EasyExcel 专题 深度解析读流程核心源码
Posted Dream_it_possible!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EasyExcel 专题 深度解析读流程核心源码相关的知识,希望对你有一定的参考价值。
目录
1) read()方法初始化ExcelReaderBuilder
2) .sheet()方法初始化ExcelReaderSheetBuilder
3) 根据excel类型选择对应的执行器executor的实现类XlsxAnalyser
1) 进入ExcelReaderSheetBuilder.doRead()方法
2) 转交给ExcelReader.read(ReadSheet... readSheet)
3) 读取excel的入口 excelReaderExecutor.execute()
5) 使用ModelBuildEventListener监听器映射成用户定义对象
EasyExcel将excel文件转换为xml文件,以SAX的形式按行解析,占用内存代价极小,能轻松解析百万条记录。
一、官网地址和版本
地址: https://github.com/alibaba/easyexcel
版本: 3.1.0
克隆下来后,使用git tag命令查看所有版本
git tag

git checkout v3.1.0编译源码:
mvn clean install -Dmaven.test.skip=true
 编译成功后,进入到easyexcel-test模块。
编译成功后,进入到easyexcel-test模块。
二、读核心源码解读
首先我们看怎么将excel sheet页里的内容读到 java的DemoData对象里。
1. 材料准备
用最新版的excel文件做演示,创建一个demo.xlsx文件,excel里有2个sheet页,分别为sheet1和sheet2, 内容相同,如下:
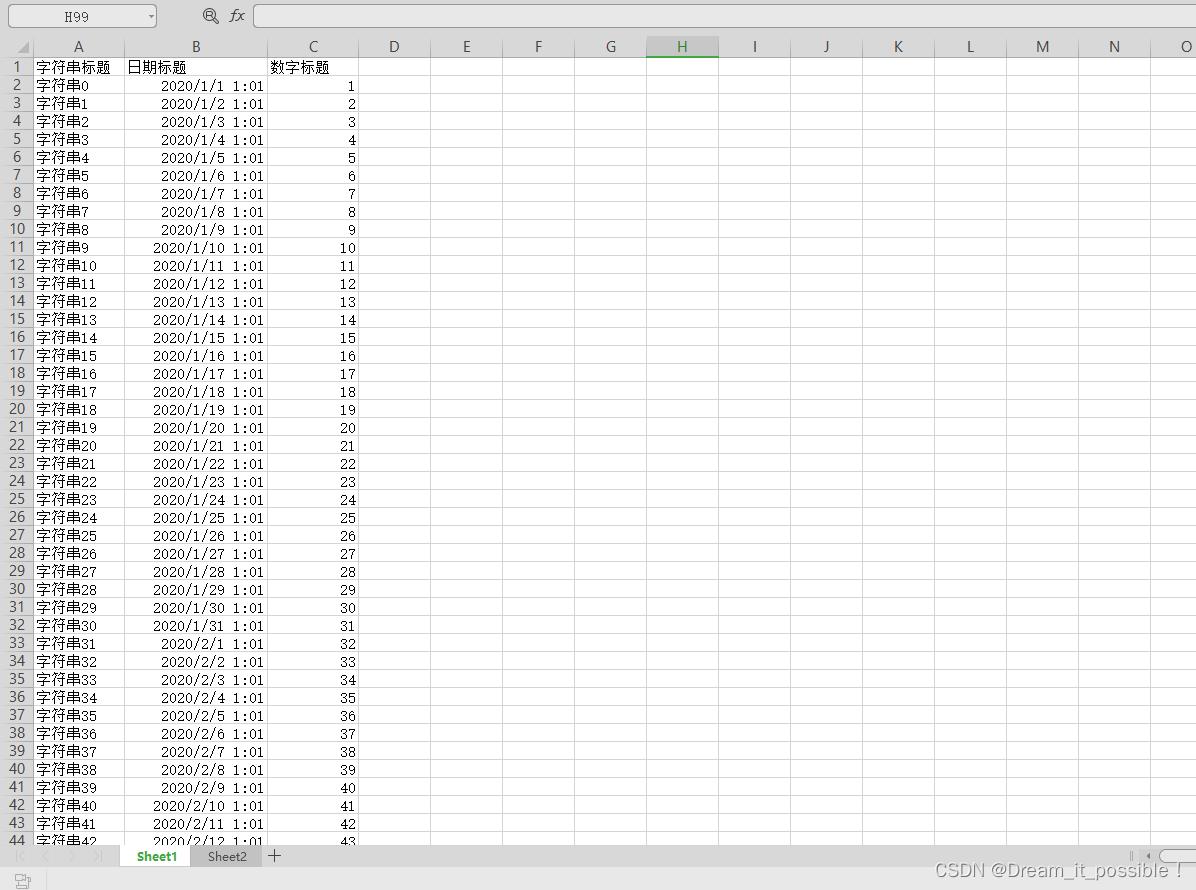
对应的model对象DemoData, 对应excel表格里的3列。
@Getter
@Setter
@EqualsAndHashCode
public class DemoData
private String string;
private Date date;
private Double doubleData;
用DemoData按行接收数据,例如用PageListener监听器,每次通过consumer回调100行数据出来。
2. EasyExcelFactory
EasyExcelFactory是EasyExcel的父类,它提供了开发者读和写的入口,我们可以借助EasyExcelFactory调用读、写操作。
fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();读取一个excel只需要三个参数: 带绝对路径的文件名,POJO的Class和一个监听器。
跟着EasyExcel.read()方法去解析读操作, 进入到EasyExcelFactory类,下面我将从初始化---->解析---> 收尾 这三个流程做解析。
