前沿系列--简述Diffusion Model 扩散模型(无代码版本)
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前沿系列--简述Diffusion Model 扩散模型(无代码版本)相关的知识,希望对你有一定的参考价值。
文章目录
前言
OK,今天的话,我们来搞一下这个扩散模型,来对这个玩意进行一个简单的了解,因为这个也是目前还算比较前沿的东西,也挺有用的,当然我这边和RL一样,我喜欢用来做优化,完成任务,单纯用来做生成se图是在是没什么意思(狗头)当然也是没办法,如果连这个都不去了解的话,咱们在AI领域是没法混了,得多少了解一下。
那么在开始之前的话,我们还是需要去了解一下这个GAN网络。这个的话,我这边是没有写过专门介绍GAN的文章,这个自己去找一下,原理其实还是很好理解的。可能看几个案例就懂了:PSO算法(优化与探索四*DDPG与GAN)
why
老规矩我们来看一下为啥要有这个东西,首先我们应该要知道这个模型,是用来解决一些GAN网络的问题。
首先我们的GAN网络呢有两个玩意,一个是生成器,还有一个是判别器
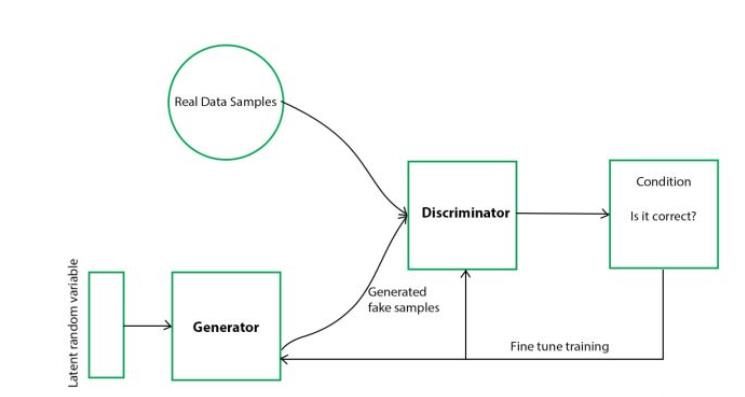
在训练的过程中呢,我们需要训练两个网络,对于生成器,我们期望能够生成一个图像,或者其他的任务能够去骗过判断器,对于判断器,我们希望能够准确识别出生成器生成的图像,和真实的图像的差异,提高鉴别能力。两者之间相互对抗。所这个玩意也叫作对抗模型。
但是问题在于:
- 两个网络之间的收敛问题,两个网络同时训练不太容易收敛
- 在生成的过程中,生成器为了能够骗过判断器,但是骗过生成器的方式不一定是生成器学习到了图像的某种特征,也有可能是在单纯做拟合。因此这就导致在实际当中效果不一定好。举个例子,判断器就是老师,老师会去打分,专家呢就是学霸,然后生成器就是你。你的目的是能够和学霸一样,拿到高分,但是呢,你有可能是真的学到了东西,但是也有可能是直接抄袭了学霸的试卷。那么这个就不好说了。也就是,这玩意不一定稳定。而且从我们数据集的角度来看,模型的迁移能力会比较差,他可能只会生成和训练集类似的图像,假设我们做的任务是文本—》图像。为什么会这样呢,原因很简单,当初为了骗过判断器,生成器生成的图像是尽可能和目标图像类似的,不然骗不过去。
