昆仑天工AIGC——基于Stable Diffusion的多语言AI作画大模型测评
Posted 白水baishui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了昆仑天工AIGC——基于Stable Diffusion的多语言AI作画大模型测评相关的知识,希望对你有一定的参考价值。
文章目录
1. AIGC
今年掀起了一股AI 艺术的创作热潮,随着Stable Diffusion的出现,人工智能生成内容模型(Artificial Inteligence Generated Content,AIGC)终于接近了商用化标准,然而目前可用的AIGC模型都需要在英文场景下使用。在这样的背景下,昆仑天工针对AIGC模型在中文领域劣势结合Chinese-CLIP模型推出了全系列的AIGC大模型,AI生成能力覆盖图像、音乐、编程、文本等全模态领域。
2. 技术背景
2.1. Stable Diffusion
Stable Diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。
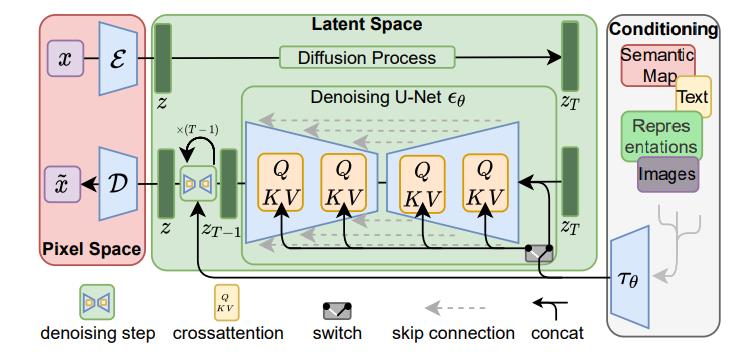
它包含三个模块:感知压缩、扩散模型和条件机制。
2.1.1. 图像感知压缩(Perceptual Image Compression)
图像感知压缩通过VAE自编码模型对原图进行处理,忽略掉原图中的高频细节信息,只保留一些重要、基础的特征。该模块并非必要,但是它的加入能够大幅降低训练和采样的计算成本,大大降低了图文生成任务的实现门槛。
基于感知压缩的扩散模型的训练过程有两个阶段:(1)训练一个自编码器;(2)训练扩散模型。在训练自编码器时,为了避免潜在表示空间出现高度的异化,作者使用了两种正则化方法,一种是KL-reg,另一种是VQ-reg,因此在官方发布的一阶段预训练模型中,会看到KL和VQ两种实现。在Stable Diffusion中主要采用AutoencoderKL这种正则化实现。
具体来说,图像感知压缩模型的训练过程如下:给定图像 x ∈ R H × W × 3 x\\in \\mathbbR^H\\times W\\times 3 x∈RH×W×3,我们先利用一个编码器 ε \\varepsilon ε来将图像从原图编码到潜在表示空间(即提取图像的特征) z = ε ( x ) z=\\varepsilon(x) z=ε(x),其中 z ∈ R h × w × c z\\in \\mathbbR^h\\times w\\times c z∈Rh×w×c。然后,用解码器从潜在表示空间重建图片 x ~ = D ( z ) = D ( ε ( x ) ) \\widetildex=\\mathcalD(z)=\\mathcalD(\\varepsilon(x)) x =D(z)=D(ε(x))。训练的目标是使 x = x ~ x=\\widetildex x=x 。
2.1.2. 隐扩散模型(Latent Diffusion Models)
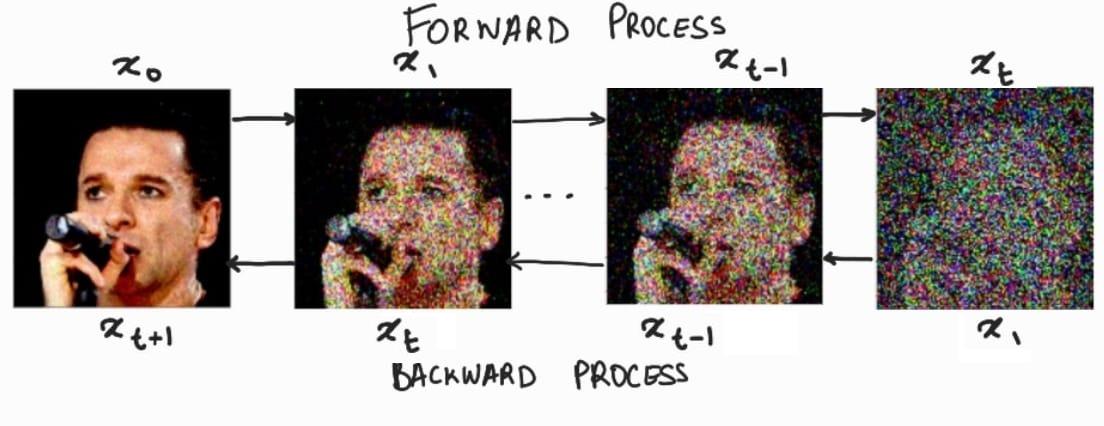
扩散模型(DM)从本质上来说,是一个基于马尔科夫过程的去噪器。其反向去噪过程的目标是根据输入的图像 x t x_t xt去预测一个对应去噪后的图像 x t + 1 x_t+1 xt+1,即 x t + 1 = ϵ t ( x t , t ) , t = 1 , . . . , T x_t+1=\\epsilon_t(x_t,t),\\ t=1,...,T xt+1=ϵt(xt,t), t=1,...,T。相应的目标函数可以写成如下形式: L D M = E x , ϵ ∼ N ( 0 , 1 ) , t = [ ∣ ∣ ϵ − ϵ θ ( x t , t ) ∣ ∣ 2 2 ] L_DM=\\mathbbE_x,\\epsilon\\sim\\mathcalN(0,1),t=[||\\epsilon-\\epsilon_\\theta(x_t,t)||_2^2] LDM=Ex,ϵ∼N(0,1),t=[∣∣ϵ−ϵθ(xt,t)∣∣22]这里默认噪声的分布是高斯分布 N ( 0 , 1 ) \\mathcalN(0,1) N(0,1),这是因为高斯分布可以应用重参数化技巧简化计算;此处的 x x x指的是原图。
