常用的5种并发包
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用的5种并发包相关的知识,希望对你有一定的参考价值。
参考技术A 常用的五种并发包ConcurrentHashMap
CopyOnWriteArrayList
CopyOnWriteArraySet
ArrayBlockingQueue
LinkedBlockingQueue
1、ConcurrentHashMap
(1) 线程安全的HashMap的实现
(2)数据结构:一个指定个数的Segment数组,数组中的每一个元素Segment相当于一个HashTable(一个HashEntry[])
(3)扩容的话,只需要扩自己的Segment而非整个table扩容
(4) key与value均不可以为null,而hashMap可以
(5)向map添加元素
5.1) 根据key获取key.hashCode的hash值
5.2) 根据hash值算出将要插入的Segment
5.3) 根据hash值与Segment中的HashEntry的容量-1按位与获取将要插入的HashEntry的index
5.4) 若HashEntry[index]中的HashEntry链表有与插入元素相同的key和hash值,根据onlyIfAbsent决定是否替换旧值
5.5) 若没有相同的key和hash,直接返回将新节点插入链头,原来的头节点设为新节点的next(采用的方式与HashMap一致,都是HashEntry替换的方法)
(6)ConcurrentHashMap基于concurrencyLevel划分出多个Segment来存储key-value,这样的话put的时候只锁住当前的Segment,可以避免put的时候锁住整个map,从而减少了并发时的阻塞现象
从map中获取元素
(7)根据key获取key.hashCode的hash值
7.1) 根据hash值与找到相应的Segment
7.2)根据hash值与Segment中的HashEntry的容量-1按位与获取HashEntry的index
7.3)遍历整个HashEntry[index]链表,找出hash和key与给定参数相等的HashEntry,例如e
如没找到e,返回null
如找到e,获取e.value
如果e.value!=null,直接返回
如果e.value==null,则先加锁,等并发的put操作将value设置成功后,再返回value值
(8)对于get操作而言,基本没有锁,只有当找到了e且e.value等于null,有可能是当下的这个HashEntry刚刚被创建,value属性还没有设置成功,这时候我们读到是该HashEntry的value的默认值null,所以这里加锁,等待put结束后,返回value值
(9)加锁情况 (分段锁):
---put
---get中找到了hash与key都与指定参数相同的HashEntry,但是value==null的情况
---remove
---size():三次尝试后,还未成功,遍历所有Segment,分别加锁(即建立 全局锁)
2、CopyOnWriteArrayList
线程安全且在读操作时无锁的ArrayList
采用的模式就是"CopyOnWrite"(即写操作-->包括增加、删除,使用复制完成)
底层数据结构是一个Object[],初始容量为0,之后每增加一个元素,容量+1,数组复制一遍
遍历的只是全局数组的一个副本,即使全局数组发生了增删改变化,副本也不会变化,所以不会发生并发异常。但是,可能在遍历的过程中读到一些刚刚被删除的对象
增删改上锁、读不上锁
读多写少且脏数据影响不大的并发情况下,选择CopyOnWriteArrayList
3、CopyOnWriteArraySet
基于CopyOnWriteArrayList,不添加重复元素
4、ArrayBlockingQueue
基于数组、先进先出、线程安全,可实现指定时间的阻塞读写,并且容量可以限制
组成:一个对象数组+1把锁ReentrantLock+2个条件Condition
三种入队对比
offer(E e):如果队列没满,立即返回true; 如果队列满了,立即返回false-->不阻塞
put(E e):如果队列满了,一直阻塞,直到数组不满了或者线程被中断-->阻塞
offer(E e, long timeout, TimeUnit unit):在队尾插入一个元素,,如果数组已满,则进入等待,直到出现以下三种情况:-->阻塞
#被唤醒
#等待时间超时
#当前线程被中断
三种出对对比
poll():如果没有元素,直接返回null;如果有元素,出队
take():如果队列空了,一直阻塞,直到数组不为空或者线程被中断-->阻塞
poll(long timeout, TimeUnit unit):如果数组不空,出队;如果数组已空且已经超时,返回null;如果数组已空且时间未超时,则进入等待,直到出现以下三种情况:
#被唤醒
#等待时间超时
#当前线程被中断
需要注意的是,数组是一个必须指定长度的数组,在整个过程中,数组的长度不变,队头随着出入队操作一直循环后移
锁的形式有公平与非公平两种
在只有入队高并发或出队高并发的情况下,因为操作数组,且不需要扩容,性能很高
5、LinkedBlockingQueue
基于链表实现,读写各用一把锁,在高并发 读写操作都多 的情况下,性能优于ArrayBlockingQueue
组成一个链表+两把锁+两个条件
默认容量为整数最大值,可以看做没有容量限制
三种入队与三种出队与上边完全一样,只是由于LinkedBlockingQueue的的容量无限,在入队过程中,没有阻塞等待
java并发包提供的三种常用并发队列实现
