机器学习100天:003 数据预处理之处理缺失值
Posted 红色石头Will
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习100天:003 数据预处理之处理缺失值相关的知识,希望对你有一定的参考价值。
机器学习 100 天,今天讲的是:数据预处理-处理缺失值。
在上一节,我们导入了数据集,得到特征 X 和标签 y。
我们打开 X,发现 index5 样本的‘年龄’和 index3 样本的‘薪资’数值是 NaN。
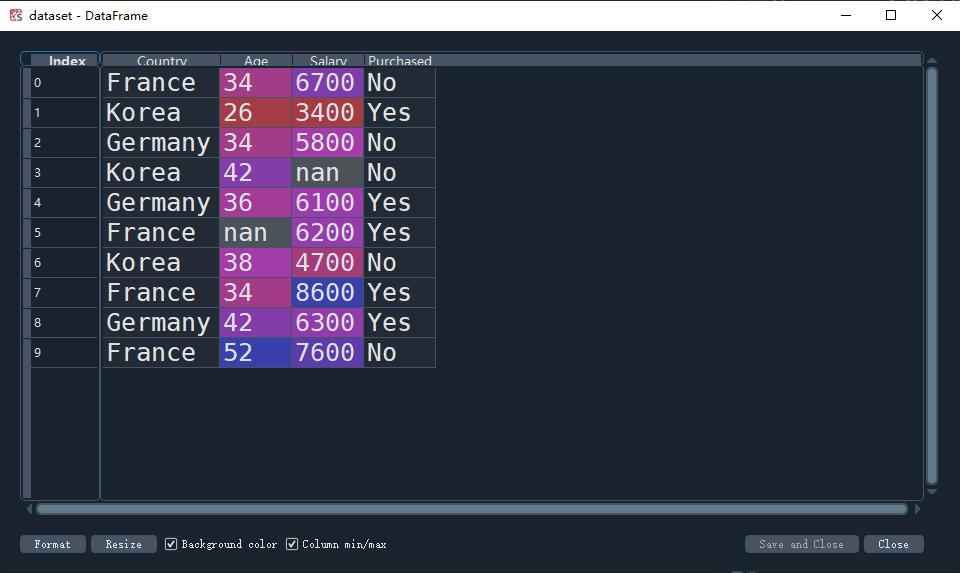
NaN(Not a Number)是计算机科学中数值数据类型的一类值,表示空值
可能是由于在样本收集的时候没有统计到该特征。
对于 NaN 值,最简单粗暴的做法是直接删除对应的样本,但我们一般不这么做。常见的做法是对 NaN 进行插值,即用该特征的平均值、中值等替代
一般来说,平均数是总体均值很好的估计,中位数是对总体中心很好的估计,如果特征分布比较稳定的话,平均值效率更高,而中位数稳健性更好,能避免受到到异常数值的影响。
例如,假设这里的薪资 6700 由于统计错误,写成 67,如果用平均值的话,则该异常数值就会影响插值,造成误差,但如果用中位数的话,就能消除异常数值的影响。
好,我们回到 spyder。处理缺失值的代码如何写呢?很简单,直接使用 pandas 库的 fillna 函数,一行语句搞定。
# 处理缺失值
X[\'Age\'<以上是关于机器学习100天:003 数据预处理之处理缺失值的主要内容,如果未能解决你的问题,请参考以下文章