3. 读excel---初始化
1) read()方法初始化ExcelReaderBuilder
在read()方法里初始化一个ExcelReaderBuilder, 通过readBuilder设置文件路径,excel标题和注册监听器。
public static ExcelReaderBuilder read(String pathName, Class head, ReadListener readListener)
ExcelReaderBuilder excelReaderBuilder = new ExcelReaderBuilder();
// 设置文件路径
excelReaderBuilder.file(pathName);
//设置excel标题,也支持无标题
if (head != null)
excelReaderBuilder.head(head);
// 注册监听器
if (readListener != null)
excelReaderBuilder.registerReadListener(readListener);
return excelReaderBuilder;
重要点: 根据ExcelReaderBuilder初始化一个ReadWorkBook类, ReadWorkBoook类包含了读取Excel的内容,用流的形式进行保存。
private final ReadWorkbook readWorkbook;
public ExcelReaderBuilder()
this.readWorkbook = new ReadWorkbook();
2) .sheet()方法初始化ExcelReaderSheetBuilder
通过sheet()方法,通过build()方法初始化ExcelReaderSheetBuilder, 并设置表格名称、表格序号。
public ExcelReaderSheetBuilder sheet(Integer sheetNo, String sheetName)
// 初始化表格建造器
ExcelReaderSheetBuilder excelReaderSheetBuilder = new ExcelReaderSheetBuilder(build());
if (sheetNo != null)
// 设置表格序号
excelReaderSheetBuilder.sheetNo(sheetNo);
if (sheetName != null)
//设置表格名称
excelReaderSheetBuilder.sheetName(sheetName);
return excelReaderSheetBuilder;
主要点,在build()方法里初始化了excelReader和readSheet对象, 为后续读取工作做准备。
public ExcelReader build()
return new ExcelReader(readWorkbook);
同时在ExcelReader的构造方法里初始化ExcelAnalyser的实现类ExcelAnalyserImpl, ExcelAnalyserImpl是分析excel的核心实现类。
/**
* Analyser
