运维实战 容器部分 Kubernetes集群部署
Posted 洛冰音
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运维实战 容器部分 Kubernetes集群部署相关的知识,希望对你有一定的参考价值。
运维实战 容器部分 Kubernetes集群部署
简介
Kubernetes来源于Borg, 对计算资源进行了更高层次的抽象, 通过将容器进行细致的组合, 将最终的应用服务交给用户.与Docker相比, k8s的组件选择更为灵活, 可以按照业务需求对组件进行更替.
优势
- 隐藏资源管理和错误处理, 用户仅需要关注应用的开发
- 具有高可用 高可靠的特性
- 可以运行在由成千上万的机器联合而成的集群中, 进而平坦负载
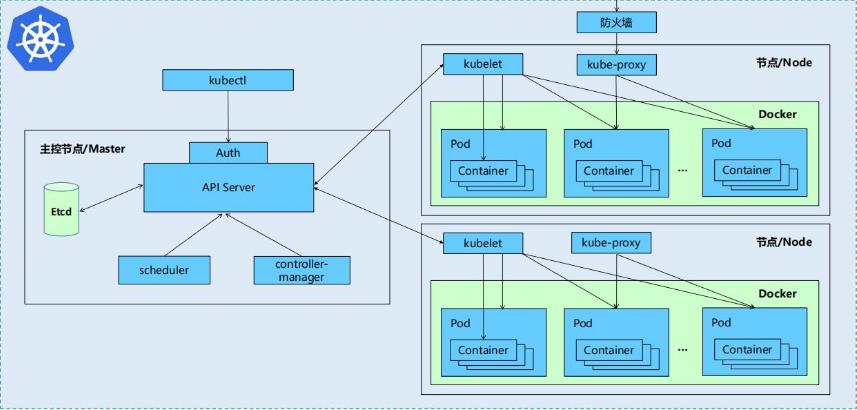
Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc), 一切都基于分布式的存储系统.
设计架构
Kubernetes核心组件
etcd 保存了整个集群的状态
apiserver 提供了资源操作的唯一入口, 并提供认证, 授权, 访问控制, API注册和发现等机制
controller manager 负责维护集群的状态, 比如故障检测, 自动扩展, 滚动更新等
scheduler 负责资源的调度, 按照预定的调度策略将Pod调度到相应的机器上
kubelet 负责维护容器的生命周期, 同时也负责Volume(CVI)和网络(CNI)的管理
Container runtime 负责镜像管理以及Pod和容器的真正运行(CRI)
kube-proxy 负责为Service提供cluster内部的服务发现和负载均衡
一些常用的扩展插件(Add-ons)
kube-dns 负责为整个集群提供DNS服务
Ingress Controller 为服务提供外网入口
Heapster 提供资源监控
Dashboard 提供GUI
Federation 提供跨可用区的集群
Fluentd-elasticsearch 提供集群日志采集, 存储与查询

核心层对外提供API构建高层的应用, 对内提供插件式应用执行环境
应用层用于部署(无状态应用, 有状态应用, 批处理任务, 集群应用等)和路由(服务发现, DNS解析等)
管理层提供系统度量(如基础设施, 容器和网络的度量), 自动化(如自动扩展, 动态Provision等)以及策略管理(RBAC, Quota, PSP, NetworkPolicy等)
接口层负责kubectl命令行工具 客户端SDK以及集群联邦等等服务
安装部署
- 前期准备
关闭节点的selinux和iptables防火墙
##所有节点部署docker引擎
yum install -y docker-ce docker-ce-cli
vim /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
sysctl --system
systemctl enable docker
systemctl start docker
vim /etc/docker/daemon.json
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts":
"max-size": "100m"
,
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
mkdir -p /etc/systemd/system/docker.service.d
systemctl daemon-reload
systemctl restart docker
##禁用swap分区
swapoff -a
注释掉/etc/fstab文件中的swap定义
安装部署软件kubeadm/kubelet/kubectl
yum install -y kubelet kubeadm kubectl
##更改源为阿里云(这里出现了包的问题,采用私有仓库解决了)
##默认从k8s.gcr.io上下载组件镜像
vim /etc/yum.repos.d/k8s.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
systemctl enable --now kubelet
##查看默认配置信息
kubeadm config print init-defaults
##列出所需镜像
kubeadm config images list --image-repository registry.aliyuncs.com/google_containers
##拉取镜像
kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers
##初始化集群
kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository registry.aliyuncs.com/google_containers
##可能附加的参数
##使用flannel网络组件时添加
--pod-network-cidr=10.244.0.0/16
##指定k8s安装版本
--kubernetes-version
##节点扩容
kubeadm join --token b3a32e.7cef20447b55261e 172.25.0.11:6443 --discovery-token-ca-cert-hash sha256:bc718df41fdceb0db6c5380c7e27c204589b41dcb5f9a3bc52c254b707377f2f
