人工智能助力古彝文识别,推动传统文化传承
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能助力古彝文识别,推动传统文化传承相关的知识,希望对你有一定的参考价值。
人工智能助力古彝文识别,推动传统文化传承
0. 前言
古彝文作为世界上最古老的文字之一,记录了人类几千年来的发展历史。古彝文识别研究能够将珍贵的古彝文文本文献转换为电子文件,更加便于其保存和传承。但由于历史发展、区域限制等诸多要素,针对古彝文识别的研究工作一直进展缓慢。本文介绍了如何将新颖的深度学习技术应用于古老文字的识别上,介绍了合合信息如何解决古彝文识别中的困难与挑战。依托于合合信息在古文字识别领域的积累,相对于传统古彝文识别模型,合合信息携手上海大学提出的基于深度学习的古彝文识别模型能够以更高的精度识别古彝文手写体,极大的提高了古彝文识别的准确率。
1. 古彝文
1.1 古彝文介绍
彝族有着古老灿烂的文化,它记录并保存了卷帙浩繁的典籍,是中华传统文化宝库中的重要组成部分。

据 1980 年发布的四川规范彝文共有 819 字,2012 年发布的滇川黔桂通用彝文共有 5598 字,而与这些演化到现代的规范彝文不同,古彝文是指民间流通使用的原生态彝文,据《滇川黔桂彝文字集》统计,这些古彝文多达 87046 字。由于古彝文典籍通常记录于石刻、岩画、木牍和纸书之上,由于年代久远,通常较为模糊甚至有所残缺,这为古彝文的识别带来了极大的挑战。
| 古埃及象形文字字义 | 鱼 | 鸟 | 旗 | 箭 | 瓶 |
|---|---|---|---|---|---|
| 古埃及象形文字(约 3200 BC—AD 400) |  |  |  |  |  |
| 象形文基础上演化的古埃及僧侣体草书 |  |  |  |  |  |
| 象形文基础上演化的古埃及僧侣体草书 |  |  |  |  |  |
| 古彝文字义 | 鱼 | 鸟 | 月 | 马 | 首 |
| 古彝文字 |  |  |  |  |  |
1.2 古彝文识别的重要意义
随着时间的流逝,许多古文字都渐渐消失在历史的长河中,而古彝文是少有仍在使用的文字。对古彝文高效的识别对于古彝文的整理和翻译工作而言都有着重要意义,不仅能够帮助理解尚未被翻译为汉文或者并不规范的古籍,而且能够更实际的保护传统文化。目前,古彝文的相关整理工作仍然主要依靠手工进行,不仅会占用大量的人力成本,且效率较低、成果的重复利用存在困难,例如,对《西南彝志》的整理与汉译,罗国义、王兴友等人耗费了 10 年时间才完成,为了对初版译本进行完善和修正,王运权、王仕举等又耗时 17 年才完成再版。
随着人工智能,特别是深度学习的发展,可以为古彝文识别提供更加高效工具,为其保存和传播提供了强有力的支撑。古彝文识别不仅仅是人类知识的延续和传承,同时也是推动知识发展的关键,合合信息携手上海大学的“原生态古彝文”研究项目将成为抢救、整理、保存、传播和利用彝文古籍的有效途径。
1.3 古彝文识别的挑战
相对于其他更具标准化的文字,古彝文的书写更为随意,并无通用的统一性规范标准,因此其识别难度也随之增加。尽管目前文本识别技术已经有了突破性进展,例如合合信息自研的文字识别技术,覆盖文字、文档、表格、印章、二维码、公式等多种通用场景,能够进行快速、精准的检测和识别,支持中文、英文等超过 50 种语言,同时支持印刷体、手写体、倾斜、折叠、旋转等,但由于版式的多样性、字符集的庞大性和图像质量差等原因,当前对于古彝文识别的研究仍然寥寥无几,并且现存的古彝文大多为手写体,这进一步加深了古彝文识别的难度,总结而言,古彝文识别的挑战性主要集中于以下几个方面:
- 缺乏完善的手写古彝文数据集:数据集通常是训练神经网络最为关键的因素之一,数据集的质量直接决定了模型的效果。当前对古彝文的研究多集中在文献整理上,而尚未有完善的古彝文手写数据集,并且在传承过程中通晓古彝文文字的人越来越少,导致数据集标注工作量大而人手少,数据集样本严重不足,这是古彝文识别最为关键的挑战之一。合合信息研究人员通过与古彝文传承人建立良好的关系,获取大量典籍,弥补了古彝文识别项目训练样本不足的情况
- 版式多样性:古彝文典籍排版风格具有多样性,字符间距、行距等有较大差异,且存在加字、替字、整句倒置等现象,这种情况对文字定位与识别造成了诸多干扰。而依托合合信息在智能文字识别领域的领先技术,包括图像复杂版式识别、图像扭曲矫正等优秀成果,为古彝文识别奠定了技术基础
- 图像质量较差:除了数据集在样本上的不足外,在数据质量上也存在诸多问题,多数古彝文典籍都因历史保护的原因,出现了或多或少的缺失或污迹,严重影响了数据集的质量,增加了文字识别的难度。得益于合合信息智能文字识别技术,通过利用图像增强技术可以显著提高图像质量,进而提高古彝文文字识别的精度和效率

- 字符集庞大:古彝文拥有庞大的字符集,在上文中,我们已经提到仅仅是
2004年出版的《滇川黔桂彝文字集》就包含87000多个字。对如此庞大的字符集进行分类是一项十分艰巨的任务。借助合合信息在甲骨文、金文等古文中的研究经验,文字间的识别有相通之处,为古彝文识别打下了坚实基础 - 字形变化较多:古彝文字体、字形的变化较多,没有统一的手写规范,且不同地区书写规则不同,存在大量的变形字和异体字,例如,如下图所示,表示“种类”的古彝文就有四种不同的写法,并且存在大量字形相似,甚至在视觉上没有太大差别的字,在意义上毫无联系,这为古彝文的识别增加了难度。针对这一问题,上海大学的古彝文研究人员提出了四字节编码方案,用于描述每个变体和形近字符之间的细微差别,根据这种编码方案能够更好的建立深度学习数据集

2. 古彝文识别国内外研究进展
在古彝文识别领域,研究的主力仍然是民族类高校和研究所,且研究成果的应用和转换率较低。王嘉梅等利用图像分割技术实现古彝文识别,首先通过预处理对彝文字符应用细分、归一化、二值化等经典图像处理技术,然后对预处理后的图像使用模板匹配方法进行识别。朱华龙等人提出了基于特征提取的分类方法,是经典的传统机器学习方法,利用人工对古彝文提取方向线素特征、笔画密度特征和投影特征等然后利用多分类投票法确定文字的最终类别。
除此之外,也有许多其他国内外学者对多种不同古文进行研究,例如北京大学的“识典古籍”项目利用文字识别、自动标点和命名实体识别等技术对古籍进行识别;阿里巴巴的“汉典重光”项目利用人工智能技术数字化了一批珍藏在加州大学伯克利分校的中文古籍。
3. 基于深度学习的古彝文识别
3.1 深度学习简介