*/
private final ExcelAnalyser excelAnalyser;
public ExcelReader(ReadWorkbook readWorkbook)
excelAnalyser = new ExcelAnalyserImpl(readWorkbook);
然后用初始化好了的excelReader去初始化ExcelReaderSheetBuilder,同时初始readSheet对象后续会做为ExcelReader.read()方法的参数。
private ExcelReader excelReader;
/**
* Sheet
*/
private final ReadSheet readSheet;
public ExcelReaderSheetBuilder()
this.readSheet = new ReadSheet();
public ExcelReaderSheetBuilder(ExcelReader excelReader)
this.readSheet = new ReadSheet();
this.excelReader = excelReader;
3) 根据excel类型选择对应的执行器executor的实现类XlsxAnalyser
在ExcelAnalyserImpl的构造方法里实现了初始化ExcelReaderExecutor的操作,根据不同的文件类型,选择使用不同的Executor, 比如后缀名为xlsx类型的excel使用XlsxAnalyser解析器。
public ExcelAnalyserImpl(ReadWorkbook readWorkbook)
try
// 根据excel的类型选择对应的executor
choiceExcelExecutor(readWorkbook);
catch (RuntimeException e)
finish();
throw e;
catch (Throwable e)
finish();
throw new ExcelAnalysisException(e);

private void choiceExcelExecutor(ReadWorkbook readWorkbook) throws Exception
ExcelTypeEnum excelType = ExcelTypeEnum.valueOf(readWorkbook);
switch (excelType)
case XLS:
POIFSFileSystem poifsFileSystem;
if (readWorkbook.getFile() != null)
poifsFileSystem = new POIFSFileSystem(readWorkbook.getFile());
else
poifsFileSystem = new POIFSFileSystem(readWorkbook.getInputStream());
// So in encrypted excel, it looks like XLS but it's actually XLSX
if (poifsFileSystem.getRoot().hasEntry(Decryptor.DEFAULT_POIFS_ENTRY))
