深度学习Faster-RCNN网络
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习Faster-RCNN网络相关的知识,希望对你有一定的参考价值。
目录
1 网络工作流程
在R-CNN和Fast RCNN的基础上,在2016年提出了Faster RCNN网络模型,在结构上,Faster RCNN已经将候选区域的生成,特征提取,目标分类及目标框的回归都整合在了一个网络中,综合性能有较大提高,在检测速度方面尤为明显。接下来我们给大家详细介绍fasterRCNN网络模型。网络基本结构如下图所示:
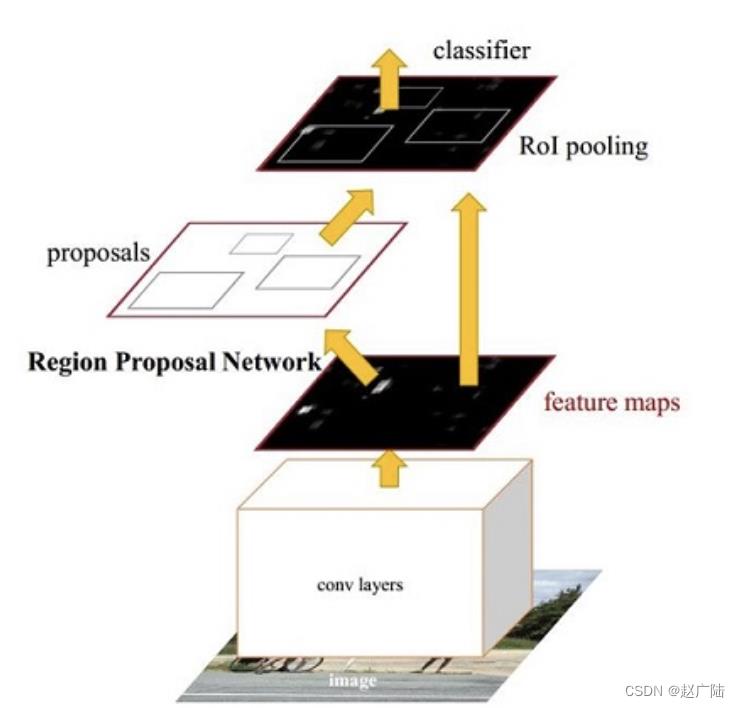
Faster RCNN可以看成是区域生成网络(RPN)与Fast RCNN的组合,其中区域生成网络(RPN)替代选择性搜索来生成候选区域,Fast RCNN用来进行目标检测。

