无码爬虫,真香
Posted 微笑很纯洁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无码爬虫,真香相关的知识,希望对你有一定的参考价值。

将开源小分队设为星标 精品文章第一时间读
大家好,我是爱撸码的开源大叔。
之前和大家分享过java爬虫框架 Jsoup,可还是要敲代码才能爬取东西,运营产品还是没法直接用,时不时来找大叔我爬些数据做分析,烦得很。
于是乎去 GitHub 找了找有没有不用写代码的爬虫工具,结果还真有 SpiderFlow 无需敲代码,即可爬数据。部署好就丢给运营产品,让他们自己玩了。
简介
SpiderFlow 是一个爬虫平台,以图形化方式定义爬虫流程,无需代码即可实现一个爬虫
特性
支持 CSS 选择器、正则提取
支持 JSON/XML 格式
支持 Xpath/JsonPath 提取
支持多数据源、SQL select/insert/update/delete
支持爬取 JS 动态渲染的页面
支持代理
支持二进制格式
支持保存/读取文件(csv、xls、jpg等)
常用字符串、日期、文件、加解密、随机等函数
支持流程嵌套
支持插件扩展(自定义执行器,自定义函数、自定义 Controller 、类型扩展等)
支持 HTTP 接口
快速部署
基础环境
JDK >= 1.8
mysql >= 5.7
Maven >= 3.0 下载地址:(http://maven.apache.org/download.cgi)搭建本地环境
导入数据库
基础表:spider-flow/db/spiderflow.sql
导入项目到 idea
修改 application.propeties
修改 spider-flow-web 下面的application.propeties
# 数据库配置
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.url=jdbc:mysql://localhost:3306/spiderflow?useSSL=false&useUnicode=true&characterEncoding=UTF8&autoReconnect=true运行项目
运行 SpiderApplication 类,看到以下信息,即启动成功
Tomcat started on port(s): 8088 (http) with context path ''