InputStream decryptedStream = null;
try
decryptedStream = DocumentFactoryHelper
.getDecryptedStream(poifsFileSystem.getRoot().getFileSystem(), readWorkbook.getPassword());
XlsxReadContext xlsxReadContext = new DefaultXlsxReadContext(readWorkbook, ExcelTypeEnum.XLSX);
analysisContext = xlsxReadContext;
excelReadExecutor = new XlsxSaxAnalyser(xlsxReadContext, decryptedStream);
return;
finally
IOUtils.closeQuietly(decryptedStream);
// as we processed the full stream already, we can close the filesystem here
// otherwise file handles are leaked
poifsFileSystem.close();
if (readWorkbook.getPassword() != null)
Biff8EncryptionKey.setCurrentUserPassword(readWorkbook.getPassword());
XlsReadContext xlsReadContext = new DefaultXlsReadContext(readWorkbook, ExcelTypeEnum.XLS);
xlsReadContext.xlsReadWorkbookHolder().setPoifsFileSystem(poifsFileSystem);
analysisContext = xlsReadContext;
excelReadExecutor = new XlsSaxAnalyser(xlsReadContext);
break;
case XLSX:
XlsxReadContext xlsxReadContext = new DefaultXlsxReadContext(readWorkbook, ExcelTypeEnum.XLSX);
analysisContext = xlsxReadContext;
// 同时通过openxml4j将excel文件转换为xml文件
excelReadExecutor = new XlsxSaxAnalyser(xlsxReadContext, null);
break;
case CSV:
CsvReadContext csvReadContext = new DefaultCsvReadContext(readWorkbook, ExcelTypeEnum.CSV);
analysisContext = csvReadContext;