FasterRCNN的工作流程是:
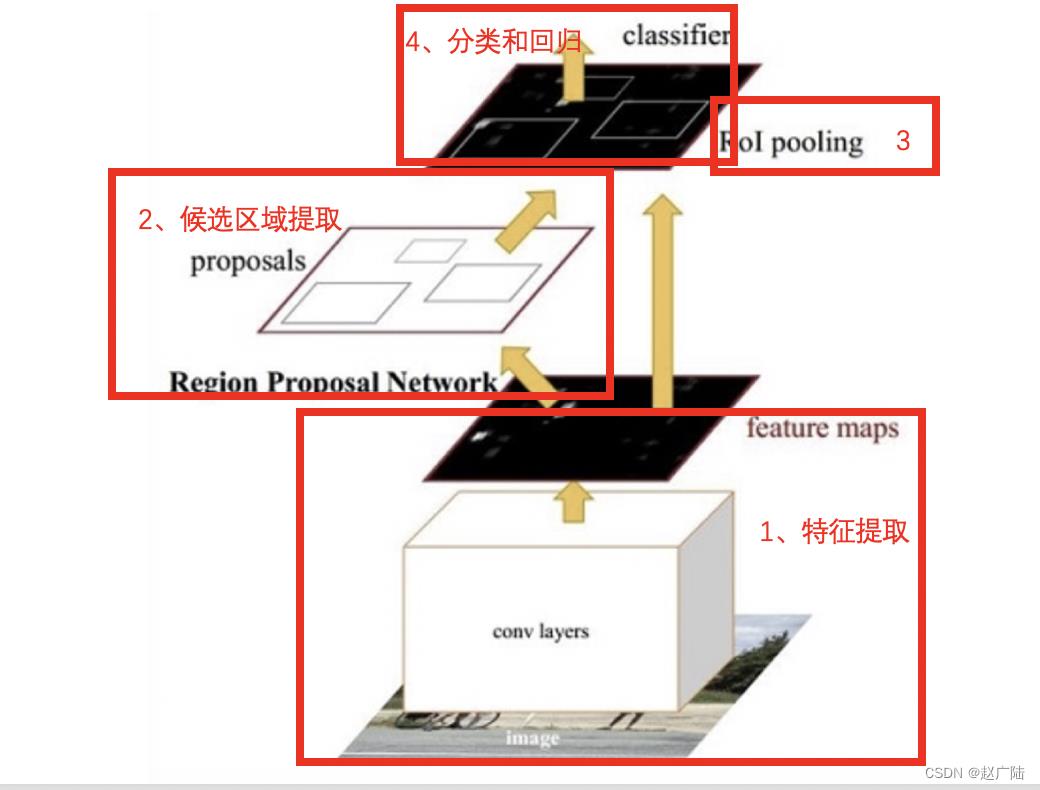
1、特征提取:将整个图像缩放至固定的大小输入到CNN网络中进行特征提取,得到特征图。
2、候选区域提取:输入特征图,使用区域生成网络RPN,产生一些列的候选区域
3、ROIPooling: 与Fast RCNN网络中一样,使用最大池化固定候选区域的尺寸,送入后续网络中进行处理
4、目标分类和回归:与Fast RCNN网络中一样,使用两个同级层:K+1个类别的SoftMax分类层和边框的回归层,来完成目标的分类和回归。
Faster R-CNN的流程与Fast R-CNN的区别不是很大,重要的改进是使用RPN网络来替代选择性搜索获取候选区域,所以我们可以将Faster R-CNN网络看做RPN和Fast R-CNN网络的结合。
接下来我们来看下该网络预训练模型的使用过程,模型源码位置:fasterRCNN中,如下图所示:
detection文件夹中是模型,数据的实现,weights中包含网络的预训练模型。接下来我们按照以下步骤进行目标检测:
1、获取数据和加载预训练网络
2、获取RPN网络生成的候选区域
3、获取网络的目标检测结果
首先导入相应的工具包:
# 获取VOC数据使用
from detection.datasets import pascal_voc
# 绘图
import matplotlib.pyplot as plt
import numpy as np
# 模型构建
from detection.models.detectors import faster_rcnn
import tensorflow as tf
# 图像展示
import visualize
12345678910
遇到的问题1:ModuleNotFoundError: No module named ‘cv2’
解决方法:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python
遇到问题2:ModuleNotFoundError: No module named ‘skimage’
解决办法:pip install scikit-image
另外每次pip install 都会特别慢,我找到一些办法可以参考:
https://blog.csdn.net/yang5915/article/details/83175804
https://waple.blog.csdn.net/article/details/104574277
确实下载快了许多!!!
1.1 数据加载
加载voc数据集中的一张图片进行网络预测:
# 实例化voc数据集的类,获取送入网络中的一张图片
pascal = pascal_voc.pascal_voc("train")
# image:送入网络中的数据,imagemeta:图像的yuan'x
image,imagemeta,bbox,label = pascal[218]
1234
在将图像送入网络之前,我们对其进行了尺度的调整,标准化等处理,获取可展示的图像:
# 图像的均值和标准差
img_mean = (122.7717, 115.9465, 102.9801)
img_std = (1., 1., 1.)
# RGB图像
rgd_image= np.round(image+img_mean).astype(np.uint8)
获取原始图像,进行比较:
# 获取原始图像
from detection.datasets.utils import get_original_image
ori_img = get_original_image(image[0],imagemeta[0],img_mean)
将图像进行对比显示:
# 展示原图像和送入网络中图像
rgd_image= np.round(image+img_mean).astype(np.uint8)
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,8),dpi=100)
axes[0].imshow(ori_img.astype('uint8'))
axes[0].set_title("原图像")
axes[1].imshow(rgd_image[0])
axes[1].set_title("送入网络中的图像")
plt.show()
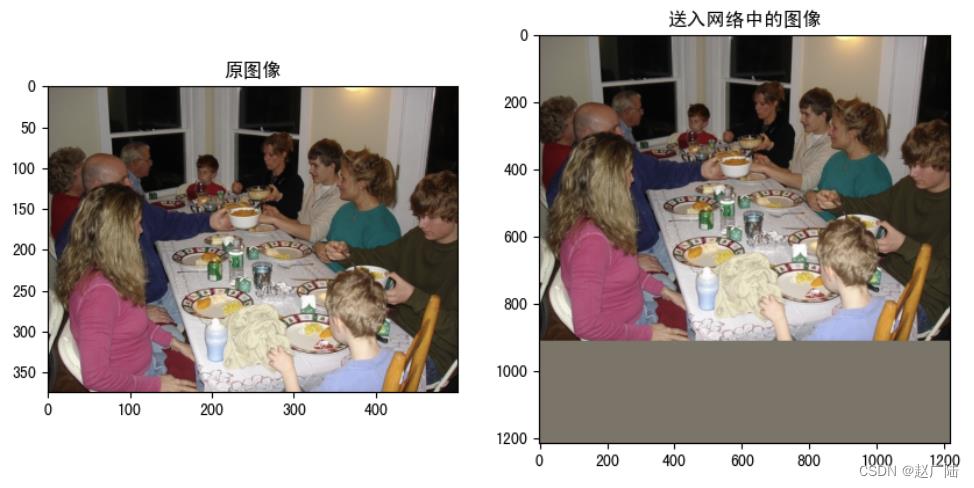
将原图像的长边缩放为1216,短边按相应比例进行调整后,并按照均值进行填充
# 原图像的大小
ori_img.shape
(375, 500, 3)
# 送入网络中图像的大小
image.shape
(1, 1216, 1216, 3)
imagemeta中的信息是:原图像大小,图像缩放后的大小,送入网络中图像的大小,图像缩放比例,图像是否翻转(未使用)。
# 原始图像和送入网络中图像的信息imagemeta
array([[ 375. , 500. , 3. , 912. , 1216. , 3. , 1216. , 1216. , 3. , 2.432, 0. ]], dtype=float32)
1.2 模型加载
加载使用coco数据集预训练的模型,对图像进行预测。
# coco数据集的class,共80个类别:人,自行车,火车,。。。
classes = ['bg', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
实例化faster-RCNN模型:
# 实例化模型
model = faster_rcnn.FasterRCNN(num_classes=len(classes))
加载预训练模型,由于fasterRCNN不是按照model的子类构建,所以无法通过h5文件直接加载模型结构,我们将结构实例化后,在加载权重获取整个预训练模型。
model((image,imagemeta,bbox,label),training=True)
# 加载训练好的weights
model.load_weights("weights/faster_rcnn.h5")
通过model.summary()查看网络架构,如下:

1.3 模型预测过程
模型的预测分为两部分:RPN生成候选区域和Fast RCNN进行目标的分类与回归
1.3.1 RPN获取候选区域
# RPN获取候选区域:输入图像和对应的元信息,输出是候选的位置信息proposals = model.simple_test_rpn(image[0],imagemeta[0])
候选区域的结果如下所示:对于上述图像共产生1533个候选区域,每个候选区域使用相对于输入网络中图像归一化后的左上角坐标和右下角坐标。
<tf.Tensor: shape=(1533, 4), dtype=float32, numpy=array([[0.20729761, 0.00852748, 0.748096 , 0.46975034], [0.42213044, 0.5887971 , 0.7810232 , 0.9806169 ], [0.40125194, 0.4384725 , 0.48458642, 0.47913405], ..., [0.25977597, 0.435113 , 0.27290097, 0.4483906 ], [0.38884488, 0.41798416, 0.41393432, 0.4339822 ], [0.5885266 , 0.65331775, 0.62330776, 0.6913476 ]], dtype=float32)>
我们将这些候选区域绘制在图像上,需要获取绝对位置:
# 绘制在图像上(将proposal绘制在图像上)visualize.draw_boxes(rgd_image[0],boxes=proposals[:,:4]*1216)plt.show()
如下图所示:

1.3.2 FastRCNN进行目标检测
我们将获取的候选区域送入到Fast RCNN网络中进行检测:
# rcnn进行预测,得到的是原图像的检测结果:
# 输入:要检测的送入网络中的图像,图像的元信息,RPN产生的候选区域
# 输出:目标检测结果:检测框(相对于原图像),类别,置信度
res = model.simple_test_bboxes(image[0],imagemeta[0],proposals)
res是一个字典,其结果如下所示:rois是目标框,class_ids是所属的类别,scores是置信度。
'rois': array([[ 95.65208 , 8.963474 , 370.8639 , 224.11072 ],
[ 57.620296 , 226.60101 , 159.39307 , 310.5221 ],
[ 86.15405 , 323.98065 , 369.12762 , 497.70337 ],
[ 83.67178 , 170.96815 , 135.69716 , 221.05861 ],
[ 74.37474 , 327.855 , 210.86298 , 422.48798 ],
[ 73.24604 , 0.97371644, 206.86272 , 47.992523 ],
[ 63.968616 , 256.5716 , 192.52466 , 365.3871 ],
[ 67.055145 , 88.534515 , 137.3221 , 130.74608 ],
[227.8164 , 291.93015 , 370.9528 , 434.4086 ],
[147.73048 , 218.15501 , 177.35306 , 260.56738 ],
[ 82.44483 , 40.140255 , 133.15623 , 107.72627 ],
[122.62652 , 239.552 , 141.19394 , 272.06354 ],
[154.03288 , 115.91441 , 372.5167 , 426.57187 ],
[218.90562 , 364.88345 , 247.20554 , 419.03842 ],
[248.15126 , 407.61325 , 373.63068 , 479.57568 ],
[139.69551 , 248.66753 , 154.51906 , 264.16055 ],
[212.88734 , 195.23204 , 238.25243 , 209.22202 ]],
dtype=float32),
'class_ids': array([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 46, 1, 46, 61, 46, 57, 45, 40],
dtype=int32),
'scores': array([0.99917287, 0.992269 , 0.99193186, 0.98929125, 0.986894 ,
0.98671734, 0.98594207, 0.97716457, 0.97271395, 0.97136974,
0.9637522 , 0.9585419 , 0.9218482 , 0.8920589 , 0.85597926,
0.81343234, 0.78660023], dtype=float32)
将检测结果展示在图像上:
# 将检测结果绘制在图像上visualize.display_instances(ori_img,res['rois'],res['class_ids'],classes,res['scores'])plt.show()