Started SpiderApplication in 4.22 seconds (JVM running for 4.951)使用
访问
浏览器访问:http://localhost:8088/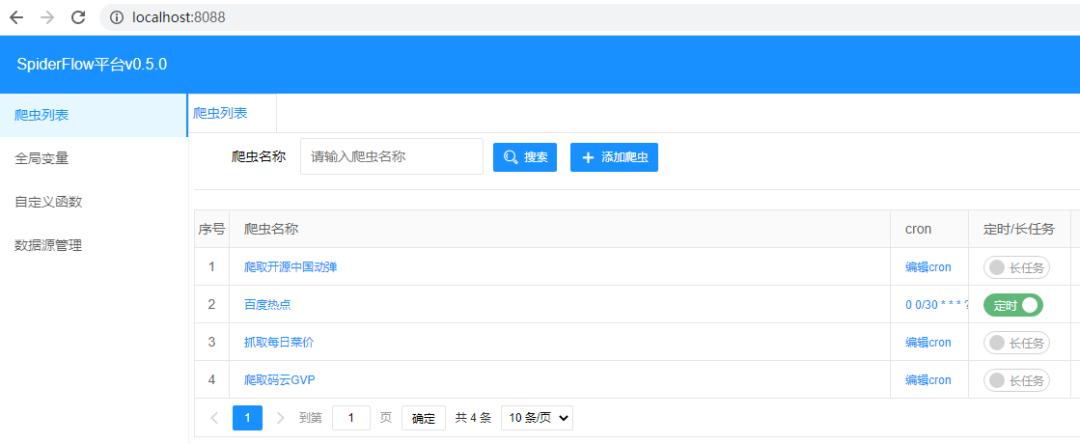
基础组件介绍
开始节点
 仅仅是爬虫的起点,所有流程图必须有该节点。
仅仅是爬虫的起点,所有流程图必须有该节点。
爬取节点
 该节点用于请求 HTTP/HTTPS 页面或接口。
该节点用于请求 HTTP/HTTPS 页面或接口。
定义变量
 该节点用于定义变量之后,可以与表达式配套使用,实现动态设置各项参数(如动态请求分页地址)
该节点用于定义变量之后,可以与表达式配套使用,实现动态设置各项参数(如动态请求分页地址)
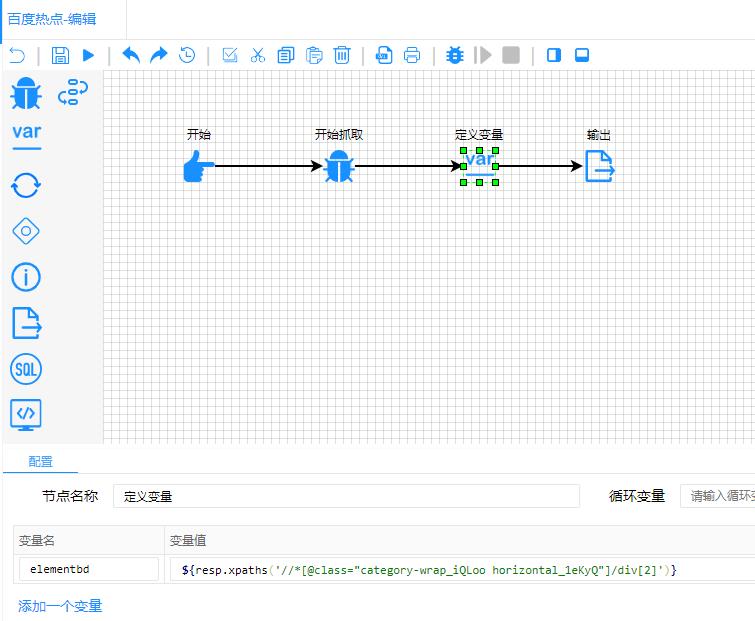
变量名:变量的名字,当变量名重复时,会覆盖前一个变量。
变量值:变量的值,可以是常量,可以是表达式。
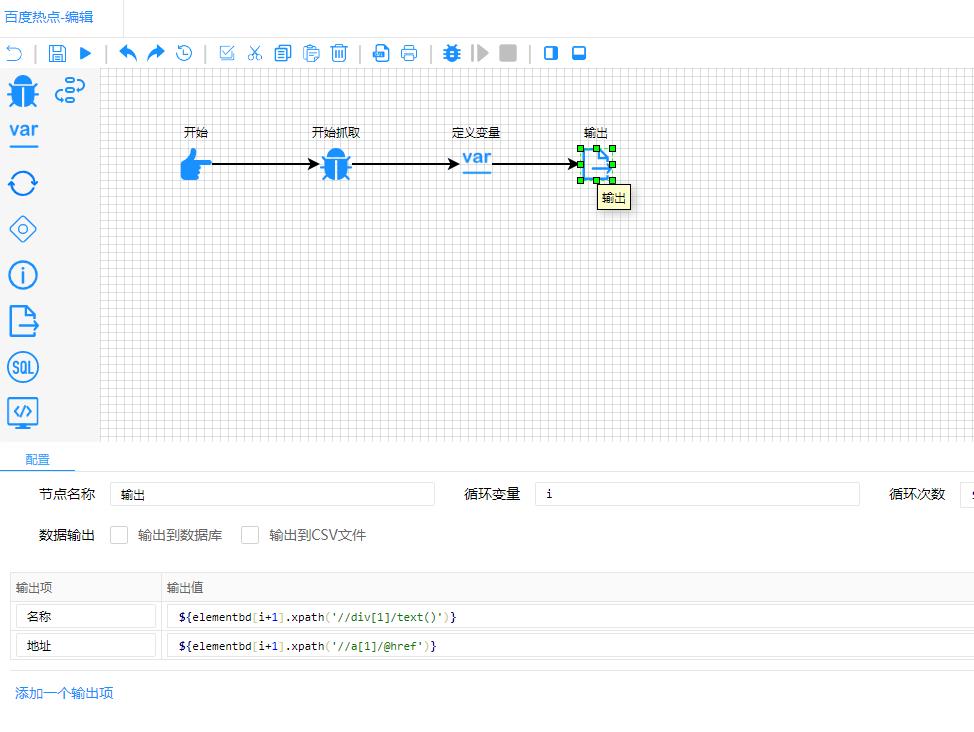
输出节点
 该节点主要用于调试,测试时会把输出打印到页面中,另外也可以用来自动保存到数据库或文件。
该节点主要用于调试,测试时会把输出打印到页面中,另外也可以用来自动保存到数据库或文件。
