知识蒸馏-Distilling the knowledge in a neural network
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识蒸馏-Distilling the knowledge in a neural network相关的知识,希望对你有一定的参考价值。
参考技术A“很多昆虫在幼虫形态的时候是最擅长从环境中吸取能量和养分的,而当他们成长为成虫的时候则需要擅长完全不同能力比如迁移和繁殖。”在2014年Hinton发表的知识蒸馏的论文中用了这样一个很形象的比喻来说明知识蒸馏的目的。在大型的机器学习任务中,我们也用两个不同的阶段 training stage 和 deployment stage 来表达两种不同的需求。training stage(训练阶段)可以利用大量的计算资源不需要实时响应,利用大量的数据进行训练。但是在deployment stage (部署阶段)则会有很多限制,比如计算资源,计算速度要求等。知识蒸馏就是为了满足这种需求而设计的一种模型压缩的方法。
知识蒸馏的概念最早是在2006年由Bulica提出的,在2014年Hinton对知识蒸馏做了归纳和发展。知识蒸馏的主要思想是训练一个小的网络模型来模仿一个预先训练好的大型网络或者集成的网络。这种训练模式又被称为 "teacher-student",大型的网络是“老师”,小型的网络是“学生”。
在知识蒸馏中,老师将知识传授给学生的方法是:在训练学生的过程中最小化一个以老师预测结果的概率分布为目标的损失函数。老师预测的概率分布就是老师模型的最后的softmax函数层的输出,然而,在很多情况下传统的softmax层的输出,正确的分类的概率值非常大,而其他分类的概率值几乎接近于0。因此,这样并不会比原始的数据集提供更多有用的信息,没有利用到老师强大的泛化性能,比如,训练MNIST任务中数字‘3’相对于数字‘5’与数字‘8’的关系更加紧密。为了解决这个问题,Hinton在2015年发表的论文中提出了‘softmax temperature’的概念,对softmax函数做了改进:
这里的 就是指 temperature 参数。当 等于1 时就是标准的softmax函数。当 增大时,softmax输出的概率分布就会变得更加 soft(平滑),这样就可以利用到老师模型的更多信息(老师觉得哪些类别更接近于要预测的类别)。Hinton将这样的蕴含在老师模型中的信息称之为 "dark knowledge",蒸馏的方法就是要将这些 "dark knowledge" 传给学生模型。在训练学生的时候,学生的softmax函数使用与老师的相同的 ,损失函数以老师输出的软标签为目标。这样的损失函数我们称为"distillation loss"。
在Hinton的论文中,还发现了在训练过程加上正确的数据标签(hard label)会使效果更好。具体方法是,在计算distillation loss的同时,我利用hard label 把标准的损失( )也计算出来,这个损失我们称之为 "student loss"。将两种 loss 整合的公式如下:
这里的 是输入, 是学生模型的参数, 是交叉熵损失函数, 是 hard label , 是参数有 的函数, 是系数, 分别是学生和老师的logits输出。模型的具体结构如下图所示:
在上述公式中, 是作为超参数人为设置的,Hinton的论文中使用的 的范围为1到20,他们通过实验发现,当学生模型相对于老师模型非常小的时候, 的值相对小一点效果更好。这样的结果直观的理解就是,如果增加 的值,软标签的分布蕴含的信息越多导致一个小的模型无法"捕捉"所有信息但是这也只是一种假设,还没有明确的方法来衡量一个网络“捕捉”信息的能力。关于 ,Hinton的论文中对两个loss用了加权平均: 。他们实验发现,在普通情况下 相对于 非常小的情况下能得到最好的效果。其他人也做了一些实验没用加权平均,将 设置为1,而对 进行调整。
Hinton的论文中做了三个实验,前两个是MNIST和语音识别,在这两个实验中通过知识蒸馏得到的学生模型都达到了与老师模型相近的效果,相对于直接在原始数据集上训练的相同的模型在准确率上都有很大的提高。下面主要讲述第三个比较创新的实验:将知识蒸馏应用在训练集成模型中。
训练集成模型(训练多个同样的模型然后集成得到更好的泛化效果)是利用并行计算的非常简单的方法,但是当数据集很大种类很多的时候就会产生巨大的计算量而且效果也不好。Hinton在论文中利用soft label的技巧设计了一种集成模型降低了计算量又取得了很好的效果。这个模型包含两种小模型:generalist model 和 specialist model(网络模型相同,分工不同)整个模型由很多个specialist model 和一个generalist model 集成。顾名思义generalist model 是负责将数据进行粗略的区分(将相似的图片归为一类),而specialist model(专家模型)则负责将相似的图片进行更细致的分类。这样的操作也非常符合人类的大脑的思维方式先进行大类的区分再进行具体分类,下面我们看这个实验的具体细节。
实验所用的数据集是谷歌内部的JFT数据集,JFT数据集非常大,有一亿张图片和15000个类别。实验中 generalist model 是用所有数据集进行训练的,有15000个输出,也就是每个类别都有一个输出概率。将数据集进行分类则是用Online k-means聚类的方法对每张图片输入generalist model后得到的软标签进行聚类,最终将3%的数据为一组分发给各个specialist,每个小数据集包含一些聚集的图片,也就是generalist认为相近的图片。