excelReadExecutor = new CsvExcelReadExecutor(csvReadContext);
break;
default:
break;
4) 使用OPCPackage将Excel文件转换为Xml
接着上一步,进入到XlsxAnalyser的构造方法里,通过OPCPackage将excel文件转换为一个zip文件
OPCPackage.open(xlsxReadWorkbookHolder.getFile());里面包含了excel所有相关内容的xml形式的展示, OPCPackage的实现通过ZipPackage

5) 查看excel转换后的xml形式
我们可以写一个小demo,使用opcPackage.save(path)方法将zip存入到磁盘上。
public void testExcelTransferToXml() throws InvalidFormatException, IOException
// 使用OPCPackage打开一个压缩包
String path = TestFileUtil.getPath() + "demo/";
File file = new File(path + "demo.xlsx");
OPCPackage opcPackage = OPCPackage.open(file);
List<PackagePart> parts = opcPackage.getParts();
File targetFile = new File(path + "result.zip");
opcPackage.save(targetFile);
System.out.println();
打开zip文件后,长这样, sheet表单里的内容存放在worksheets目录下:

到此,一个Analyser的完整初始化流程就结束了,同时在executor的实现类里将EXCEL转换为XML,这些动作就是为了读而做准备。
4. 读excel---解析
1) 进入ExcelReaderSheetBuilder.doRead()方法
public void doRead()
if (excelReader == null)
throw new ExcelGenerateException("Must use 'EasyExcelFactory.read().sheet()' to call this method");
// build()方法初始化ExcelReaderBuilder,
excelReader.read(build());
excelReader.finish();
2) 转交给ExcelReader.read(ReadSheet... readSheet)
用初始化好的excelAnalyser去分析表格列表,一个ReadSheet就是一个sheet页。
public ExcelReader read(List<ReadSheet> readSheetList)
excelAnalyser.analysis(readSheetList, Boolean.FALSE);
return this;
3) 读取excel的入口 excelReaderExecutor.execute()