例子:抓取百度热搜问题
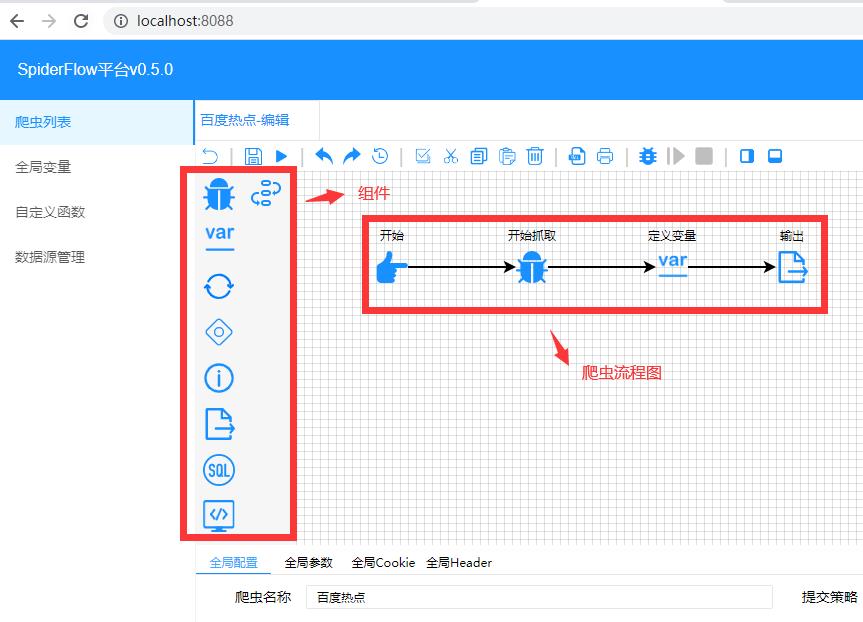 从左边的组件栏中分别拖拽出那三个组件
从左边的组件栏中分别拖拽出那三个组件
设置爬取的节点配置
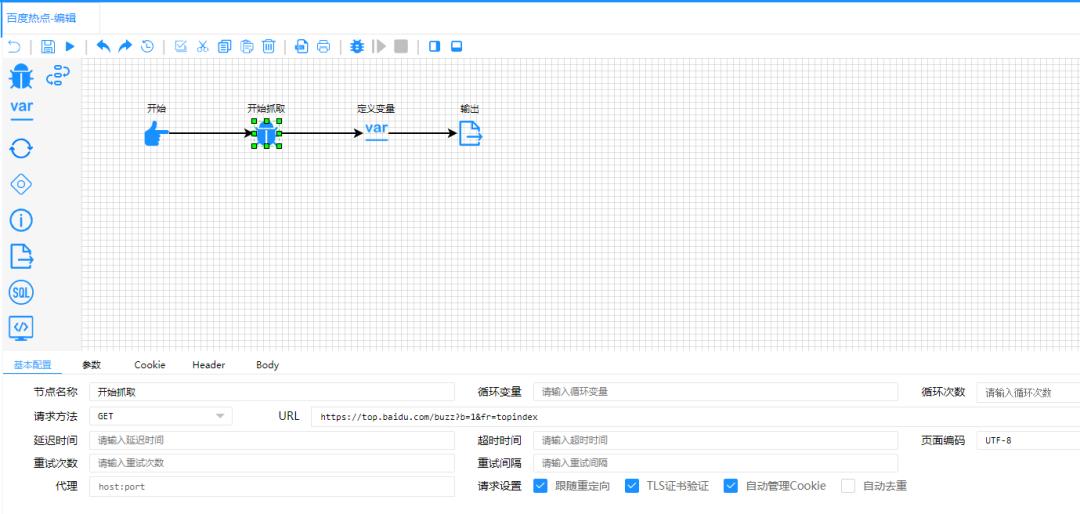
设置变量规则
设置输出
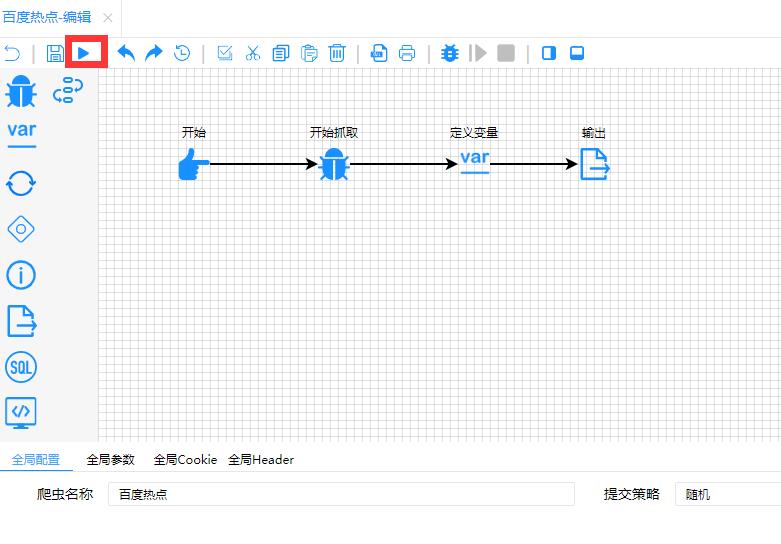
运行爬虫
 得到结果:
得到结果: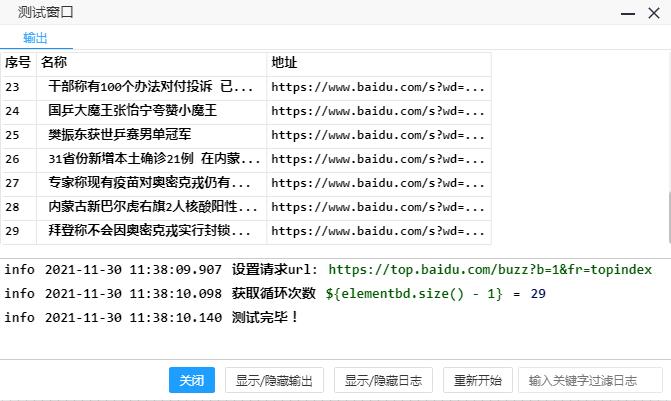
小结
我们直接将爬虫平台部署好后,一句代码也没写就可以直接根据网站情况,创建爬虫爬取数据。就问大家 SpiderFlow 这个项目香不香?文中的例子也是比较简单的,平台还有很多高级功能,大家有兴趣可以继续探索。
好啦,今天大叔的分享就到这里了,在公众号后台回复「无码爬虫」即可获取项目源码地址。看完文章后,趁着搬砖摸鱼之时,赶快试试吧。
问君能有几多愁,开源项目解千愁,我们下期再见!
大家的点赞、收藏和评论对大叔非常重要,如文章对你有帮助还请转发支持下,谢谢!
回复【01】
即可查看往期所有的开源项目
以上是关于无码爬虫,真香的主要内容,如果未能解决你的问题,请参考以下文章