##配置kubectl
useradd kubeadm
vim /etc/sudoers
kubeadm ALL=(ALL) NOPASSWD: ALL
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
##配置kubectl命令补齐功能
echo "source <(kubectl completion bash)" >> ~/.bashrc
##安装flannel网络组件
##https://github.com/coreos/flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
##其他网络组件
https://kubernetes.io/zh/docs/concepts/cluster-administration/addons/
##Master查看状态:
kubectl get cs
kubectl get node
kubectl get pod -n kube-system
##kubectl命令指南
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
##对其他节点的操作
[root@Server2 mnt]# scp /etc/yum.repos.d/k8s.repo Server3:/etc/yum.repos.d/
k8s.repo 100% 129 119.2KB/s 00:00
[root@Server2 mnt]# scp /etc/yum.repos.d/k8s.repo Server4:/etc/yum.repos.d/
k8s.repo 100% 129 125.1KB/s 00:00
[root@Server2 mnt]# ssh Server3 yum install -y kubelet kubeadm kubectl
[root@Server2 mnt]# ssh Server4 yum install -y kubelet kubeadm kubectl
[root@Server2 mnt]# systemctl enable --now kubelet
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
[root@Server2 mnt]# kubeadm config print init-defaults
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 1.2.3.4
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: node
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager:
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: 1.21.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler:
[root@Server2 mnt]# kubeadm config images list --image-repository registry.aliyuncs.com/google_containers
registry.aliyuncs.com/google_containers/kube-apiserver:v1.21.0
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.21.0
registry.aliyuncs.com/google_containers/kube-scheduler:v1.21.0
registry.aliyuncs.com/google_containers/kube-proxy:v1.21.0
registry.aliyuncs.com/google_containers/pause:3.4.1
registry.aliyuncs.com/google_containers/etcd:3.4.13-0
registry.aliyuncs.com/google_containers/coredns/coredns:v1.8.0
至此, 简单的部署完成了.
需要注意的是的:
K8S的拖取策略为always, 每次启动时都会与仓库比对软件版本- 因此每次启动集群时应该默认先启动仓库所在的主机, 否则会出现报错等问题
- 控制节点默认不参与工作
- 初始化节点时生成的
token默认有效时间为24小时,24小时后token失效, 无法用于添加新节点
kubeadm token list 列出有效token
kubeadm token create 创建新的token
Pod管理
-
Pod是可以创建和管理k8s计算的最小可部署单元, 一个pod代表集群中运行的一个进程, 每个pod都有一个唯一的IP. -
一个
pod可以包含一个或多个容器(通常是Docker), 多个容器间共享IPC,Network和UTC namespace.
虽然可以通过kubectl命令行方式来操作, 但通常还是推荐使用资源清单的方式.
kubectl get默认查看的是default的namespace中的信息, 通过指定namespace可以指定查看的信息.
Pod分为自主式Pod 和 由控制器控制的Pod
kubectl delete pod [名称]可以删除自主式Pod, 但有控制器的Pod是无法被直接删除的.
