一、说明
Hadoop 2.x相比较于1.x有了较大的改变,像MapReduce层面架构以及代码基本上是完全重写的,在HDFS层面加入了HA,Federation等特性,代码更加层次化和易读,同时加入的PB初期可能给阅读带来障碍,熟悉之后就没有太大问题了。
Pipeline一只是Hadoop重要的一个过程,不管是MR任务,Hive任务等等,最后都需要Pipeline将数据写入到HDFS中。所以熟悉Hadoop Pipeline过程还是很有意义的。
二、流程说明
Hadoop pipeline的建立可以由以下的流程图来说明,Pipeline建立牵扯的有NameNode,DataNode,DFSClient等结构。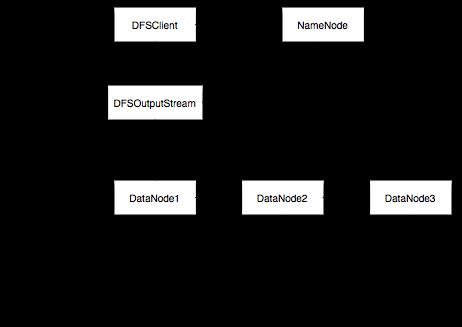
以下为简要说明
1、首先DFSClient向NameNode发送RPC Create请求,NameNode在INode中生成新的INodeFile并加入到新的LeaseManager中作为稍后写入的租约管理。
2、请求成功返回后,DFSClient生成一个OutputStream,既DFSOutputStream
3、行程pipeline之前向NameNode发送AddBlock请求,NameNode生成新的Block,选择要写入的DataNode节点,并将Block注册到INodeFile中,以及BlockManager中,准备写入
4、建立pipeline,根据NameNode返回的信息,找到一个primary Datanode作为第一个节点,准备写入
5、DataNode Socket接收后,首先将数据写入buffer中,然后写入到下一个节点,写入成功后将buffer中数据写入本地磁盘,并等待ACK信息
6、与5一样,写入下一个节点然后写入本地,最后等待ACK信息
7、如果ACK都成功返回后,发回给DFSClient,本次写入成功。
三、详细说明
首先明确一下DFSClient写入DataNode的一些基本概念。在大方面来说每个文件由一个或多个Block组成,这个Block可以有两个意义,一个是NameNode,DataNode中的Block,它是由Block id,generate stamp组成。另一个是指存储在DataNode磁盘中的Block,真正占据存储空间。
Block的size一般在conf中定义,默认是64M。
Hadoop写入过程中是通过Packet以及Chunk去传送的,每个Chunk是由512Byte的数据位和4Byte的校验位组成,每个Packet是由127个Chunk组成,大小是127*(512+4)=65532Byte。最后如果写入写到了Block size的边界位置,发送一个空白的Packet。


确认上面的一些概念以后,就可以来看下Pipeline了。还是按照二中流程图的步骤一步一步解析。
1、DFSClient向NameNode发送Create请求
DFSClients首先向NameNode发送Create请求,NameNode中首先在生成新的INodeFile:
INodeFile newNode = dir.addFile(src, permissions, replication, blockSize,
holder, clientMachine, clientNode);
if (newNode == null) {
throw new IOException("Unable to add " + src + " to namespace");
}
leaseManager.addLease(newNode.getFileUnderConstructionFeature()
.getClientName(), src);
|
并且在LeaseManager中加入Lease,Lease用于写入过程中的租约管理。然后再DFSClient中加入一个租约续期的线程,定期向NameNode续租约。
beginFileLease(src, result); |
2、生成DFSOutputStream
final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,
flag, progress, checksum, favoredNodes);
out.start();
|
3、申请新的Block
Pipeline建立时的状态为BlockConstructionStage.PIPELINE_SETUP_CREATE,向NameNode申请新的Block。主要的代码为:
// allocate new block, record block locations in INode.