那么如何解决这个问题呢,首先我们还是需要像学霸学习对吧,但是呢我们是期望学习到学霸的一种方法,或者说是具备学霸的能力。但是呢刚刚也说了考试的时候呢,是可能作弊,走捷径的,那么为了避免这个问题,我们其实很容易想到一办法,大部分人应该也被恶心过,那就是每个人的卷子如果不一样那么这个时候呢,你想直接抄是不太可能的了。抄了分数也不一定高,那么此时对应生成器没啥问题了,但是对于那个改卷的老师来说,就难受了。而且我们其实发现,我们并不太关心判断器。
所以为了解决这些问题,这个扩散模型诞生了。
那么友情提示一下,就是接下来的理论部分比较多,此外的关于以前的一些推导笔记啥的,等我记忆回复+平板到手+心情良好在做一个整理。
扩散简述
OK,既然我们想要去了解这个扩散模型,那么我们就必须要知道什么是扩散,首先我们来直接看到一张图哈:
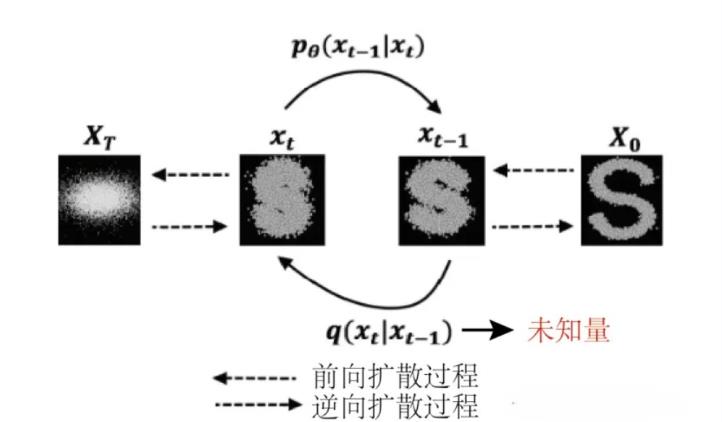
他是从看起来有序到无序的过程,同时我们发现这个玩意好像是一步一步来做的,从前面到后面,从后面到前面。那么问题来了为什么要这样做呢?
这个的话,我们在来回到刚刚考试的例子,我们原来的GAN是这样的:我们把一张张图像或者一个一个班batch看做是一次次考试,并且你和学霸考同一张试卷,我们的期望是你和学霸在一次次开始中的分数能够不断接近。但是呢,你这个平时比较机灵,喜欢偷袭不讲武德。所以的话这个考试呢可能就不准确,你也不一定学到了东西,那么未来解决这个问题,我们刚刚提到说,把你们的题目打乱。或者题目不一样,但是都在一个考纲里面。这样就可以更好地检验你的学习效果,同时迫使你真的往学霸好的方向学习。
那么把这个例子给衍生到图像领域,例如生成之类的,那么我们刚刚的操作呢其实就相当于上面的那张图。我们给图像加一点噪音,但是呢,我们噪音需要满足一个分布,比如正太分布,一般也是这个分布,也就是限制在一个考试大纲里面。那么此时我们加入图像噪音是有规律的,那么自然我们也是可以复原的。