##创建自主式Pod
[root@Server2 mnt]# kubectl run nginx --image=nginx
pod/nginx created
##查看Pod情况
[root@Server2 mnt]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 0/1 ContainerCreating 0 2s <none> server3 <none> <none>
[root@Server2 mnt]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 73s 10.244.1.2 server3 <none> <none>
##测试Pod内nginx是否可用
[root@Server2 mnt]# curl 10.244.1.2
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
##删除自主式Pod并检测
[root@Server2 mnt]# kubectl delete pod nginx
pod "nginx" deleted
[root@Server2 mnt]# kubectl get pod -o wide
No resources found in default namespace.
Service
Service 是一个较为抽象的概念, 可以认为其被用于定义服务.
- 一个服务可以具有多个
Pod - 多个
Pod作为一个逻辑整体为业务服务 Service还定义了访问其中Pod的策略, 因此也常被成为微服务Service对其后端的Pod具有探针检测
交互式创建Service
kubectl expose deployment nginx --port=80 --target-port=80
此时Pod客户端可以通过Service名称访问后端的两个Pod
两种网络类型
| 类型 | 特点 |
|---|---|
| ClusterIP | 默认类型, 自动分配一个仅集群内部可以访问的虚拟IP |
| NodePort | 在ClusterIP基础上为Service在每台机器上绑定一个端口, 这样就可以通过NodeIP:NodePort来访问该服务 |
通过使用NodePort类型暴露端口的方式, 可以让外部客户端访问Pod
##修改service的type为NodePort
kubectl edit svc nginx
##在创建service时指定类型
kubectl expose deployment nginx --port=80 --target-port=80 --type=NodePort
Pod扩容与缩容
kubectl scale --replicas=6 deployment nginx
kubectl scale --replicas=3 deployment nginx
更新Pod镜像
kubectl set image deployment nginx nginx=nginx:1.16.0 --record
Pod回滚
##查看历史版本
kubectl rollout history deployment nginx
##版本回滚
kubectl rollout undo deployment nginx --to-revision=1
资源清单
一般来说遵循如下格式
apiVersion: group/version 指明api资源属于哪个群组和版本, 同一个组可以有多个版本
kind: 标记创建的资源类型, k8s主要支持以下资源类别
Pod,ReplicaSet,Deployment,StatefulSet,DaemonSet,Job,Cronjob
metadata: 元数据
name: 对像名称
namespace: 对象属于哪个命名空间
labels: 指定资源标签, 标签是一种键值数据
spec: 定义目标资源的期望状态
- 相关命令
##查询命令
kubectl api-versions
##查询Pod的帮助文档
kubectl explain pod
##查看Pod的标签
kubectl get pod --show-labels
##过滤含有app标签的Pod
kubectl get pod -l app
kubectl get pod -L app
##附加标签
kubectl label pod demo version=v1
##更改标签