newBlock = createNewBlock();
saveAllocatedBlock(src, inodesInPath, newBlock, targets);
dir.persistNewBlock(src, pendingFile);
offset = pendingFile.computeFileSize();
|
将新的Block与INodeFile关联,并且加入到BlockManager中。
4、建立Pipeline
与第一个DataNode建立Socket连接,端口是IPC端口,准备建立pipeline。
// send the request
new Sender(out).writeBlock(block, accessToken, dfsClient.clientName,
nodes, null, recoveryFlag? stage.getRecoveryStage() : stage,
nodes.length, block.getNumBytes(), bytesSent, newGS, checksum,
cachingStrategy.get());
// receive ack for connect
BlockOpResponseProto resp = BlockOpResponseProto.parseFrom(
PBHelper.vintPrefixed(blockReplyStream));
|
DataNode启动的时候会启动IPC Server,其中有个DataXceiver专门监听IPC端口,将各种请求转发,代码为:
/** Process op by the corresponding method. */
protected final void processOp(Op op) throws IOException {
switch(op) {
case READ_BLOCK:
opReadBlock();
break;
case WRITE_BLOCK:
opWriteBlock(in);
break;
case REPLACE_BLOCK:
opReplaceBlock(in);
break;
case COPY_BLOCK:
opCopyBlock(in);
break;
case BLOCK_CHECKSUM:
opBlockChecksum(in);
break;
case TRANSFER_BLOCK:
opTransferBlock(in);
break;
case REQUEST_SHORT_CIRCUIT_FDS:
opRequestShortCircuitFds(in);
break;
case RELEASE_SHORT_CIRCUIT_FDS:
opReleaseShortCircuitFds(in);
break;
case REQUEST_SHORT_CIRCUIT_SHM:
opRequestShortCircuitShm(in);
break;
default:
throw new IOException("Unknown op " + op + " in data stream");
}
}
|
写入的Header它的Op是WRITE_BLOCK,通过writeBlock方法进行处理。当建立Pipeline的时候stage处于BlockConstruncionStage.PIPELINE_SETUP_CREATE阶段,这时候DataNode会将请求的数据发送到下一个节点,并等待ACK信息返回给Client,代码为:
// read connect ack (only for clients, not for replication req)
if (isClient) {
BlockOpResponseProto connectAck =
BlockOpResponseProto.parseFrom(PBHelper.vintPrefixed(mirrorIn));
mirrorInStatus = connectAck.getStatus();
firstBadLink = connectAck.getFirstBadLink();
if (LOG.isDebugEnabled() || mirrorInStatus != SUCCESS) {
LOG.info("Datanode " + targets.length +
" got response for connect ack " +
" from downstream datanode with firstbadlink as " +
firstBadLink);
}
}
|
至此,Pipeline建立完成,这个阶段并不涉及数据的传输,只是尝试建立起Pipeline并进行异常处理等。
5、数据传输阶段
用户得到的OutputStream首先写入到本地的Buffer,写完一个Packet后就发送给Primary DataNode,这个时候stage处于BlockConstruncionStage.DATA_STREAMING,代码为:
// get packet to be sent.
if (dataQueue.isEmpty()) {
one = new Packet(); // heartbeat packet
} else {
one = dataQueue.getFirst(); // regular data packet
}
|
在DataNode部分,通过BlockReceiver来接收数据,代码为:
// receive the block and mirror to the next target
if (blockReceiver != null) {
String mirrorAddr = (mirrorSock == null) ? null : mirrorNode;
blockReceiver.receiveBlock(mirrorOut, mirrorIn, replyOut,
mirrorAddr, null, targets);
// send close-ack for transfer-RBW/Finalized
if (isTransfer) {
if (LOG.isTraceEnabled()) {
LOG.trace("TRANSFER: send close-ack");
}
writeResponse(SUCCESS, null, replyOut);
}
}
|
DataNode首先在将数据接收到Buffer中,主要代码可以看BlockReceiver的receivePacket方法,首先mirror到下一个节点:
//First write the packet to the mirror:
if (mirrorOut != null && !mirrorError) {
try {
packetReceiver.mirrorPacketTo(mirrorOut);
mirrorOut.flush();
} catch (IOException e) {
handleMirrorOutError(e);
}
}
|
然后写入到本地:
// Write data to disk.
out.write(dataBuf.array(), startByteToDisk, numBytesToDisk);
|
写入到本地的时候首先在tmp目录下建立两个文件,一个是数据文件,一个是校验文件(后缀为meta),写入的时候首先写入数据文件,随后update checksum,写入到校验文件。
6、写完后的处理
如果一个Block写完后,DFSClient就会关闭这个Pipeline,代码为:
private void endBlock() {
if(DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("Closing old block " + block);
}
this.setName("DataStreamer for file " + src);
closeResponder();
closeStream();
setPipeline(null, null);
stage = BlockConstructionStage.PIPELINE_SETUP_CREATE;
}
|
然后重复第四步,如果都写完了,DataNode会向NameNode汇报接收Block,DFSClient会向NameNode汇报complete,如果Block数没有到达最低副本数,complete需要等待一定时间再去汇报,至此pipeline完成。
原文地址 http://dj1211.com/?p=178