上述我们介绍了Faster RCNN的工作流程并且给大家展示了网络的检测结果。那接下来我们解决以下几个问题:
1、网络中的每一部分是怎么构建,怎么完成相应的功能的?
2、怎么训练fastrcnn网络去完成我们自己的任务?
那接下来我们就解决上述问题。
2 模型结构详解
Faster RCNN的网络结构如下图所示:
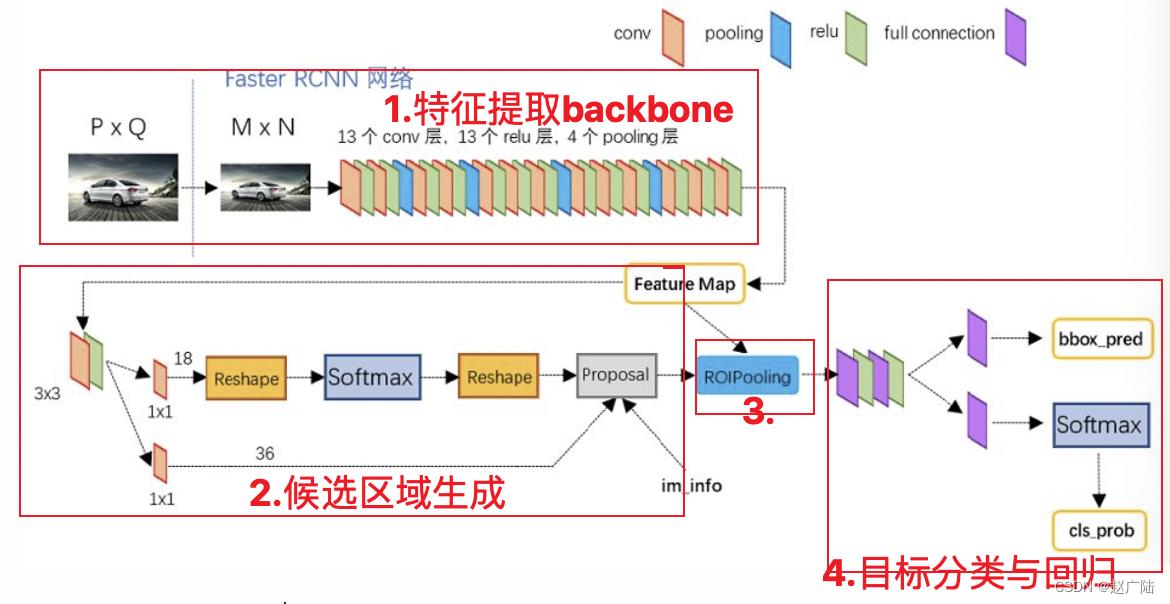
我们依然将网络分为四部分:
- Backbone:Backbone由CNN卷积神经网络构成,常用的是VGG和resnet, 用来提取图像中的特征,获取图像的特征图。该特征图被共享用于后续RPN层生成候选区域和ROIPooling层中。
- RPN网络:RPN网络用于生成候选区域,用于后续的目标检测。
- Roi Pooling: 该部分收集图像的特征图和RPN网络提取的候选区域位置,综合信息后获取固定尺寸的特征,送入后续全连接层判定目标类别和确定目标位置。
- 目标分类与回归: 该部分利用ROIpooling输出特征向量计算候选区域的类别,并通过回归获得检测框最终的精确位置。
接下来我们就从这四个方面来详细分析fasterRCNN网络的构成,并结合源码理解每一部分实现的功能。
2.1 backbone
backbone一般为VGG,ResNet等网络构成,主要进行特征提取,将最后的全连接层舍弃,得到特征图送入后续网络中进行处理。
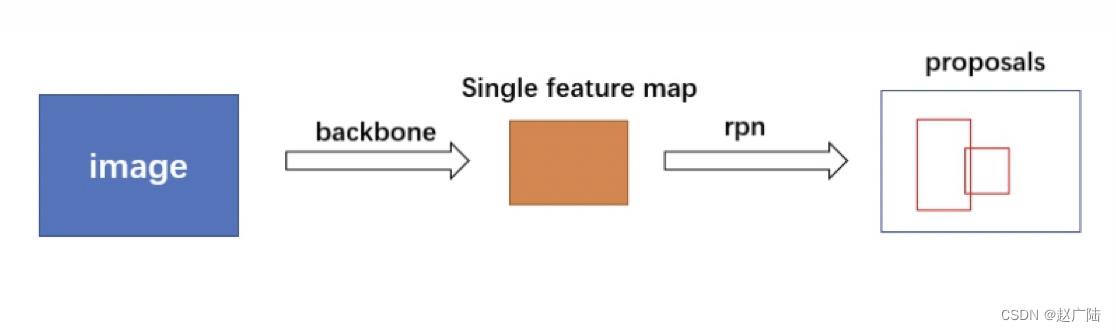
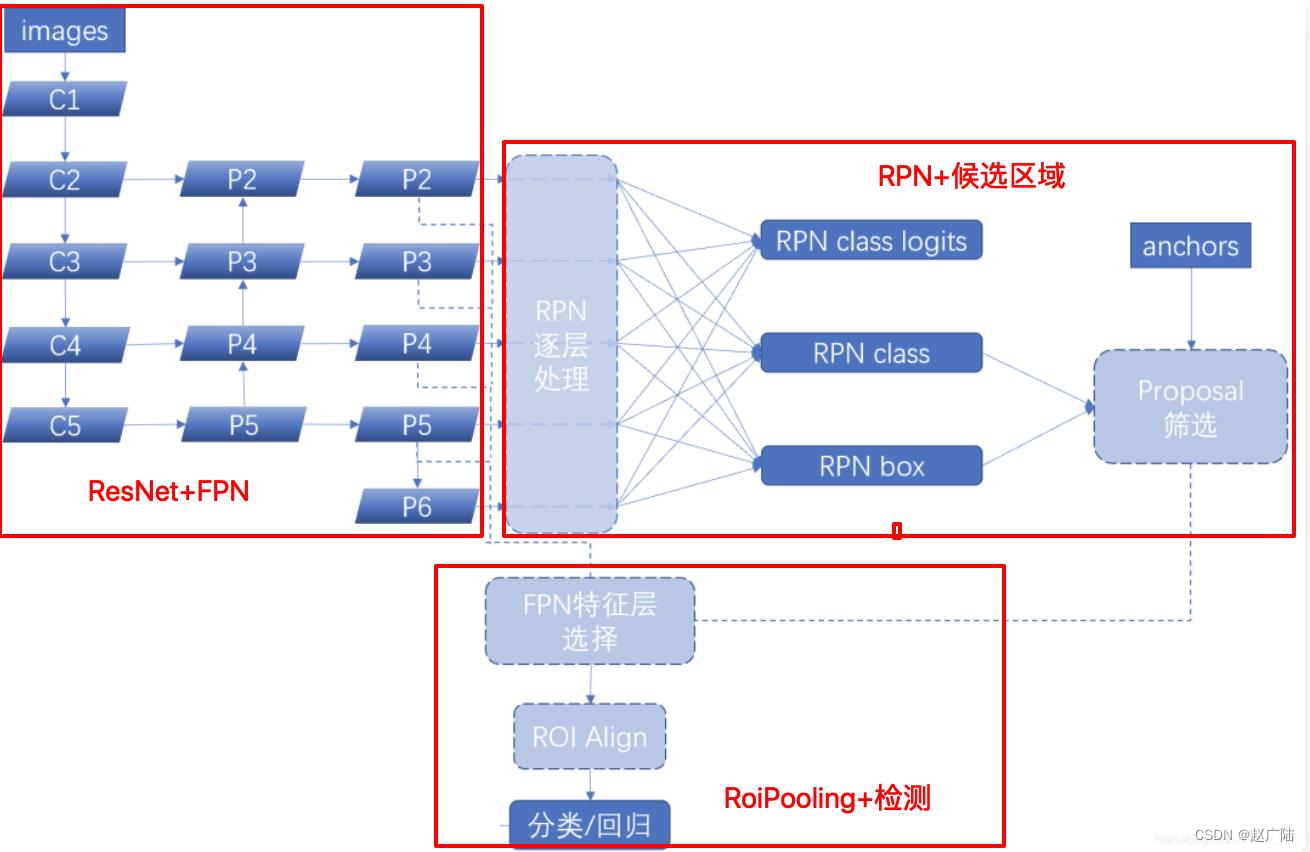
在源码中使用ResNet + FPN 结构来提取特征。与普通的 FasterRCNN 只需要将一个特征图输入到后续网络中不同,由于加入 FPN结构,需要将多个特征图逐个送入到后续网络中,如下图所示:

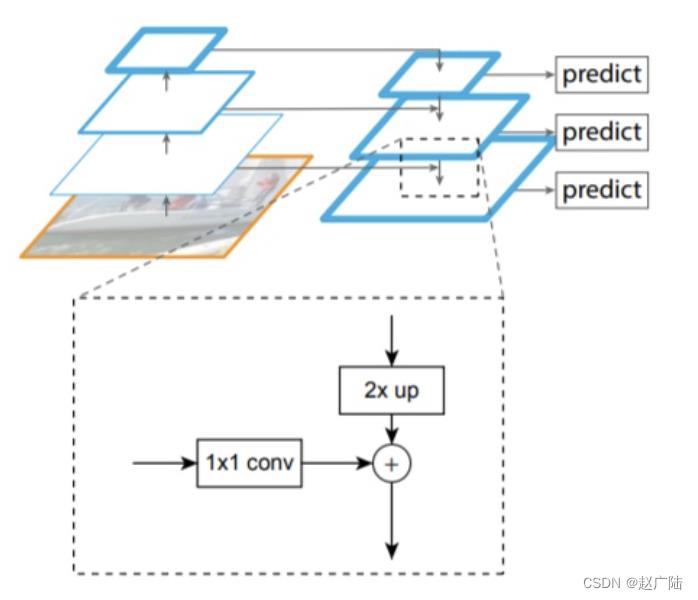
Resnet进行特征提取,FPN结构作用是当前层的特征图会融合未来层的特征进行上采样,并加以利用。因为有了这样一个结构,当前的特征图就可以获取未来层的信息,也就将低阶特征与高阶特征就有机融合起来了,提升检测精度。如下图所示:
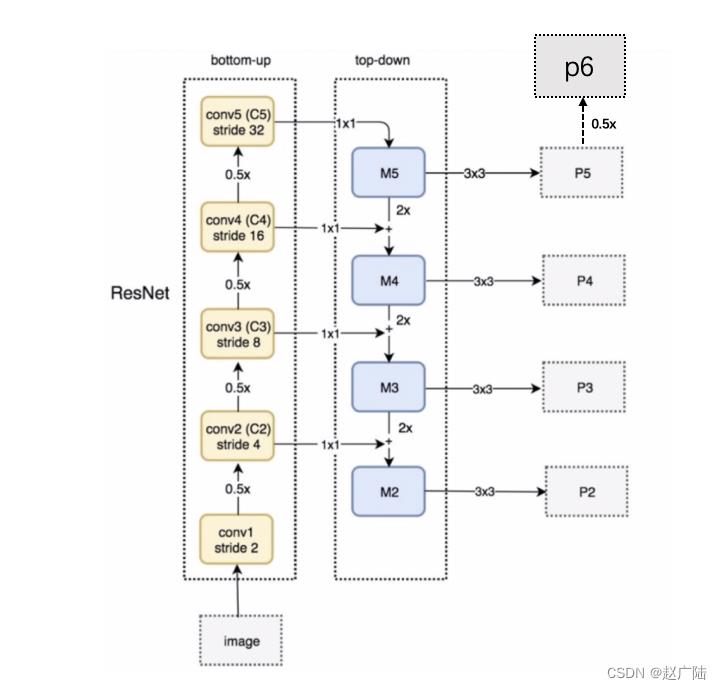
在这里ResNet和FPN的完整结构如下图所示:Resnet进行特征提取,FPN网络进行特征融合获取多个特征图后,输入到RPN网络中的特征图是[p2,p3,p4,p5,p6] ,而作为后续目标检测网络FastRCNN的输入则是 [p2,p3,p4,p5] 。
我们看下源码实现的内容:
1、resnet特征提取的结果
# 使用backbone获取特征图C2,C3,C4,C5 = model.backbone(image,training=False)
C2,C3,C4,C5是resnet进行特征提取的结果,送入网络中图像大小为(1216,1216,3),经过特征提取后特征图的大小为:
# C2.shape:1216/4 TensorShape([1, 304, 304, 256])# C3.shape:1216/8TensorShape([1, 152, 152, 512])# C4.shape:1216/16TensorShape([1, 76, 76, 1024])# C5.shape:1216/32TensorShape([1, 38, 38, 2048])
1
2、FPN特征融合的结果
# FPN网络融合:C2,C3,C4,C5是resnet提取的特征结果P2,P3,P4,P5,P6 = model.neck([C2,C3,C4,C5],training=False)
P2,P3,P4,P5,P6是特征融合之后的结果,送入后续网络中,其特征图的大小:
# P2.shape:1216/4
TensorShape([1, 304, 304, 256])
# P3.shape:1216/8
TensorShape([1, 152, 152, 512])
# P4.shape:1216/16
TensorShape([1, 76, 76, 1024])
# P5.shape:1216/32
TensorShape([1, 38, 38, 2048])
# P6.shape:1216/64
TensorShape([1, 19, 19, 256])
那网络的整体架构表示成:
2.2 RPN网络
经典的检测方法生成检测框都非常耗时,如overfeat中使用滑动窗口生成检测框;或如R-CNN使用选择性搜索方法生成检测框。而Faster RCNN则抛弃了传统的滑动窗口和选择性搜索的方法,直接使用RPN生成候选区域,能极大提升检测速度。