kubectl label pod demo app=nginx --overwrite
##节点标签选择器
kubectl label nodes server2 disktype=ssd
##筛选节点标签
kubectl get nodes -l disktype
- 在资源清单中附加标签选择器
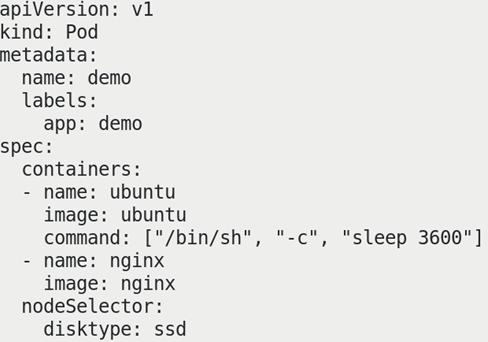
帮助信息中常见格式如下:
apiVersion <string> 表示字符串类型
metadata <Object> 表示需要嵌套多层字段
labels <map[string]string> 表示由k:v组成的映射
finalizers <[]string> 表示字串列表
ownerReferences <[]Object> 表示对象列表
hostPID <boolean> 布尔类型
priority <integer> 整型
name <string> -required- 如果类型后面接 -required-, 表示为必填字段
Pod生命周期
Pod可以包含多个容器, 应用运行在这些容器里面, 同时Pod也可以有一个或多个先于应用容器启动的Init 容器
Init容器的特点
- 总时运行到完成
- 不支持
Readiness探针, 因为它们必须在 Pod 就绪之前运行完成 - 上一个
Init容器运行成功才会运行下一个 - 如果
Init容器失败,K8S会不断重启Pod直到成功为止 - 如果
Pod对应的restartPolicy值为Never, 它不会重新启动
Init容器的作用
- 可以包含一些安装过程中应用容器内不存在的实用工具或个性化代码操作
- 可以安全的运行这些工具避免他们导致应用镜像安全性降低
- 应用镜像的创建者和部署者被分离
Init容器能以不同于Pod内应用容器的文件系统视图运行, 例如可具有访问Secrets的权限, 而应用容器不能够访问- 由于
Init容器必须在应用容器启动之前运行完成, 因此Init容器提供了一种机制来阻塞或延迟应用容器的启动, 直到满足了一组先决条件 - 一旦前置条件满足,
Pod内的所有的应用容器会并行启动
容器探针
K8S采用探针对容器执行定期诊断
| 方法 | 判断方式 |
|---|---|
| ExecAction | 在容器内执行指定命令. 如果命令退出时返回码为0则认为诊断成功. |
| TCPSocketAction | 对指定端口上的容器的IP地址进行TCP检查. 如果端口打开, 则诊断被认为是成功的. |
| HTTPGetAction | 对指定的端口和路径上的容器的IP地址执行HTTP Get请求. 如果响应的状态码大于等于200且小于400则诊断被认为是成功的. |
每次探测都将获得以下三种结果之一
-
成功: 容器通过了诊断
-
失败: 容器未通过诊断
-
未知: 诊断失败, 因此不会采取任何行动
kubelet可以选择在容器上运行三种探针
| 探针类型 | 使用方法 |
|---|---|
| livenessProbe | 指示容器是否正在运行. 如果存活探测失败, 则kubelet会杀死容器, 并且容器将受到其 重启策略 的影响. 如果容器不提供存活探针, 则默认状态为Success. |
| readinessProbe | 指示容器是否准备好服务请求. 如果就绪探测失败, 端点控制器将从与 Pod 匹配的所有Service的端点中删除该Pod的IP地址. 初始延迟之前的就绪状态默认为Failure. 如果容器不提供就绪探针, 则默认状态为Success. |
| startupProbe | 指示容器中的应用是否已经启动. 如果提供了启动探测(startup probe), 则禁用所有其他探测, 直到它成功为止. 如果启动探测失败,kubelet将杀死容器, 容器服从其重启策略进行重启. 如果容器没有提供启动探测, 则默认状态为Success. |
重启策略
在资源清单中用restartPolicy字段标识, 可能的值为Always, OnFailure和Never, 默认为Always.
Pod的生命
一般来说, 直到被人为摧毁, Pod都不会消失.
虽然自主类Pod的创建很简单, 但一般还是建议创建适当的控制器来创建Pod
因为单独的Pod在机器故障的情况下没有办法自动复原, 而控制器却可以控制Pod的情况
控制器
概念解释
上文中有提过Pod分为自主式 和 被控制器管控两种.
生产环境主要使用控制器进行操作, 而不使用自主式Pod.
