Shell脚本实现MapReduce统计单词数程序
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Shell脚本实现MapReduce统计单词数程序相关的知识,希望对你有一定的参考价值。
参考技术A options:(1)-input:输入文件路径
(2)-output:输出文件路径
(3)-mapper:用户自己写的mapper程序,可以是可执行文件或者脚本
(4)-reducer:用户自己写的reducer程序,可以是可执行文件或者脚本
(5)-file:打包文件到提交的作业中,可以是mapper或者reducer要用的输入文件,如配置文件,字典等。
(6)-partitioner:用户自定义的partitioner程序
(7)-combiner:用户自定义的combiner程序(必须用java实现)
(8)-D:作业的一些属性(以前用的是-jonconf),具体有:
1)mapred.map.tasks:map task数目
2)mapred.reduce.tasks:reduce task数目
3)stream.map.input.field.separator/stream.map.output.field.separator: map task输入/输出数
据的分隔符,默认均为\t。
4)stream.num.map.output.key.fields:指定map task输出记录中key所占的域数目
5)stream.reduce.input.field.separator/stream.reduce.output.field.separator:reduce task输入/输出数据的分隔符,默认均为\t。
6)stream.num.reduce.output.key.fields:指定reduce task输出记录中key所占的域数目
另外,Hadoop本身还自带一些好用的Mapper和Reducer:
(1) Hadoop聚集功能
Aggregate提供一个特殊的reducer类和一个特殊的combiner类,并且有一系列的“聚合器”(例如“sum”,“max”,“min”等)用于聚合一组value的序列。用户可以使用Aggregate定义一个mapper插件类,这个类用于为mapper输入的每个key/value对产生“可聚合项”。Combiner/reducer利用适当的聚合器聚合这些可聚合项。要使用Aggregate,只需指定“-reducer aggregate”。
(2)字段的选取(类似于Unix中的‘cut’)
Hadoop的工具类org.apache.hadoop.mapred.lib.FieldSelectionMapReduc帮助用户高效处理文本数据,就像unix中的“cut”工具。工具类中的map函数把输入的key/value对看作字段的列表。 用户可以指定字段的分隔符(默认是tab),可以选择字段列表中任意一段(由列表中一个或多个字段组成)作为map输出的key或者value。 同样,工具类中的reduce函数也把输入的key/value对看作字段的列表,用户可以选取任意一段作为reduce输出的key或value。
后来将slaves节点的hostname也修正为IP映射表内对应的名字,解决?
根据一位外国友人的说明,在reduce阶段 ,0-33%阶段是 shuffle 阶段,就是根据键值 来讲本条记录发送到指定的reduce,这个阶段应该是在map还没有完全完成的时候就已经开始了,因为我们会看到map在执行到一个百分比后reduce也启动了,这样做也提高了程序的执行效率。
34%-65%阶段是sort阶段,就是reduce根据收到的键值进行排序。map阶段也会发生排序,map的输出结果是以键值为顺序排序后输出,可以通过只有map阶段处理的输出来验证(以前自己验证过,貌似确有这么回事,大家自己再验证下,免得我误人子弟啊)。
66%-100%阶段是处理阶段,这个阶段才是真正的处理阶段,如果程序卡在这里,估计就是你的reduce程序有问题了。
索性等了一晚上,第二天终于有动静了
和上面的记录对比发现,从%67到%77用了11个小时!这明显是reduce程序效率太慢了。也可能是数据倾斜问题。中间也试过增加reducer的数量,但无果。最终我索性减少了输入文件的行数,使其只有三行:
然后重新运行程序,瞬间得到了结果:
可见,结果是正确的。
令人诧异的是很快就执行完了,难道真的是shell脚本不适合做类似统计这样的事情吗?