java并发包中提供了三个常用的并发队列实现,分别是:ConcurrentLinkedQueue、LinkedBlockingQueue和ArrayBlockingQueue。
ConcurrentLinkedQueue使用的是CAS原语无锁队列实现,是一个异步队列,入队速度很快,出队进行了加锁,性能稍慢;
LinkedBlockingQueue也是阻塞队列,入队和出队都用了加锁,当队空的时候线程会暂时阻塞;当队空的时候线程会暂时阻塞;
ArrayBlockingQueue是初始容器固定的阻塞队列,我们可以用来作为数据库模块成功竞拍的队列,比如有10个商品,那么我们就设定一个10大小的数组队列。
一、BlockingQueue接口
BlockingQueue接口定义了一种阻塞的FIFO queue,每一个BlockingQueue都有一个容量,让容量满时往BlockingQueue中添加数据时会造成阻塞,当容量为空时取元素操作会阻塞。
二、ArrayBlockingQueue
ArrayBlockingQueue是一个由数组支持的有界阻塞队列。在读写操作上都需要锁住整个容器,因此吞吐量与一般的实现是相似的,适合于实现“生产者消费者”模式。
三、LinkedBlockingQueue
LinkedBlockingQueue内部维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
3. 队列大小初始化方式不同
ArrayBlockingQueue是有界的,必须指定队列的大小;
LinkedBlockingQueue是无界的,可以不指定队列的大小,但是默认是Integer.MAX_VALUE。当然也可以指定队列大小,从而成为有界的;
注意:
1. 在使用LinkedBlockingQueue时,若用默认大小且当生产速度大于消费速度时候,有可能会内存溢出;
2. 在使用ArrayBlockingQueue和LinkedBlockingQueue分别对1000000个简单字符做入队操作时,
LinkedBlockingQueue的消耗是ArrayBlockingQueue消耗的10倍左右,
即LinkedBlockingQueue消耗在1500ms左右,而ArrayBlockingQueue只需150ms左右。
性能测试:不限容量的LinkedBlockingQueue的吞吐量 > ArrayBlockingQueue > 限定容量的LinkedBlockingQueue
LinkedBlockingQueue内部使用ReentrantLock实现插入锁(putLock)和取出锁(takeLock)。putLock上的条件变量是notFull,即可以用notFull唤醒阻塞在putLock上的线程。takeLock上的条件变量是notEmtpy,即可用notEmpty唤醒阻塞在takeLock上的线程。
四、ArrayBlockingQueue和LinkedBlockingQueue的区别
1. 队列中锁的实现不同
ArrayBlockingQueue实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue实现的队列中的锁是分离的,即生产用的是putLock,消费是takeLock;
2. 在生产或消费时操作不同
ArrayBlockingQueue基于数组,在生产和消费的时候,是直接将枚举对象插入或移除的,不会产生或销毁任何额外的对象实例;
LinkedBlockingQueue基于链表,在生产和消费的时候,需要把枚举对象转换为Node<E>进行插入或移除,会生成一个额外的Node对象,这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别;
注意:
1. 在使用LinkedBlockingQueue时,若用默认大小且当生产速度大于消费速度时候,有可能会内存溢出;
2. 在使用ArrayBlockingQueue和LinkedBlockingQueue分别对1000000个简单字符做入队操作时,
LinkedBlockingQueue的消耗是ArrayBlockingQueue消耗的10倍左右,
即LinkedBlockingQueue消耗在1500ms左右,而ArrayBlockingQueue只需150ms左右。
性能测试:不限容量的LinkedBlockingQueue的吞吐量 > ArrayBlockingQueue > 限定容量的LinkedBlockingQueue
五、添加、删除元素的区别
添加元素的方法有三个:add,put,offer
1、add方法: LinkedBlockingQueue构造的时候若没有指定大小,则默认大小为Integer.MAX_VALUE,当然也可以在构造函数的参数中指定大小。LinkedBlockingQueue不接受null。add方法在添加元素的时候,若超出了度列的长度会直接抛出异常;
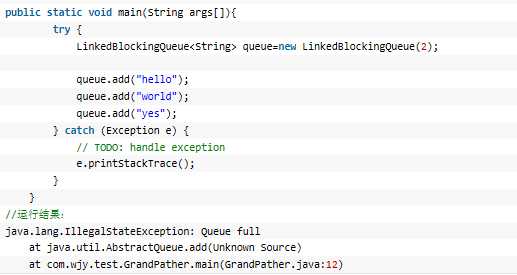
2、put方法:若向队尾添加元素的时候发现队列已经满了会发生阻塞一直等待空间,以加入元素;

3、offer方法: offer方法在添加元素时,如果发现队列已满无法添加的话,会直接返回false。
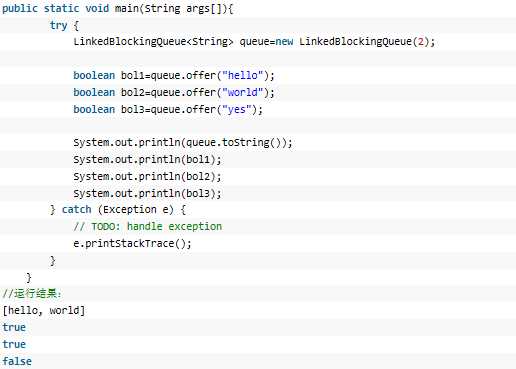
poll: 若队列为空,返回null。
remove:若队列为空,抛出NoSuchElementException异常。
take:若队列为空,发生阻塞,等待有元素。
以上是关于常用的5种并发包的主要内容,如果未能解决你的问题,请参考以下文章
举例详解 java.util.concurrent 并发包 4 种常见类