两者的主要区别在于
- 自主式Pod退出后不会被创建
- 被控制器管控的Pod, 在控制器的生命周期内始终会维持恒定的副本数
控制器的分类
Replication Controller
ReplicaSet
Deployment
DaemonSet
StatefulSet
Job
CronJob
HPA (Horizontal Pod Autoscaler)
Replication Controller/ReplicaSet
ReplicaSet是对于Replication Controller的扩展升级, 目前官方也更为推荐ReplicaSet
两者唯一的区别是选择器的支持不同, RS支持新的基于集合的选择器需求
RS确保在生命周期内, 运行中的Pod的副本数始终相同
尽管RS可以独立使用, 但是考虑到平滑升级等原因, 目前主要被Deployment调用来进行Pod的创建/删除/升级
Deployment
Deployment常用于定义生命RS, 而RS又用来生成Pod副本
典型的应用场景:
- 创建
Pod和ReplicaSet Pod的滚动更新和回滚Pod的扩容和缩容- 服务的暂停与恢复
DaemonSet
-
适合分布式架构的业务
-
DaemonSet可以确保全部或某些特定结点上运行一个Pod, 因为这一特性也常被用来部署集群存储/日志收集/监控Agent -
新加入集群的节点会被自动分配
Pod -
节点被移除时, 对应的
Pod也会被移除
DaemonSet 的典型用法:
| 作用 | 举例 |
|---|---|
| 集群存储 | glusterd, ceph |
| 日志收集 | fluentd, logstash |
监控Agent | Prometheus Node Exporter, Zabbix Agent |
用法解析
较为简单的用法, 为所有的节点分配一个DaemonSet
较为复杂的用法, 对没种类型的设备分配独立的DaemonSet
StatefulSet
- 需要网络存储才能使用, 特点为突出有序性
- 被用来管理有状态应用的工作负载 API 对象, 实例之间有不对等关系, 以及实例对外部数据有依赖关系的应用, 称为"有状态应用"
StatefulSet用来管理Deployment和扩展一组Pod, 并且能为这些 Pod 提供序号和唯一性保证
常用环境:
- 业务下的
Pod需要稳定且唯一的网络标识符 Pod需要稳定持久的存储方式- 业务本身要求有序性
- 可以实现有序优雅的部署/缩放
- 可以实现有序的滚动更新
Job和CronJob
与CE部分所学的定义基本相似.
Job用来执行批处理任务, 且只执行一次.
CronJob用来创建基于时间调度的Job, 周期性执行.
HPA
K8S中的一种资源对象, 能够根据某些指标对在StatefulSet,ReplicaController,ReplicaSet等集合中的Pod数量进行动态伸缩, 使运行在上面的服务对指标的变化有一定的自适应能力- 最起码的要求是需要提供动态监控指标
示例
ReplicaSet
部署一个含有4个副本的myapp集群, myapp软件版本为v1.
##资源清单内容
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v1
[root@Server2 mnt]# vim ReplicaSet.yaml
[root@Server2 mnt]# kubectl apply -f ReplicaSet.yaml
replicaset.apps/replicaset created
[root@Server2 mnt]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
replicaset-6jzjh 1/1 Running 0 8s 10.244.1.6 server3 <none> <none>
replicaset-9928t 1/1 Running 0 9s 10.244.2.5 server4 <none> <none>
replicaset-g4p5c 1/1 Running 0 9s 10.244.1.7 server3 <none> <none>
replicaset-tsjdg 1/1 Running 0 8s 10.244.2.4 server4 <none> <none>
[root@Server2 mnt]# kubectl get pod
NAME READY STATUS RESTARTS AGE
replicaset-6jzjh 1/1 Running 0 13s
replicaset-9928t 1/1 Running 0 14s
replicaset-g4p5c 1/1 Running 0 14s
replicaset-tsjdg 1/1 Running 0 13s
[root@Server2 mnt]# curl 10.244.1.6
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
##对上文中版本进行更改
修改镜像image: myapp:v1为image: myapp:v2,重新apply
会发现版本并没有更改, 新的Pod会更新为v2, 而已经存在的不会变化
Deplayment
部署一个含有4个副本的myapp集群, myapp软件版本为v1.
##资源清单内容
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v1
[root@Server2 mnt]# kubectl apply -f Deplayment.yaml
deployment.apps/deployment created
[root@Server2 mnt]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/deployment-59dff4cf5d-5kxhw 1/1 Running 0 5s
pod/deployment-59dff4cf5d-6g4jq 1/1 Running 0 5s
pod/deployment-59dff4cf5d-8rfgp 1/1 Running 0 5s
pod/deployment-59dff4cf5d-knlx8 1/1 Running 0 5s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/deployment 4/4 4 4 5s
NAME DESIRED CURRENT READY AGE
replicaset.apps/deployment-59dff4cf5d 4 4 4 5s
[root@Server2 mnt]# curl 10.244.1.8
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
##与上文相似的修改镜像版本后
[root@Server2 mnt]# curl 10.244.2.9
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
乍一看没有什么区别, 但是通过kubectl get all我们可以发现实际上的创建情况是这样的.