而在潜在扩散模型中(LDM),引入了预训练的感知压缩模型,它包括一个编码器 ε \\varepsilon ε 和一个解码器 D \\mathcalD D。这样在训练时就可以利用编码器得到 z t = ε ( x t ) z_t=\\varepsilon(x_t) zt=ε(xt),从而让模型在潜在表示空间中学习,相应的目标函数可以写成如下形式: L L D M = E ε ( x ) , ϵ ∼ N ( 0 , 1 ) , t = [ ∣ ∣ ϵ − ϵ θ ( z t , t ) ∣ ∣ 2 2 ] L_LDM=\\mathbbE_\\varepsilon(x),\\epsilon\\sim\\mathcalN(0,1),t=[||\\epsilon-\\epsilon_\\theta(z_t,t)||_2^2] LLDM=Eε(x),ϵ∼N(0,1),t=[∣∣ϵ−ϵθ(zt,t)∣∣22]
2.1.3. 条件机制(Conditioning Mechanisms)
条件机制,指的是通过输入某些参数来控制图像的生成结果。这主要是通过拓展得到一个条件时序去噪自编码器(Conditional Denoising Autoencoder,CDA) ϵ θ ( z t , t , y ) \\epsilon_\\theta(z_t,t,y) ϵθ(zt,t,y)来实现的,这样一来我们就可通过输入参数 y y y 来控制图像生成的过程。
具体来说,论文通过在UNet主干网络上增加cross-attention机制来实现CDA,选用UNet网络是因为实践中Diffusion在UNet网络上效果最好。为了能够从多个不同的模态预处理参数 y y y,论文引入了一个领域专用编码器(Domain Specific Encoder) τ θ \\tau_\\theta τθ,它将 y y y映射为一个中间表示 τ θ ( y ) ∈ R M × d r \\tau_\\theta(y)\\in\\mathbbR^M\\times d_r τθ(y)∈RM×dr,这样我们就可以很方便的将 y y y设置为各种模态的条件(文本、类别等等)。最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d ) ⋅ V Attention(Q,K,V)=softmax(\\fracQK^\\top\\sqrtd)\\cdot V Attention(Q,K,V)=softmax(dQK⊤)⋅V Q = W Q ( i ) ⋅ φ i ( z t ) , K = W K ( i ) ⋅ τ θ ( y ) , V = W V ( i ) ⋅ τ θ ( y ) Q=W_Q^(i)\\cdot \\varphi_i(z_t),\\quad K=W_K^(i)\\cdot \\tau_\\theta(y),\\quad V=W_V^(i)\\cdot \\tau_\\theta(y) Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y)其中 φ i ( z t ) ∈ R N × d ϵ i \\varphi_i(z_t)\\in \\mathbbR^N\\times d_\\epsilon^i φi(zt)∈RN×dϵ