RPN网络的主要流程是:
1、生成一系列的固定参考框anchors,覆盖图像的任意位置,然后送入后续网络中进行分类和回归
2、分类分支:通过softmax分类判断anchor中是否包含目标
3、回归分支:计算目标框对于anchors的偏移量,以获得精确的候选区域
4、最后的Proposal层则负责综合含有目标的anchors和对应bbox回归偏移量获取候选区域,同时剔除太小和超出边界的候选区域。
2.2.1 anchors
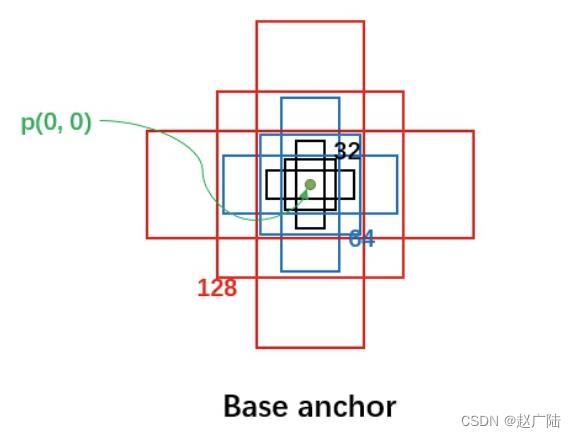
nchor在目标检测中表示 固定的参考框 ,首先预设一组不同尺度不同长宽比的固定参考框,覆盖几乎所有位置, 每个参考框负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标 ,anchor技术将候选区域生成问题转换为 “这个固定参考框中有没有目标,目标框偏离参考框多远” ,不再需要多尺度遍历滑窗,真正实现了又好又快。
在FastRCNN中框出多尺度、多种长宽比的anchors,如下图所示:下图中分别是尺度为32,64,128,长宽比为1:1,1:2,2:1的一组anchors,我们利用这组anchor在特征图上进行滑动,并对应到原图上即可获取一系列的固定参考框。
由于有 FPN 网络,所以会在多个不同尺度特征图中生成anchor,假设某一个特征图大小为hxw,首先会计算这个特征相对于输入图像的下采样倍数 stride:

如下图所示:

每一个尺度特征图上生成不同比列的anchor:

得到一系列的anchors后就可送入后续网络中进行分类和回归。
在源码中我们可生成一幅图像对应的anchors:
# 产生anchor:输入图像元信息即可,输出anchor对应于原图的坐标值anchors,valid_flags = model.rpn_head.generator.generate_pyramid_anchors(imagemeta)
对于1216x1216的图像生成的anchor的数量为:
# anchors.shape:#304*304*3+152*152*3+76*76*3+38*38*3+19*19*3=369303TensorShape([369303, 4])
anchor的取值为:
<tf.Tensor: shape=(369303, 4), dtype=float32, numpy=array([[ -22.627417, -11.313708, 22.627417, 11.313708], [ -16. , -16. , 16. , 16. ], [ -11.313708, -22.627417, 11.313708, 22.627417], ..., [ 789.9613 , 970.98065 , 1514.0387 , 1333.0193 ], [ 896. , 896. , 1408. , 1408. ], [ 970.98065 , 789.9613 , 1333.0193 , 1514.0387 ]], dtype=float32)>
我们将前10000个anchor绘制在图像上:
# 绘制在图像上(将anchor绘制在图像上)visualize.draw_boxes(rgd_image[0],boxes=anchors[:10000,:4])plt.show()

