mysql索引优化实战(举例说明)---mysql详解
Posted 如月之恒-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql索引优化实战(举例说明)---mysql详解相关的知识,希望对你有一定的参考价值。
文章目录
案例
用例表结构
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c1` varchar(10) COLLATE utf8mb4_bin DEFAULT NULL,
`c2` varchar(10) COLLATE utf8mb4_bin DEFAULT NULL,
`c3` varchar(10) COLLATE utf8mb4_bin DEFAULT NULL,
`c4` varchar(10) COLLATE utf8mb4_bin DEFAULT NULL,
`c5` varchar(10) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_test_c1234` (`c1`,`c2`,`c3`,`c4`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
分析以下用例的索引使用情况
case 1

case 2
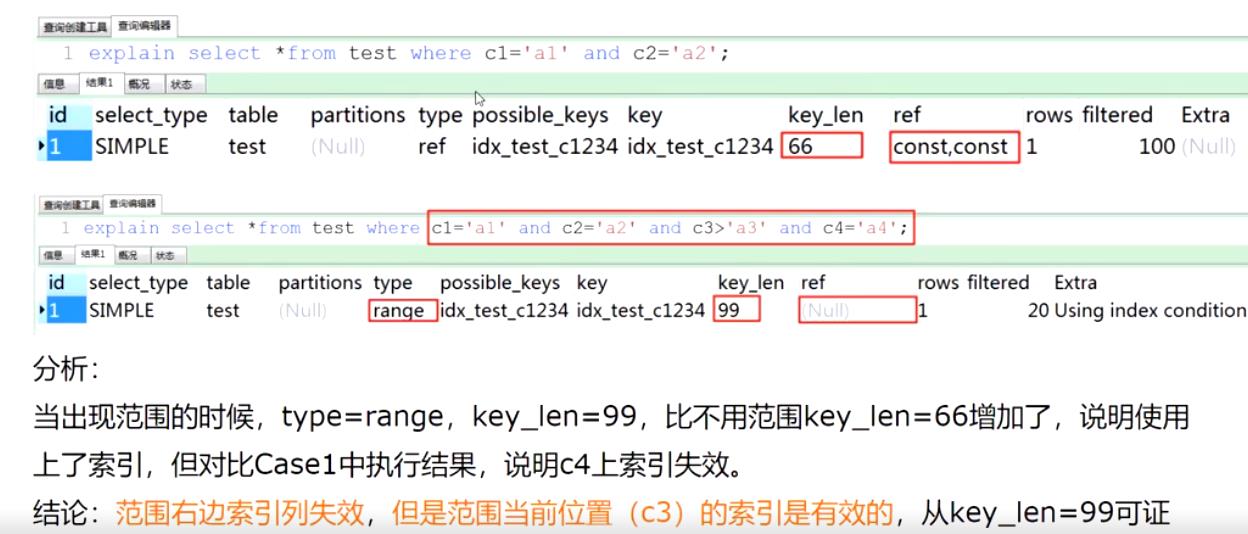
case 2.1

case 2.2
这种情况就很有可能是由于该表数据量少,mysql自己做了优化,mysql认为走全表扫描比索引更快。

case 3
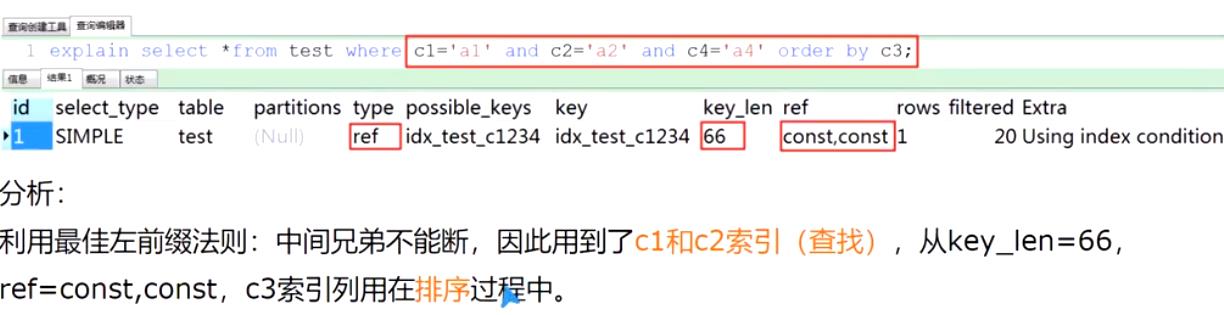
case 3.1
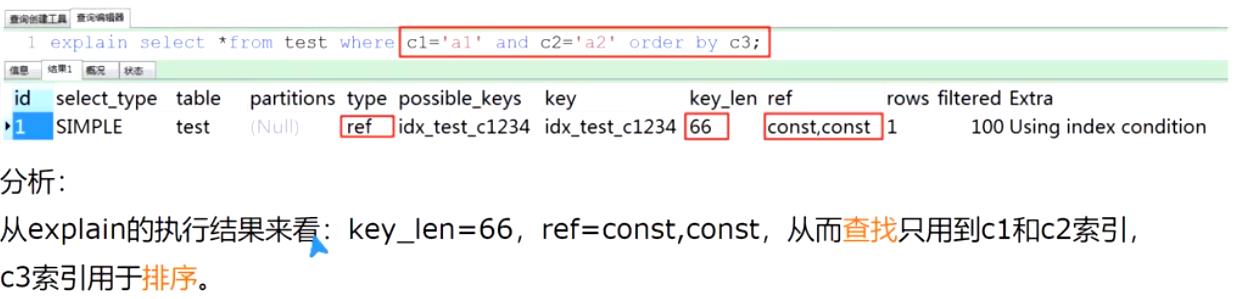
case 3.2