ExcelAnalyserImpl里的anlysis方法里的execelReadExecutor.execute()方法是读取excel的入口, readAll参数默认为false。
public void analysis(List<ReadSheet> readSheetList, Boolean readAll)
try
if (!readAll && CollectionUtils.isEmpty(readSheetList))
throw new IllegalArgumentException("Specify at least one read sheet.");
analysisContext.readWorkbookHolder().setParameterSheetDataList(readSheetList);
analysisContext.readWorkbookHolder().setReadAll(readAll);
try
//执行excel读取的入口
excelReadExecutor.execute();
catch (ExcelAnalysisStopException e)
if (LOGGER.isDebugEnabled())
LOGGER.debug("Custom stop!");
catch (RuntimeException e)
finish();
throw e;
catch (Throwable e)
finish();
throw new ExcelAnalysisException(e);
在analysis方法执行前,我们可以发现在AnalysisImpl的构造方法里根据Excel类型创建了不同类型的执行器choiceExcelExecutor(readWorkBook),其中CsvExcelReaderExecutor为解析CSV用的执行器、XlsSaxAnalyser为解析03版的excel的执行器(后缀为.xls的excel) 、XlsxSaxAnalyser 为解析07版excel的执行器。

parseXmlSource方法继续xml文件里的内容。
4) 如何解析xml?
SAX提供了一个ContentHandler接口给开发者,我们可以实现ContentHandler接口来自定义内容处理器,重写ContentHandler里的startElement()方法即可,XlsxRowHandler为定义的实现类
parseXmlSource(sheetMap.get(readSheet.getSheetNo()), new XlsxRowHandler(xlsxReadContext));
因此解析的时候会在XlsxRowHandler里的startElement方法里进行

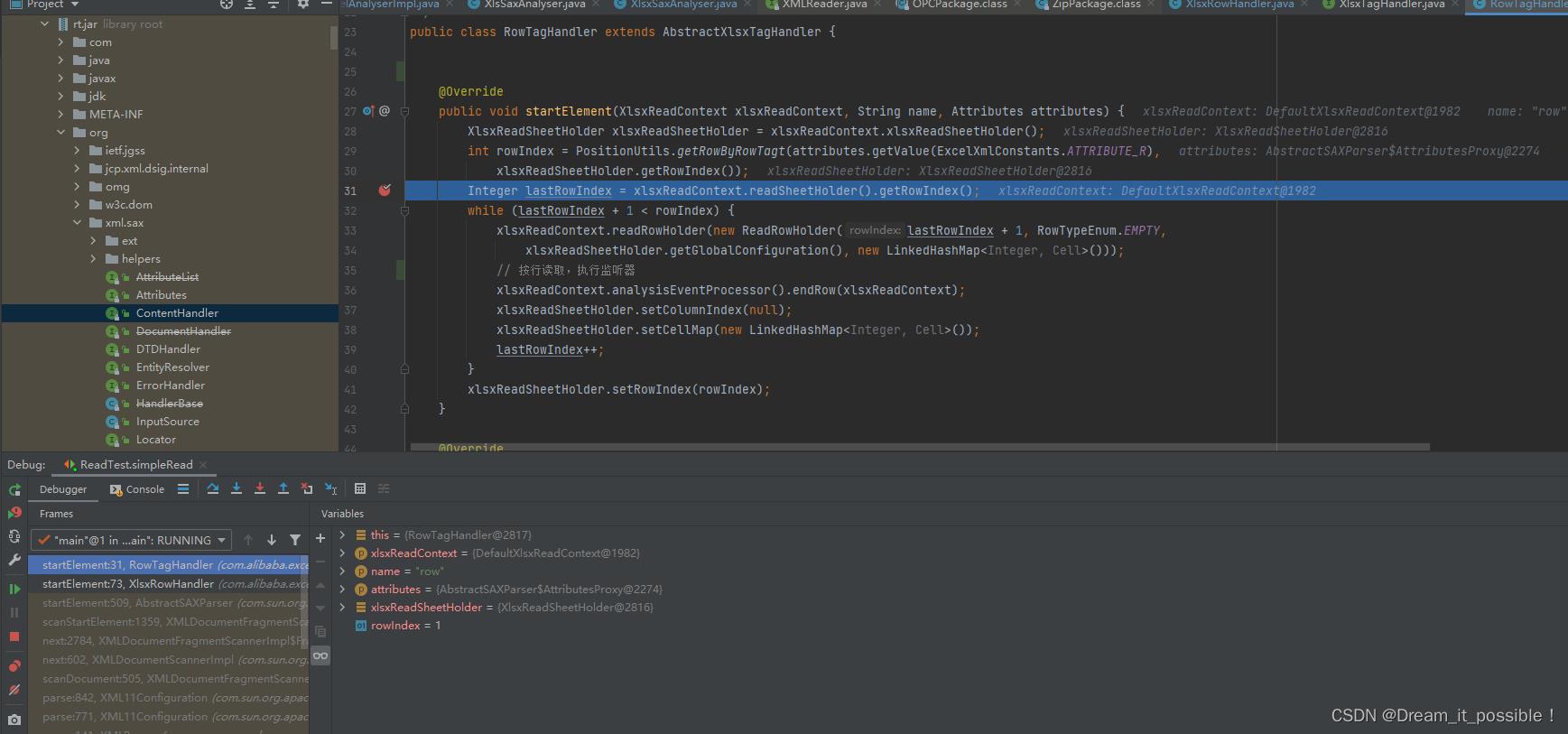
我们可以发现这里用到了策略模式,根据name获取到对应的XlsxTagHandler, 根据excel里的标签去选择对应的handler。
然后进入到RowTagHandler的startElement方法,按照xml的标签去解析。
5) 使用ModelBuildEventListener监听器映射成用户定义对象