2.2.2 RPN分类
一副MxN大小的矩阵送入Faster RCNN网络后,经过backbone特征提取到RPN网络变为HxW大小的特征图。如下图所示,是RPN进行分类的网络结构:(k=9)

先做一个1x1的卷积,得到[batchsize,H,W,18]的特征图,然后进行变形,将特征图转换为[batchsize,9xH,W,2]的特征图后,送入softmax中进行分类,得到分类结果后,再进行reshape最终得到[batchsize,H,W,18]大小的结果,18表示k=9个anchor是否包含目标的概率值。

2.2.3 RPN回归
RPN回归的结构如下图所示:(k=9)

经过该卷积输出特征图为为[1, H, W,4x9],这里相当于feature maps每个点都有9个anchors,每个anchors又都有4个用于回归的:

变换量。
该变换量预测的是anchor与真实值之间的平移量和尺度因子:

利用源码我们可以获得对anchors的分类和回归结果:
# RPN网络的输入:FPN网络获取的特征图rpn_feature_maps = [P2,P3,P4,P5,P6]# RPN网络预测,返回:logits送入softmax之前的分数,包含目标的概率,对框的修正结果rpn_class_logits,rpn_probs,rpn_deltas = model.rpn_head(rpn_feature_maps,training = False)
结果分析:
# rpn_class_logits.shape,每一个anchor都进行了分类分析TensorShape([1, 369303, 2])# rpn_probs.shape:softmax输出的概率值TensorShape([1, 369303, 2])# rpn_deltas.shape :回归结果TensorShape([1, 369303, 4])
其中 rpn_probs的取值为:
<tf.Tensor: shape=(1, 369303, 2), dtype=float32, numpy=array([[[9.94552910e-01, 5.44707105e-03], [9.97310877e-01, 2.68914248e-03], [9.95540321e-01, 4.45961533e-03], ..., [9.99888301e-01, 1.11637215e-04], [9.99961257e-01, 3.87872169e-05], [9.99820888e-01, 1.79159630e-04]]], dtype=float32)>
我们获取一些分类置信度较高的结果,将这些anchor绘制在图像上:
# 获取分类结果中包含目标的概率值rpn_probs_tmp = rpn_probs[0,:,1]# 获取前100个较高的anchorlimit = 100ix = tf.nn.top_k(rpn_probs_tmp,k=limit).indices[::-1]# 获取对应的anchor绘制图像上,那这些anchor就有很大概率生成候选区域visualize.draw_boxes(rgd_image[0],tf.gather(anchors,ix).numpy())

2.2.4 Proposal层
Proposal层负责综合RPN网络对anchors分类和回归的结果,利用回归的结果对包含目标的anchors进行修正,计算出候选区域,送入后续RoI Pooling层中。
Proposal层处理流程如下:
- 利用RPN网络回归的结果[ d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ] \\left[d_x(A), d_y(A), d_w(A), d_h(A)\\right][dx(A),dy(A),dw(A),dh(A)]对所有的anchors进行修正,得到修正后的检测框
- 根据RPN网络分类的softmax输出的概率值由大到小对检测框进行排序,提取前6000个结果,即提取修正位置后的检测框
- 限定超出图像边界的检测框为图像边界,防止后续roi pooling时候选区域超出图像边界。
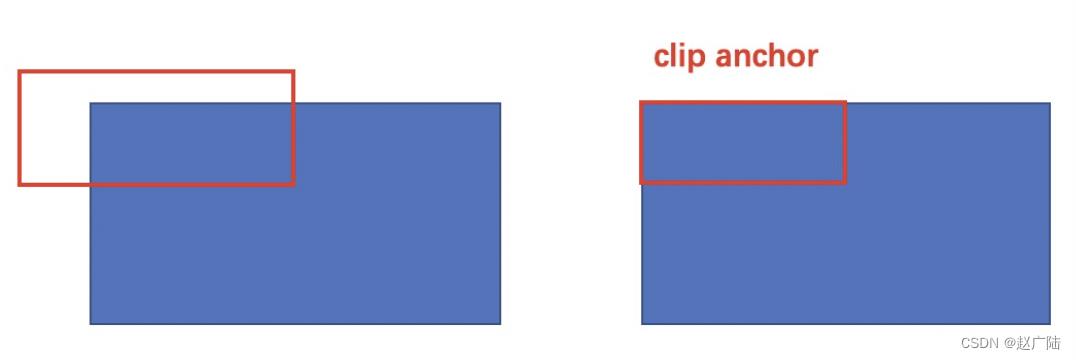
- 对剩余的检测框进行非极大值抑制NMS
- Proposal层的输出是对应输入网络图像尺度的归一化后的坐标值[x1, y1, x2, y2]。
到此RPN网络的工作就结束了。
Proposal层有3个输入:RPN分类和回归结果,以及图像的元信息。
# 获取候以上是关于深度学习Faster-RCNN网络的主要内容,如果未能解决你的问题,请参考以下文章