character 9
DFA state : 1, it is nfa are: 14,15, jump to : DFA state : 3, it is nfa are: 16,28,by character 0
DFA state : 1, it is nfa are: 14,15, jump to : DFA state : 3, it is nfa are: 16,28,by character 1
DFA state : 1, it is nfa are: 14,15, jump to : DFA state : 3, it is nfa are: 16,28,by character 2
DFA state : 1, it is nfa are: 14,15, jump to : DFA state : 3, it is nfa are: 16,28,by character 3
DFA state : 1, it is nfa are: 14,15, jump to : DFA state : 3, it is nfa are: 16,28,以上是关于自己动手写编译器:从NFA到DFA的主要内容,如果未能解决你的问题,请参考以下文章