MapReduce实现单词统计
开发工具:IDEA
mapreduce实现思路:
Map阶段:
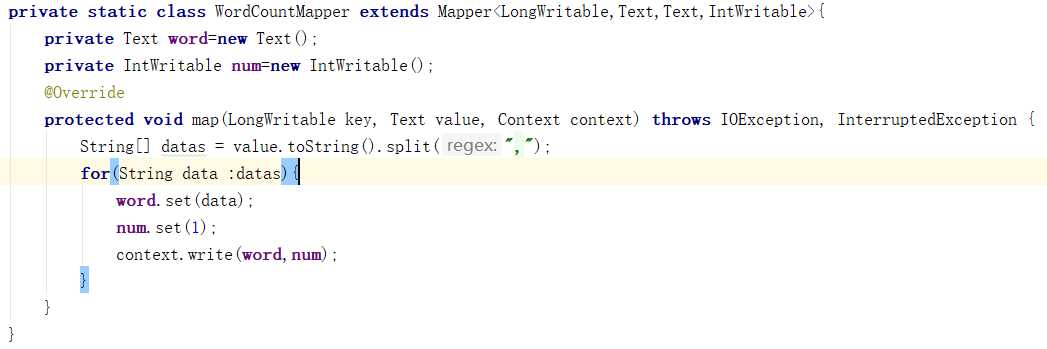
a) 从HDFS的源数据文件中逐行读取数据
b) 将每一行数据切分出单词
c) 为每一个单词构造一个键值对(单词,1)
d) 将键值对发送给reduce
Reduce阶段:
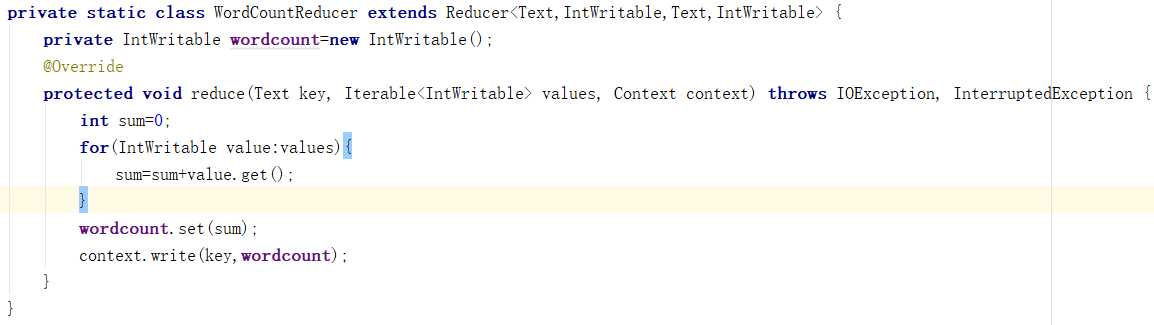
a) 接收map阶段输出的单词键值对
b) 将相同单词的键值对汇聚成一组
c) 对每一组,遍历组中的所有“值”,累加求和,即得到每一个单词的总次数
d) 将(单词,总次数)输出到HDFS的文件中
代码实现:
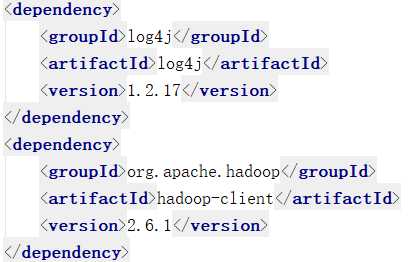
porm.xml导入依赖:
导入包:

Map端:
Reduce端:
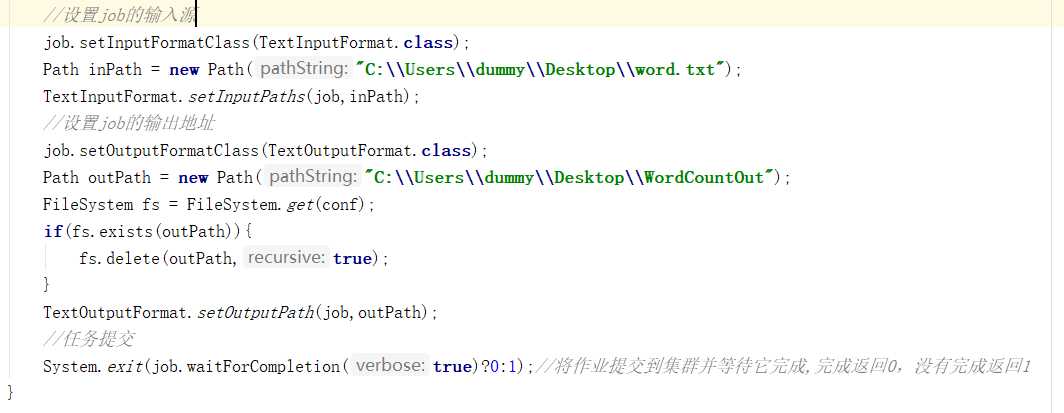
主函数:

以上是关于Shell脚本实现MapReduce统计单词数程序的主要内容,如果未能解决你的问题,请参考以下文章