Deployment管理ReplicaSetReplicaSet管理Pod- 当出现版本更新时,
Deplpyment新建新的ReplicaSet, 新的ReplicaSet创建新的Pod, 实现滚动升级 - 旧的
ReplicaSet暂时保留但不存在内容, 方便进行回滚
DaemonSet
常用于部署Agent, 由于其定义和要求, 配置清单中不会也不能出现副本数的设置.
在每个节点上部署1个myapp, 版本为v1.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset
spec:
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: myapp:v1
[root@Server2 mnt]# kubectl apply -f DaemonSet.yaml
daemonset.apps/daemonset created
[root@Server2 mnt]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/daemonset-d5mhj 1/1 Running 0 6s
pod/daemonset-qnm9g 1/1 Running 0 6s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20h
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/daemonset 2 2 2 2 2 <none> 6s
可以看到每个节点出现了一个pod, 不会多也不会少.
当新增节点时, 会自动在新的结点上创建一个pod
在上面的清单中都出现了Selector选择器, 它用来关联控制器与Pod
这一关联是通过标签, 类似app: myapp来实现的, 凡是满足控制器要求标签的Pod都会被控制器纳入管辖
标签是通过template模板应用元数据配置到Pod上的
Service
Service可以看作一个接口, 其后端为一组提供相同服务的Pod.
通过访问Service, 可以实现服务发现和负载均衡.
Service默认只支持4层负载均衡能力, 没有7层功能.
常见的Service类型
| 类型 | 特性 |
|---|---|
| ClusterIP | 默认值, k8s系统给Service自动分配的虚拟IP, 只能在集群内部访问. |
| NodePort | 将Service通过指定的Node上的端口暴露给外部, 访问任意一个NodeIP:NodePort都将路由到ClusterIP |
| LoadBalancer | 在 NodePort的基础上, 借助 Cloud provider 创建一个外部的负载均衡器, 并将请求转发到 NodeIP:NodePort, 此模式只能在云服务器上使用. |
| ExternalName | 将服务通过 DNS CNAME 记录方式转发到指定的域名(通过spec.externlName设定). |
前期准备
Service由 kube-proxy 组件与iptables共同实现.
由于用到了iptables, 不难想到当处理Service时, 会在宿主机创建相当多的iptables规则, 存在的Pod越多, 刷新规则的频率就会越高, CPU的消耗也会越严重.
通过开启IPVS模式, 可以让集群增加更大量级的Pod.
##开启kube-proxy的ipvs模式
##在所有节点安装ipvsadm
yum install -y ipvsadm
##修改kube-proxy的模式
kubectl edit cm kube-proxy
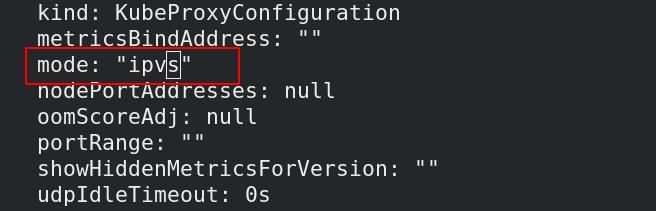
##删除现有的kube-proxy并使其自动创新生成
[root@Server2 mnt]# kubectl get pod -n kube-system |grep kube-proxy | awk 'system("kubectl delete pod "$1" -n kube-system")'
pod "kube-proxy-89rdg" deleted
pod "kube-proxy-rmg7c" deleted
pod "kube-proxy-v4qf8" deleted
IPVS模式下,kube-proxy会在Service创建后, 在宿主机上添加一个虚拟网卡kube-ipvs0, 用于分配Service IP.
kube-proxy通过Linux的IPVS模块, 以rr轮询方式调度Service中的Pod.