当满足while条件时,进入到xlsxReadContext.analysisEventProcessor().endRow(xlsxReadContext);
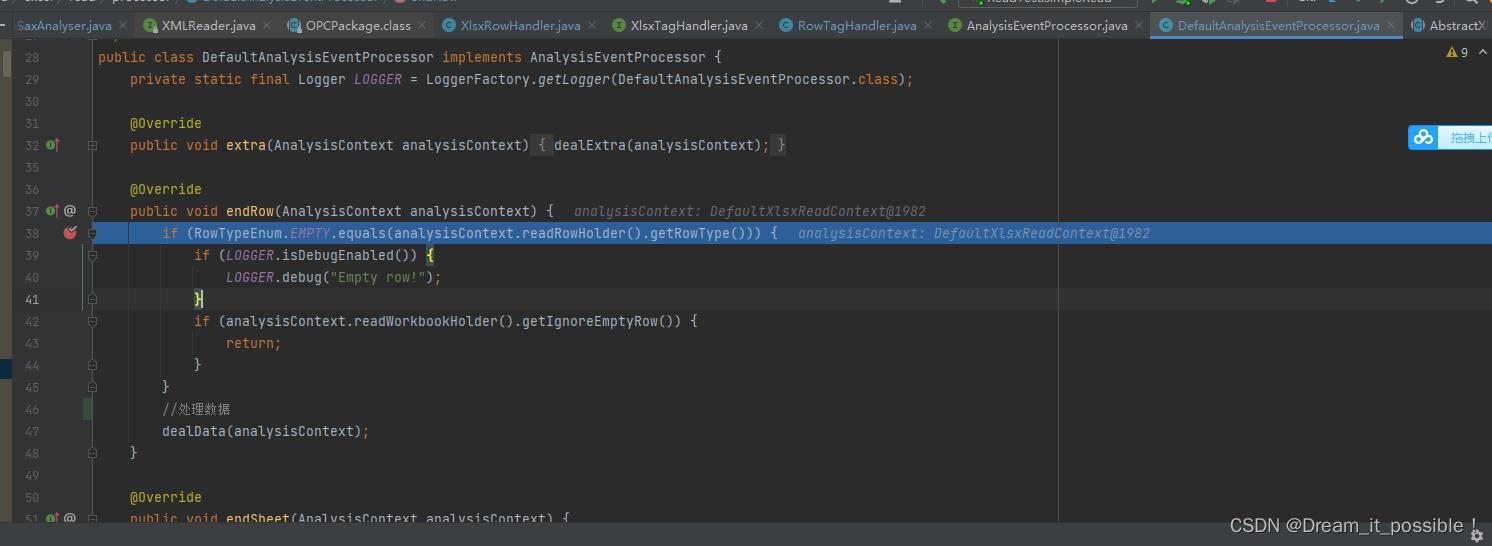
然后进入到dealData(analysisContext)方法,根据rowIndex当前行判断是否为数据,如果是数据,那么就执行监听器的invoke方法,如果是标题,那么就执行监听器的invokeHead()方法,analysisContext里的ReadHolder提供了一个默认的Listener-----ModelBuildEventListener。

ModelBuildEventListener的用处是将cellDataMap在builderUserModel转换为一个开发者指定的对象, 并用ReadRowHolder的currentRowAnalysisResult属性接收。

返回用户对象后,会在for循环里执行下一个监听器,该监听器为我们指定的PageReaderListener。

进入到PageReaderListener的invoke方法获取到用户对象。
@Override
public void invoke(T data, AnalysisContext context)
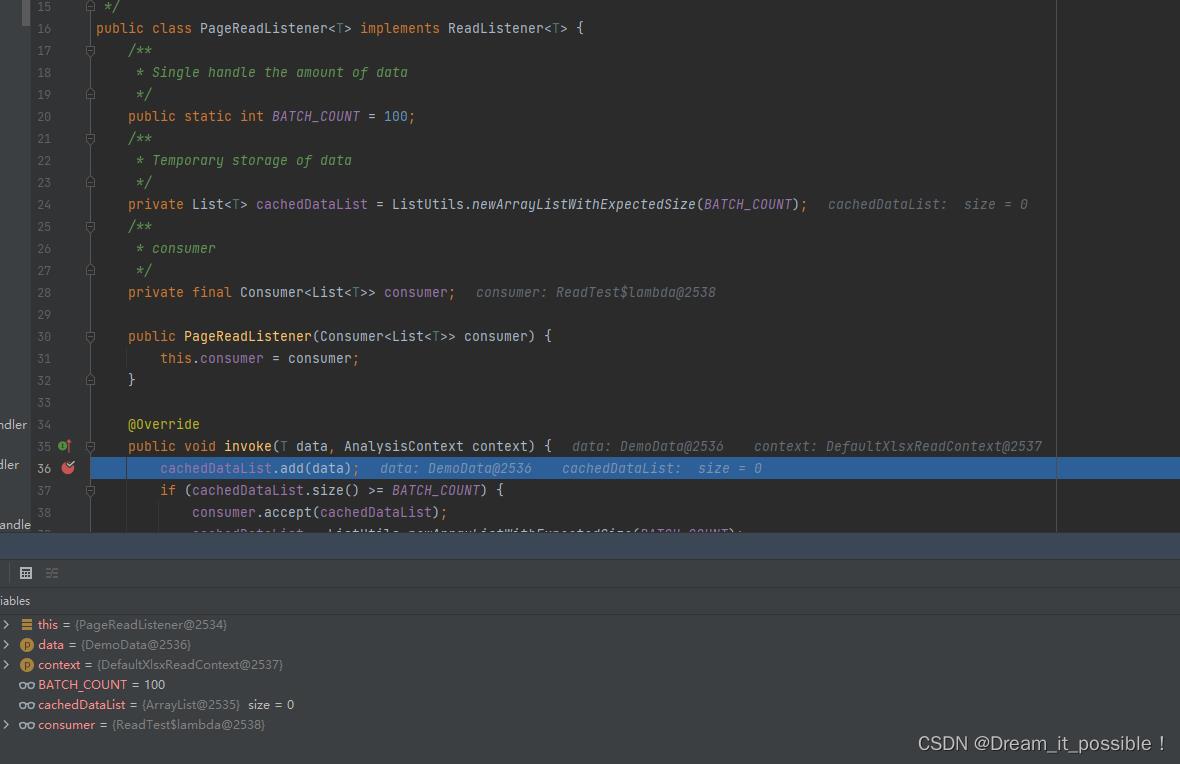
cachedDataList.add(data);
if (cachedDataList.size() >= BATCH_COUNT)
consumer.accept(cachedDataList);
cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);

然后每次读完BATCH_COUNT条数据,执行一次回调consumer.accept(cachedDataList)。
6) 执行收尾工作
再次进入到XlsxSaxAnalyser的execute()方法, 解析完后,执行了收尾工作
xlsxReadContext.analysisEventProcessor().endSheet(xlsxReadContext);
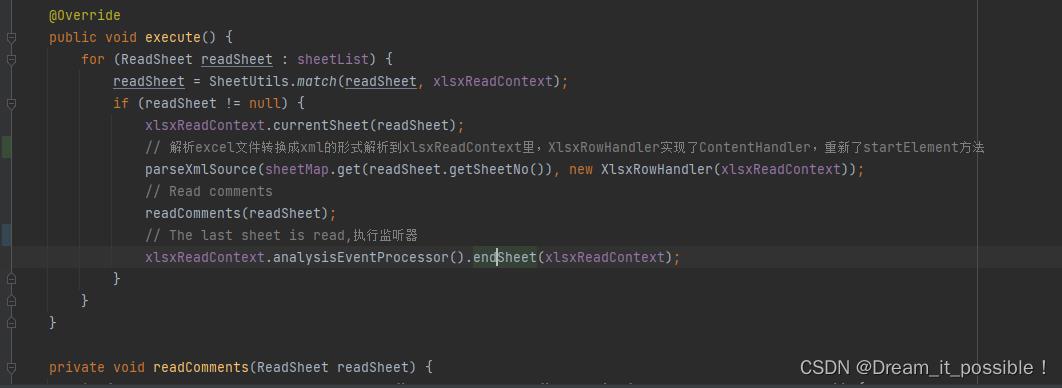
进入到PageReaderListener接口里的doAfterAllAnalysed, 如果cachedDataList不为空,继续回调。
@Override
public void doAfterAllAnalysed(AnalysisContext context)
if (CollectionUtils.isNotEmpty(cachedDataList))
consumer.accept(cachedDataList);
比如我定义的BACTH_COUNT=100, 每次满100条我才回调,我excel里只有10条记录,那么就不能在invoke方法里回调了,所以这里一定要进行收尾。
以上是关于EasyExcel 专题 深度解析读流程核心源码的主要内容,如果未能解决你的问题,请参考以下文章
高并发通过ThreadPoolExecutor类的源码深度解析线程池执行任务的核心流程