这个时候呢,我再思考一个问题,回到刚刚就是我们考试的例子。同时对比到GAN网络,我们是说我们需要向学霸学习,同时通过考试来检验,这个考试的评分阅卷是由老师来的,但是在GAN网络当中,这个“老师”这个角色一开始其实也是啥也不知道的,就比如,这个改卷子的老师是你同学,那个学霸是标准答案,并且此时我们做的卷子假设是文学类的卷子,没有绝对标准的答案。那么如果我们还打乱了顺序,那么对于那个阅卷的“老师”来说是不是有点强人所难了,想要能够完成这个,那么显然这个改卷的“老师”的水平也要高才对呀。那么这个时候不就死锁了嘛,OK,现在再思考一下,考试的目的是什么,为了检验你的学习成果和学霸的差距是吧(方便构造一个损失函数)那么只有考试才可以检验成果嘛?不一定吧,最牛逼的大佬完全是可以自己给自己出题目然后做出来吧,如果对一个东西掌握的非常熟悉的话,完全是可以自举的。
所以不妨换一个思路,那就是“纠错还原”我给你一个题目和解题答案,我把答案故意写错一点,或者做点手脚(也就是往图像中加点噪音)然后呢,你还能够还原出正确答案,那么是不是说明你已经掌握了一个东西,在GAN里面那个学霸是对那个东西已经掌握了很好,我们向他学习,目的是为了能够像学霸一样解决问题,而不是为了模仿学霸说一句鸡汤就是:我们需要解决问题让我成为像成功人士一样的人,而不是像成功人士一样然后再去解决问题。
说实话就是,其实我们的本质是为了解决问题,GAN是让我们先参考参考专家的做法,有一个参照。而我们的扩散模型,是直接面对问题本身,通过问题来衡量。就像我们解题目一样,你只有当题目充分了解了之后才有可能解出来,在此之前我们练习了大量类似的题目,并且能够自举,那么当遇到新的类似的题目的时候就比较容易解决了。
那么稍微总结一下就是:我们的目的是学习到影藏的特征,通过特征解决问题,在加以干扰的情况下,我们如果还能够去还原的话显然说明可能掌握了一定的特征,并且是面向问题的特征(就是总比抄答案的会强一点,对比GAN的话)