##检测kube-ipvs0
[root@Server2 mnt]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 52:54:00:fb:9f:7a brd ff:ff:ff:ff:ff:ff
inet 172.25.5.2/24 brd 172.25.5.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fefb:9f7a/64 scope link
valid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:0f:9c:84:0c brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
4: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether c6:08:5e:a9:a8:a6 brd ff:ff:ff:ff:ff:ff
inet 10.244.0.0/32 brd 10.244.0.0 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::c408:5eff:fea9:a8a6/64 scope link
valid_lft forever preferred_lft forever
5: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
link/ether 16:0b:df:ea:47:11 brd ff:ff:ff:ff:ff:ff
inet 10.244.0.1/24 brd 10.244.0.255 scope global cni0
valid_lft forever preferred_lft forever
inet6 fe80::140b:dfff:feea:4711/64 scope link
valid_lft forever preferred_lft forever
6: vethb6f8fa01@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default
link/ether 12:c0:c6:29:89:d8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::10c0:c6ff:fe29:89d8/64 scope link
valid_lft forever preferred_lft forever
7: veth9ed98fa8@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default
link/ether 6e:1b:0c:c4:3a:7e brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::6c1b:cff:fec4:3a7e/64 scope link
valid_lft forever preferred_lft forever
8: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether d2:23:f2:bd:58:ae brd ff:ff:ff:ff:ff:ff
9: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether 9a:43:8e:d1:09:35 brd ff:ff:ff:ff:ff:ff
inet 10.96.0.1/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.96.0.10/32 scope global kube-ipvs0
valid_lft forever preferred_lft forever
实践
ClusterIP方式创建Service
##编写资源清单, 采用默认的ClusterIP类型
apiVersion: v1
kind: Service
metadata:
name: web-service
spec:
ports:
- name: http
port: 80
targetPort: 80
selector:
app: myapp
type: ClusterIP
##可以看到服务生成, 并且只包含一个Cluster-IP用于容器内部访问
[root@Server2 mnt]# kubectl apply -f Deplayment.yaml
deployment.apps/deployment created
[root@Server2 mnt]# kubectl create -f Service.yaml
service/web-service created
[root@Server2 mnt]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/deployment-59dff4cf5d-2gjkl 1/1 Running 0 17s
pod/deployment-59dff4cf5d-5fh5x 1/1 Running 0 17s
pod/deployment-59dff4cf5d-6rwnh 1/1 Running 0 17s
pod/deployment-59dff4cf5d-vz844 1/1 Running 0 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 25h
service/web-service ClusterIP 10.107.171.59 <none> 80/TCP 7s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/deployment 4/4 4 4 17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/deployment-59dff4cf5d 4 4 4 17s
[root@Server2 mnt]# kubectl describe svc web-service
Name: web-service
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=myapp
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.107.171.59
IPs: 10.107.171.59
Port: http 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.11:80,10.244.1.12:80,10.244.2.10:80 + 1 more...
Session Affinity: None
Events: <none>
##能够看到其对应的后端Pod的IP
##通过kube-dns,其自动在内部进行了解析
[root@Server2 mnt]# kubectl get services kube-dns --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 24h

##在容器内进行测试, 可以发现Service实现了负载均衡
[root@Server2 mnt]# kubectl run test --image=reg.westos.org/library/busyboxplus -it
If you don't see a command prompt, try pressing enter.
/ # curl web-service
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
/ # curl web-service
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
/ # curl web-service
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
/ # curl web-service/hostname.html
deployment-59dff4cf5d-6rwnh
/ # curl web-service/hostname.html
deployment-59dff4cf5d-5fh5x
/ # curl web-service/hostname.html
deployment-59dff4cf5d-2gjkl
MatalLB
MatalLB用于在裸金属环境模拟云计算.