在specialist model的训练阶段,模型的参数在初始化的时候是完全复制的generalist中的数值(specialist和generalist的结构是一模一样的),这样可以保留generalist模型的所有知识,然后specialist对分配的数据集进行hard label训练。但是问题是,specialist如果只专注于分配的数据集(只对分配的数据集训练)整个网络很快就会过拟合于分配的数据集上,所以Hinton提出的方法是用一半的时间进行hard label训练,另一半的时间用知识蒸馏的方法学习generalist生成的soft label。这样specialist就是花一半的时间在进行小分类的学习,另一半的时间是在模仿generalist的行为。
整个模型的预测也与往常不同。在做top-1分类的时候分为以下两步:
第一步:将图片输入generalist model 得到输出的概率分布,取概率最大的类别k。
第二步:取出数据集包含类别k的所有specialists,为集合 (各个数据集之间是有类别重合的)。然后求解能使如下公式最小化的概率分布q作为预测分布。
这里的KL是指KL散度(用于刻画两个概率分布之间的差距) 和 分别是测试图片输入generalist 和specialists(m)之后输出的概率分布,累加就是考虑所有属于 集合的specialist的“意见”。
由于Specialist model的训练数据集很小,所以需要训练的时间很短,从传统方法需要的几周时间减少到几天。下图是在训练好generalist模型之后逐个增加specialist进行训练的测试结果:
从图中可以看出,specialist个数的增加使top1准确个数有明显的提高。
本文结合Hinton在2014年发表的论文对知识蒸馏和相关实验做了一个简单的介绍,如今很多模型都用到了知识蒸馏的方法,但知识蒸馏在深度学习中还是非常新的方向,还有非常多的应用场景等待研究。
项目地址: https://momodel.cn/explore/5dc3b1223752d662e35925a3?type=app
[1]Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015.
[2] https://nervanasystems.github.io/distiller/knowledge_distillation.html
[3] https://www.youtube.com/watch?v=EK61htlw8hY&t=3323s
Distilling the Knowledge in a Neural Network
其实应该最先写这篇文章的总结的,之前看了忘了记录
Motivation
one hot label会将所有不正确的类别概率都设置为0,而一个好的模型预测出来的结果,这些不正确的类别概率是有不同的,他们之间概率的相对大小其实蕴含了更多的信息,代表着模型是如何泛化判别的。
比如一辆轿车,一个模型更有可能把它预测成卡车而不是猫,这其实给出了比one hot label更多的信息即轿车和卡车更像,而和猫不像。
如果一个大的模型做到了很好的泛化性能,那我们可以用一个小的模型去模拟他的泛化结果去达到较好的效果
Method
Loss = CE(softmax(predict), one hot label) + alpha * T * T * CE(softmax(predict/T), soft target)
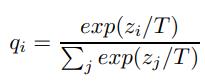
T作为一个超参,当T很大时,qi会更加soft,比如T趋于无穷大,则qi=(1/n, 1/n…)
当T较小时(比如T=1),需要去匹配更多的不正确类别的概率。如果student和teacher性能相差较大,可设置T为中等大小
VS Matching logits(Caruana提出的)
Matching logits(https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf) is a special case of distillation
C = CE(softmax(predict/T), soft target),根据CE的求导公式得
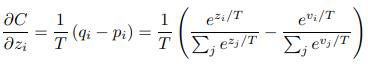
如果temperature T比logits的量级(magnitude)要大得多,那么zi/T->0,zi<0时从左边趋近0,>0时从右边趋近0,所有e^(zi/T) =1+zi/T
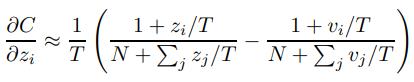
假设对于每一个transfer case,都有logits的均值为0,所以上式可以简化为

所以,如果temperature T很高,如果对于每一个transfer case,都有logits的均值为0,那么distillation就等价于最小化1/2(zi−vi)^2,也就是Caruana提出的使得复杂模型的logits和小模型的logits的平方差最小
https://daiwk.github.io/posts/dl-knowledge-distill.html
Soft Targets as Regularizers
用soft target进行训练避免了过拟合

以上是关于知识蒸馏-Distilling the knowledge in a neural network的主要内容,如果未能解决你的问题,请参考以下文章