case 4

case 4.1

case 4.2

case 4.3
这条sql实际上C2字段并不需要排序,因为c2=‘a2’,所以order by c3,c2实际上是order by c3

case 5
group by实际上在执行时会先进行order by
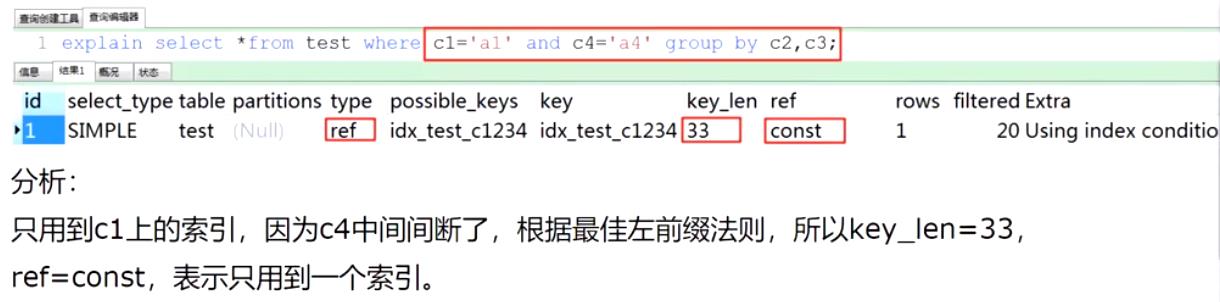
case 5.1

case 6
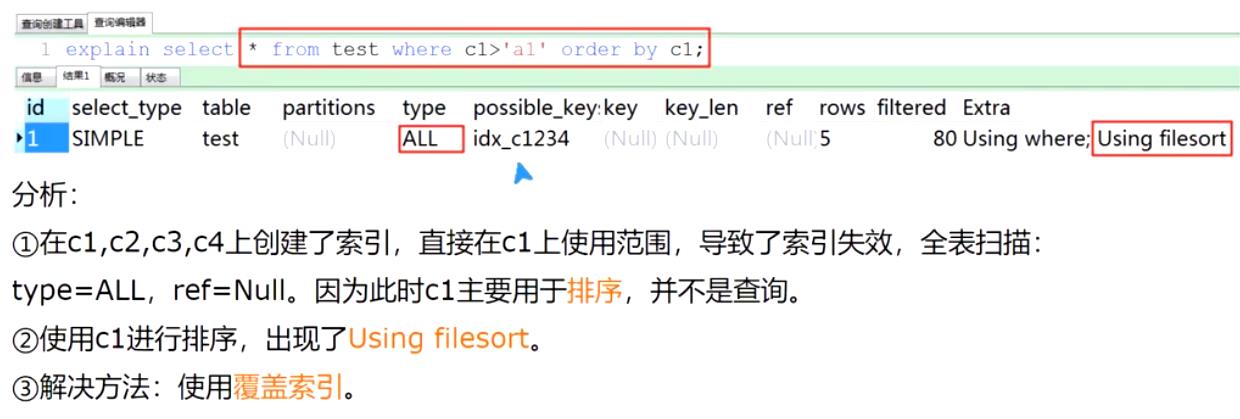
如上图所示,查询条件联合索引的第一个字段尽量用“=”去查询。

case 7
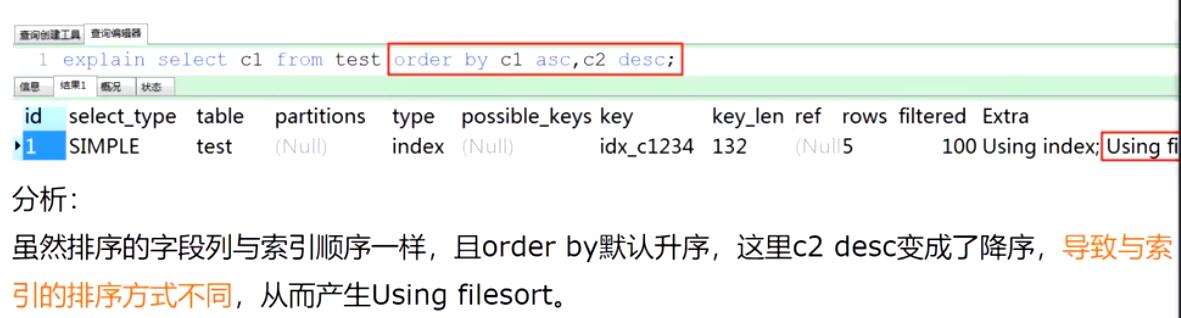
case 8

注
- 文章是个人知识点整理总结,如有错误和不足之处欢迎指正。
- 如有疑问、或希望与笔者探讨技术问题(包括但不限于本章内容),欢迎添加笔者微信(o815441)。请备注“探讨技术问题”。欢迎交流、一起进步。
以上是关于mysql索引优化实战(举例说明)---mysql详解的主要内容,如果未能解决你的问题,请参考以下文章