上文有提过LoadBalancer只能在云计算环境才能使用, 为了模拟云计算环境我们需要安装MatalLB
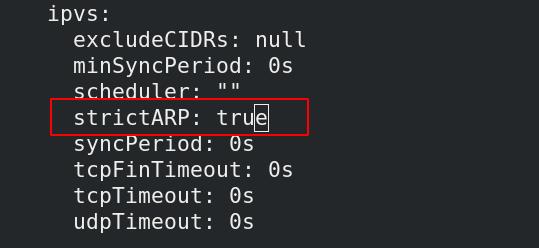
##设置IPVS模式并开启ARP选项
[root@Server2 mnt]# kubectl edit configmap -n kube-system kube-proxy
configmap/kube-proxy edited
[root@Server2 mnt]# kubectl get pod -n kube-system |grep kube-proxy | awk 'system("kubectl delete pod "$1" -n kube-system")'
pod "kube-proxy-t2vtg" deleted
pod "kube-proxy-zhkvd" deleted
pod "kube-proxy-zjm6j" deleted
##下载作为控制端的controller和作为客户端的speaker
[root@Server1 ~]# docker pull metallb/speaker:v0.9.6
v0.9.6: Pulling from metallb/speaker
ba3557a56b15: Pull complete
d858c667c29e: Pull complete
Digest: sha256:c66585a805bed1a3b829d8fb4a4aab9d87233497244ebff96f1b88f1e7f8f991
Status: Downloaded newer image for metallb/speaker:v0.9.6
docker.io/metallb/speaker:v0.9.6
[root@Server1 ~]# docker pull metallb/controller:v0.9.6
v0.9.6: Pulling from metallb/controller
ba3557a56b15: Already exists
6184982077d7: Pull complete
Digest: sha256:fbfdb9d3f55976b0ee38f3309d83a4ca703efcf15d6ca7889cd8189142286502
Status: Downloaded newer image for metallb/controller:v0.9.6
docker.io/metallb/controller:v0.9.6
##打Tag并上传到私有仓库保证后续使用
[root@Server1 ~]# docker tag metallb/controller:v0.9.6 reg.westos.org/metallb/controller:v0.9.6
[root@Server1 ~]# docker tag metallb/speaker:v0.9.6 reg.westos.org/metallb/speaker:v0.9.6
[root@Server1 ~]# docker push reg.westos.org/metallb/speaker:v0.9.6
The push refers to repository [reg.westos.org/metallb/speaker]
7a528695caed: Pushed
cb381a32b229: Pushed
v0.9.6: digest: sha256:dffdaee85e79393785f98f7fd7666fa7d9f53fd90d3319c59a622911ca2e0a09 size: 952
[root@Server1 ~]# docker push reg.westos.org/metallb/controller"reg.westos.org/metallb/controller^C
[root@Server1 ~]# docker push reg.westos.org/metallb/controller:v0.9.6
The push refers to repository [reg.westos.org/metallb/controller]
3fb31be155c6: Pushed
cb381a32b229: Mounted from metallb/speaker
v0.9.6: digest: sha256:99b79462af3d8b7d3b18dd31b854148b9d05365843d2c69ce7c3dd8a1f0d015d size: 952
开始部署
##添加官方提供的namespace.yaml 和 metallb.yaml
[root@Server2 mnt]# kubectl apply -f namespace.yaml
namespace/metallb-system created
[root@Server2 mnt]# kubectl apply -f metallb.yaml
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/controller created
podsecuritypolicy.policy/speaker created
serviceaccount/controller created
serviceaccount/speaker created
clusterrole.rbac.authorization.k8s.io/metallb-system:controller created
clusterrole.rbac.authorization.k8s.io/metallb-system:speaker created
role.rbac.authorization.k8s.io/config-watcher created
role.rbac.authorization.k8s.io/pod-lister created
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:controller created
clusterrolebinding.rbac.authorization.k8s.io/metallb-system:speaker created
rolebinding.rbac.authorization.k8s.io/config-watcher created
rolebinding.rbac.authorization.k8s.io/pod-lister created
daemonset.apps/speaker created
deployment.apps/controller created
##可以看到出现了新的namespace metallb-system
[root@Server2 mnt]# kubectl get ns
NAME STATUS AGE
default Active 25h
kube-node-lease Active 25h
kube-public Active 25h
kube-system Active 25h
metallb-system Active 63s
##此时如果查看其中的Pod状态会发现全部出现问题, 因为还需要添加密钥
[root@Server2 mnt]# kubectl -n metallb-system get pod
NAME READY STATUS RESTARTS AGE
controller-64f86798cc-w72bw 1/1 Running 0 94s
speaker-l5n5q 0/1 CreateContainerConfigError 0 以上是关于运维实战 容器部分 Kubernetes集群部署的主要内容,如果未能解决你的问题,请参考以下文章