所以这个扩散模型的话,其实还是出发点比较直接,通过这个出发点,我们其实也是可以做到很多不同算法,这个东西类似于一个大纲,思路是很不错的。当然接下来推导的时候也非常难受,噗呲。
那么抽象一点就是:
通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据。
how
OK,接下来就是how了,如何去做了。
如何扩散
OK,接下来解决一下我们如何扩散的问题,我们来做到这个扩散。也就是加点噪音呗。
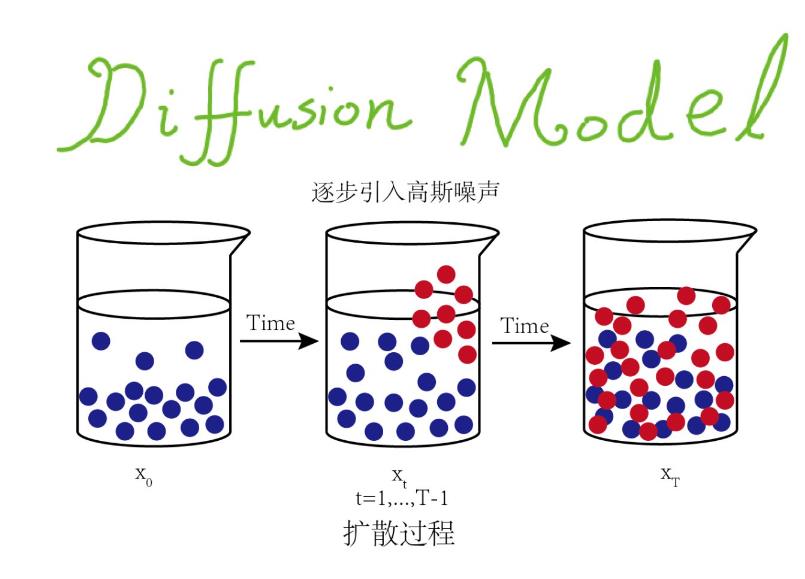
图中这个过程是一个打乱的一个过程,那么我们先来看一下稍微官方一点的定义:

这个的话我们先不关心这个,这里面的话比较抽象。我们还是来直接看到这个怎么来,怎么用,比如我们学习Q-learning的时候,我先直接关系那个累计奖励的更新公式就好了,后面再补。我们只需要知道一件事情,那就是我们所有的假设都是符合正太分布的就好了。
那么我们再看到这张图:
X0是一个初始状态
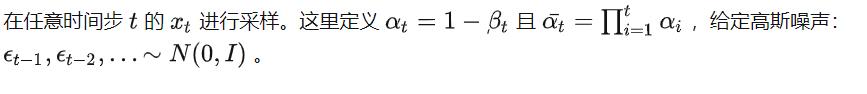
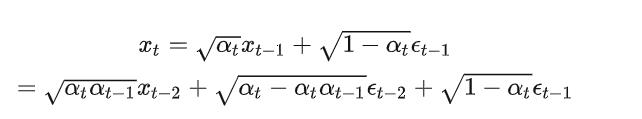
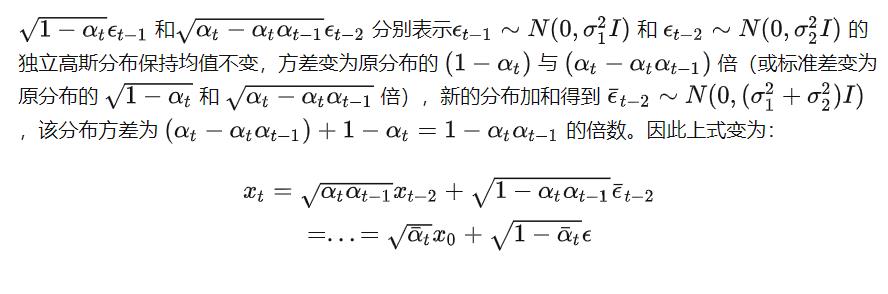

那么在这里的话比较重要的就是有Xt的一个公式。阿尔法和贝塔都是一个相当于超参数的存在。
OK,我们可以先抽象一下,这个公式的意思,就是帮助我们打乱,只不过就是说,这个打乱是按照概率论的方法进行操作,加入高斯噪声,通过这个公式我们可以“打乱”多次。
那么对于我们打乱的话,我们由于参数都是已知的,因此我们可以直接求出来。
但是对于一个反向过程,我们只能一步一步去推,就是外面可以把门推进去,里面不能把门推出去这个意思,因为中间有噪声呗,打乱容易还原难呀。
逆向过程
之后的话是我们的一个逆向过程。现在我们知道了我们现在需要先做出一个扩散,也就是相当于打乱试卷。并且最终我们得到的公式是这样的:
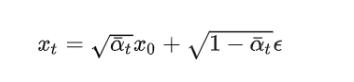
通过这个公式可以帮助我们做到一个打乱,也就是扩散。