近年来,深度学习 (Deep Learning, DL) 在多个领域中都取得了突破性进展,尤其是在图像识别、目标检测以及自然语言处理等领域。神经网络由具有权重和偏置的人工神经元组成,这些权重和偏置会在模型训练过程中进行调整,以得到一个性能优异的学习模型。每个神经元可以接收一组输入,以某种方式对其进行处理后,输出一个或多个值。如果我们通过堆叠多层的神经网络,它就被称为深度神经网络,处理这些深度神经网络的人工智能分支称为深度学习。
传统全连接神经网络的主要缺点之一是它们忽略了输入数据的结构,所有数据在输入网络之前都被转换为一维数组。这对于简单的数字数据而言,可能并没有什么问题,但当我们处理图像数据时,全连接网络就表现出不足之处。以灰度图像为例,这些图像是二维结构,同时像素的空间排列包含很多隐藏信息。如果我们忽略这些信息,而将图片转换为一维结构,我们将失去很多潜在信息。而这也正是卷积神经网络 (Convolutional Neural Network, CNN) 的优势所在,CNN 在处理图像时会考虑图像的 2D 结构。
CNN 也是由权重和偏差组成的神经元组成,这些神经元接受输入数据,进行处理后,输出处理后的值。网络的目标是从输入层的原始图像数据到得到输出层的正确结果,不同任务中,网络的目标并不相同:在图像分类中,网络的目标是得到图片类别;在目标检测中,网络的目标是定位目标的位置。普通全连接神经网络和 CNN 之间的区别在于使用的神经网络层类型以及我们如何处理输入数据,假设 CNN 的输入是图像,那么可以使用 CNN 提取图像的特征。除此之外,CNN 的输入并不仅限于图像,也可以为文本等数据。

CNN 是一种经典的深度学习网络,它通常用于图像识别等任务。与任何其他神经网络一样,为图像中的元素分配权重和偏置,并能够将这些元素彼此区分开来。与其他分类模型相比,CNN 中所需使用的数据预处理较少。
CNN 架构的基本形式可以比作人脑中的神经元和树突,它的灵感来自视觉皮层。单个神经元只对视野受限区域的刺激作出反应,这个视野区域被称为感受野 (Receptive Field),这些感受野相互重叠后,覆盖了整个视野范围。
循环神经网络 (Recurrent Neural Network, RNN) 是另一种经典的神经网络架构,可以将 RNN 视为一种内存保存的机制,如果网络能够提供一个单独的内存变量,每次提取词向量的特征并刷新内存变量,直至最后一个输入完成,此时的内存变量即存储了所有序列的语义特征,并且由于输入序列之间的先后顺序,使得内存变量内容与序列顺序紧密关联。RNN 架构可视化如下:

右侧的网络是左侧的网络的展开后的结果。右侧的网络在每个时刻接受当前时刻输入以及上一时刻网络状态,并在每个时刻提取一个输出。
在每个时刻
t
t
t,网络层接受当前时刻的输入
x
t
x_t
xt 和上一个时刻的网络状态向量
h
t
−
1
h_t−1
ht−1,根据网络内部运算逻辑
h
t
=
f
θ
(
h
t
−
1
,
x
t
)
h_t=f_\\theta(h_t-1,x_t)
ht=fθ(ht−1,xt) 计算得到当前时刻的新状态向量
h
t
h_t
ht,并写入内存状态中。在每个时刻,网络层均有输出
o
t
o_t
ot,
o
t
=
g
Φ
(
t
)
o_t = g_\\Phi(t)
ot=gΦ(t),即根据网络的当前时刻状态向量计算后输出。
网络循环接受序列的每个特征向量
x
t
x_t
xt,并刷新内部状态向量
h
t
h_t
ht,同时形成输出
o
t
o_t
ot。这种网络结构就是循环神经网络 (Recurrent Neural Network, RNN) 结构。
3.2 基于深度学习的古彝文识别模型架构
手写文字识别已经成为人机交互最便捷的手段之一,拥有广泛的应用前景。在识别图像中手写文字的问题中,我们需要同时处理图像数据和顺序数据。在传统的古彝文字识别方法中,设计的解决方案通常需要人工参与。例如:在图像上使用滑动窗口,窗口大小是字符的平均大小,以便可以检测每个字符,然后输出它检测到的具有较高置信度的字符。然而,窗口的大小或滑动窗口数量需要进行人工确认。因此,这本质上属于一个特征工程问题。
为了降低人工时间成本,可以通过卷积神经网络 (Convolutional Neural Networks, CNN) 提取图像特征,然后将这些特征作为输入传递给循环神经网络 (Recurrent Neural Network, RNN) 的各个时间戳,以便在各个时间戳提取输出。因此,我们将组合使用 CNN 和 RNN,通过这种方式解决手写文字识别问题,我们不必人工构建特征,只需要优化模型得到 CNN 和 RNN 的最佳参数。经典的文字识别架构如下所示:
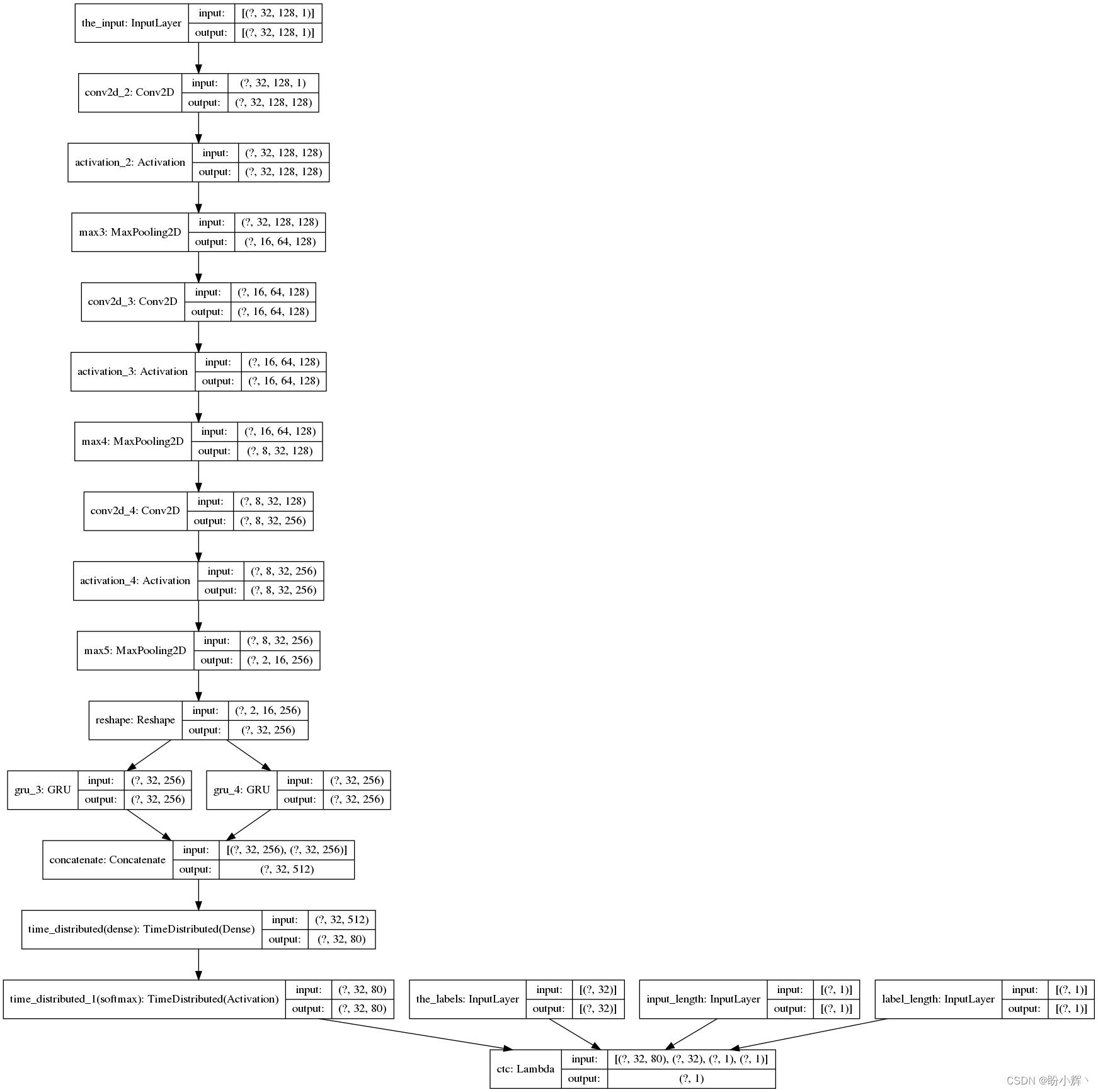
相对于传统古彝文识别模型,基于深度学习的方法对古彝文手写体的识别精度更高,且具有更高的效率。
4. 古彝文识别进展与展望
在 2022 年 12 月,合合信息与上海大学社会学院签署了校企合作协议,其将以完成“贵州古彝文图像识别及数字化校对项目”为目标,结合合合信息在智能文字识别领域的雄厚基础与上海大学在古彝文研究的丰富经验,赋能海量古彝文原籍数字化的道路,对于民族传统文化的保护与传承具有重要意义。
合合信息是行业领先的人工智能集大数据科技企业,智能文字识别技术更是合合信息的核心技术之一,先后在 ICDAR、ICPR 等人工智能国际竞赛中斩获 15 项冠军,在 CVPR、AAAI 等顶会上均有学术成果发表,合合信息的智能文字识别技术主要包括智能图像处理、复杂场景文字识别、自然语言处理三大核心模块,通过在智能文字识别和商业大数据领域的积累的优势,通过智能图像处理技术解决了影像采集不规范问题,能够极大的优化影像质量,为项目后续的文字信息提取与识别奠定基础,复杂文字识别适用于多语言、多版式、多样式等多种复杂场景,结合自然语言处理技术,能够获取识别结果的语义信息。
尽管古彝文识别研究仍处于起步阶段,但基于合合信息前期在甲骨文、金文等古文研究中的积累,通过引入强大的智能文字识别技术建立规范统一的数据库,能够极大的增强古彝文研究的可用性与连续性,减少繁琐的人工检索工作,合合信息联合上海大学推进的“原生态古彝文”研究项目将填补国内外在古彝文数字化研究领域的空白。
建立起古彝文数据库与翻译系统后,将能够显著提高古彝文识别的效率和准确率,对于小语种保护与古文化传承具有重要的里程碑意义。
小结
目前,针对古彝文识别的研究仍处于起步阶段,且大多数研究仅针对书写规范的古彝文,受限于字符库的匮乏,大部分模型仅能对常见的古彝文进行处理,因此可以说针对古彝文是别的研究非常稀少。合合信息基于深度学习的古彝文识别项目将填补当前国内外研究的空白,将深度学习技术引入古彝文识别将对文化保护和发展做出更多有益探索,让传统文化绽放更加绚丽之花。
相关链接
以上是关于人工智能助力古彝文识别,推动传统文化传承的主要内容,如果未能解决你的问题,请参考以下文章