我们的目的拿到刚刚考试的例子,就是为了做检验,故意写错答案,让你复原,那么我们的目标就是能够知道你是怎么打乱的,这样才能复原呗。最终我给到你的是我打乱完毕以后的答案,你要的是还原成一开始没有打乱的标准答案。换一句话说就是,我们需要由Xt—>推导出X0
这个推导过程比较复杂,反正就是一步一步去往前还原。
我们先来看到这个公式:
这个公式就是在网上推导一小步的情况
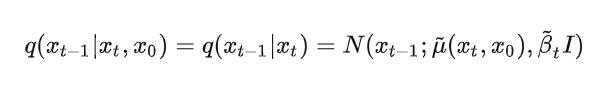
知乎的话,我们这边可以从贝叶斯的角度,去做一个化简推导:
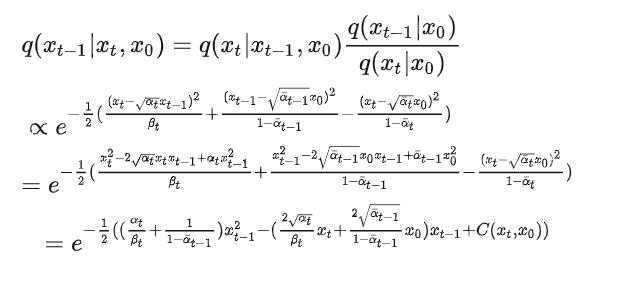
最终我们可以得到的一个公式是这样的:
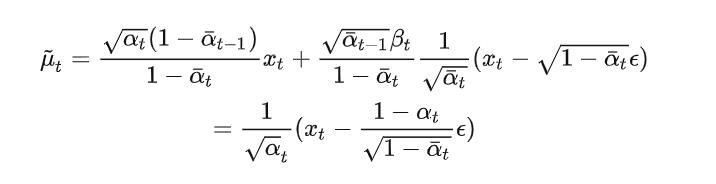
最后那个μ就是我们预测的一个最初的样子。
这里的话参考这篇文章(推理的挺详细)
https://zhuanlan.zhihu.com/p/572263021
小结
这里的话我们需要搞清楚的是,我们有两个过程,一个是扩散过程,就是打乱顺序,还有一个就是还原预测的过程。
其实有一点相识Seq2Seq里面的编码器和解码器的感觉,但是在这里的话,我们发现就是我们的编码器就是相当于打乱的一个过程,这个过程是已知的,包括我们加入一个噪声,这些都是已知的。但是呢,我们的预测过程中,我们一步一步去返回预测,相当于解码器,最终也是得到一个新的序列。
那么问题来了,我们这样做有啥用呀,看到这张图:
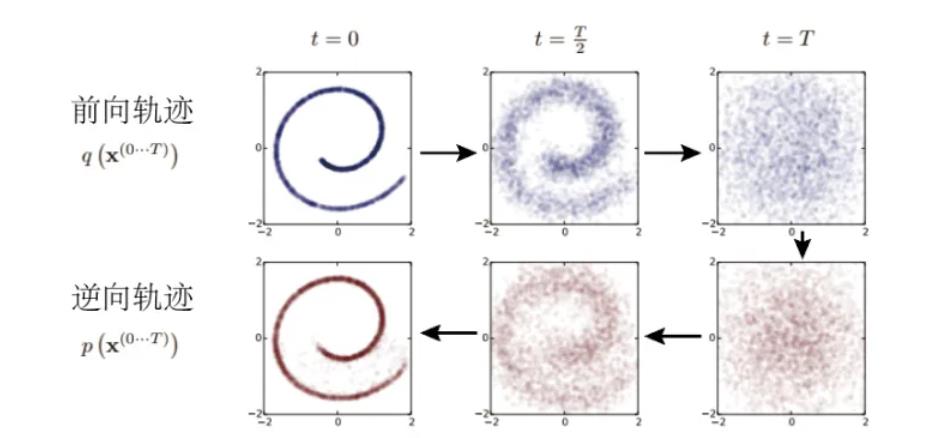
假设我们在做一个图像风格迁移的任务,前向是我们对数据集的处理,我们最后会对图像变成t=T的样子。假设这样操作是我们按照一定的规则由A—》B风格,那么此时我们给到一张新的图像,假设是B风格的,现在要变成A风格,那么我们就可以通过逆向轨迹去得到。
由A–》B 的变化相当于是加了一些噪音,这个是在数据集里面可以得到的。逆向的过程是也是通过“噪音”然后带入到公式得到预测的A风格的图像。
也就是说在逆向的过程中:
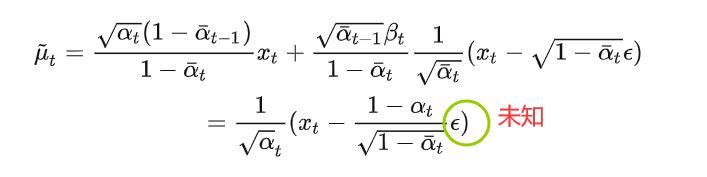
如果我们知道了这个我们是不是就可以处理了。每次搞了半天我们想要知道的就是这个“噪音”怎么来的。
例如我们刚刚的考试的例子,我们故意写错了东西,但是这个东西,都是可以通过你在考纲内学习到的东西来解决还原的,你还原了就是学习到了,就是掌握了相当于“学霸”了,自然就实现了类似于GAN的效果。
感兴趣的话还可以去看看原始论文:
https://arxiv.org/pdf/2006.11239.pdf
流程
OK,我们扯完了一些基本概念之后的话,我们来看一下这玩意大概是怎么训练,怎么玩的。
首先我们可以看到论文当中的一个伪代码

这里的话其实就是差不多直接用到最后推导出来的公式了。
这个伪代码就非常形象了。
训练过程
我们先直接看到训练过程,看到这个怎么理解,我们还是假设在CV领域吧(纯CV)
- 首先的话,我们还是取到一个batch,
- 然后的话按照我们前向的那个扩散的公式,对这个图像进行一个扩散。对每一个图像的扩散的次数还是不太一样的从1到T次随机的
- 加入一个噪声,其实这块还是在扩散中,因为这个时候还是需要这个噪声的
- 这个时候我们说我们目标是学习到这个噪声,也就是做拟合,那么这个时候这里定义了一个损失函数,这个E0就是网络预测的,输入的值就是第t时扩散后的东西呗。
预测过程
之后的话到了咱们的预测过程,这个过程其实更好理解了,就是逆序过程嘛。
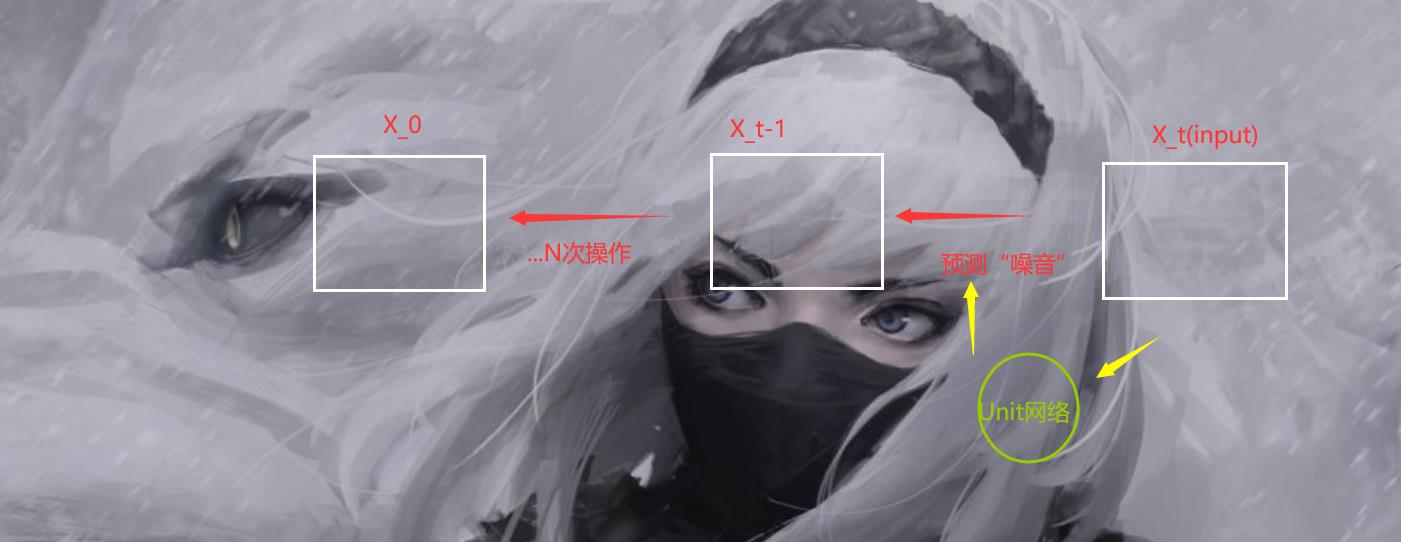
然后这边使用到的是unit结构的一个网络。
总结
OK,那么这个的话,大致上就是扩散模型的一个概述了,主要是那个公式的推导确实是比较复杂的,这块的话也是受限于篇幅,我们不是那么关心这个问题,我们这边既然是简述,那么知道这个大致的一个思想就好了。那么之后的话关于代码复现这一块的话,我们这边还是需要结合到论文来仔细查看查看。受限于时间和设备以及精力的问题,咱们这边就暂时先这样。
以上是关于前沿系列--简述Diffusion Model 扩散模型(无代码版本)的主要内容,如果未能解决你的问题,请参考以下文章