TensorFlow TFRecords简介
Posted 程序媛一枚~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow TFRecords简介相关的知识,希望对你有一定的参考价值。
TensorFlow TFRecords简介
这篇博客将介绍TensorFlow的TFRecords,提供有关TFRecords的所有信息的一应俱全的介绍。从如何构建基本TFRecords到用于训练 SRGAN 和 ESRGAN 模型的高级TFRecords的所有内容。包括什么是TFRecords,如何序列化,反序列化数据,以及如何使用TFRecords预处理和序列化像div2k这样的大型数据集,如何使用TFRecords及TensorFlow训练深度神经网络。
TFRecord格式的两个主要优点是,高效地存储数据集,并且与从磁盘读取原始数据相比,获得了更快的I/O速度。
当使用TPU训练深度神经网络时,TFRecords非常有用。可以查看SRGAN和ESRGAN教程,其中介绍了如何使用Tensor处理单元(TPUs ensor Processing Units)和图形处理单元(GPUs Graphics Processing Units )训练深度神经网络。
最好不使用tf.image.resize,坑太多
1. 效果图
可以看到原始数据和编码后数据相同,编码数据只是原始数据的字节字符串,TFRecord中的数据是序列化的二进制记录。
$ python single_tf_record.py
Original data: 12345
Encoded data: b'12345'
Data from the TFRecord: b'\\x05\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\xea\\xb2\\x04>12345z\\x1c\\xed\\xe8'
Decoded data: 12345
从输出中可以明显看出,原始数据被序列化为一系列字节字符串,随后被反序列化为原始数据。
$ python serialization.py
Original Data: [1 2 3 4]
Encoded Data: b'\\x08\\x04\\x12\\x04\\x12\\x02\\x08\\x04"\\x04\\x01\\x02\\x03\\x04'
Decoded Data: [1 2 3 4]
根据url下载网络图片,指定文件名,构建为TFRecord 数据,并序列化为二进制字符串保存到文件,然后读取在解析会照片和文件名,效果图如下:
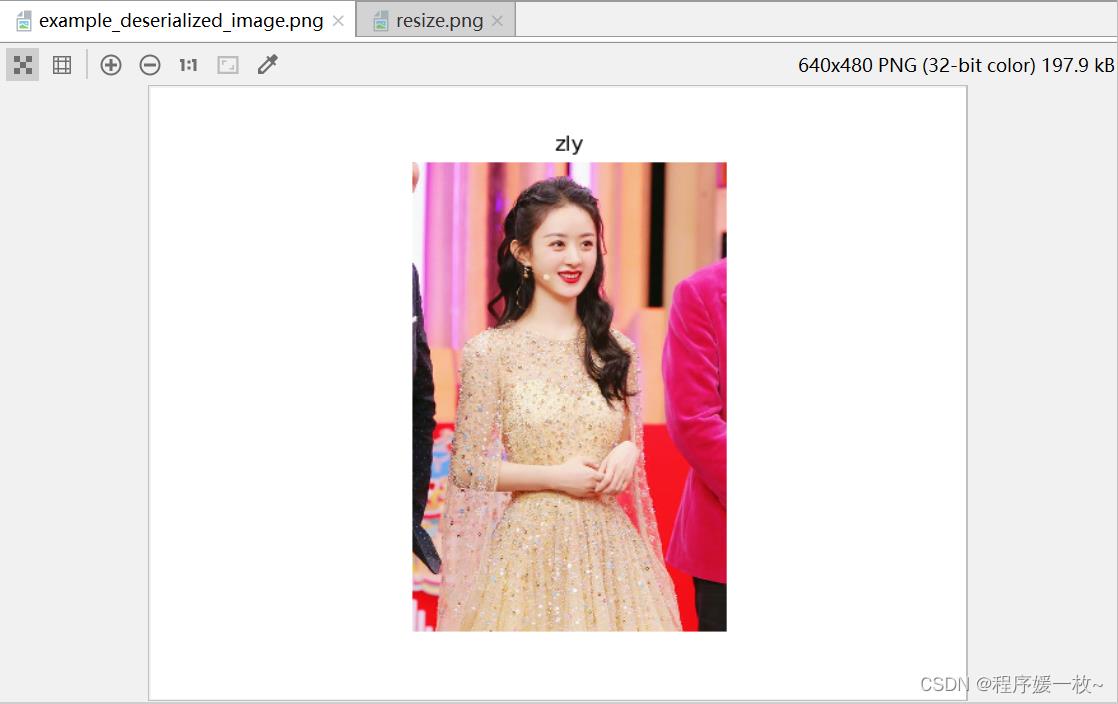
2. 原理
2.1 安装
pip install tensorflow==2.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install tensorflow --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow-datasets
2.2 TFRecord是什么
TFRecord是用于存储二进制记录序列的自定义TensorFlow格式。TFRecords针对TensorFlow进行了高度优化,因此具有以下优势:
- 高效的数据存储形式
- 与其他类型的格式相比,读取速度更快
TFRecords最重要的用例之一是使用TPU训练模型。TPU功能强大,但需要远程存储与之交互的数据。在TPU上训练模型时,以TFRecord格式远程存储数据集,因为它可以有效地保存数据并更容易地加载数据。
2.3 什么是序列化二进制记录?
TFRecords存储一系列二进制记录。因此首先需要学习如何将数据转换为二进制表示。
TensorFlow有两个公共API,负责将数据编码和解码为二进制记录。这两个公共API来自tf.io.serialize_tensor 和 tf.io.parse_tensor。
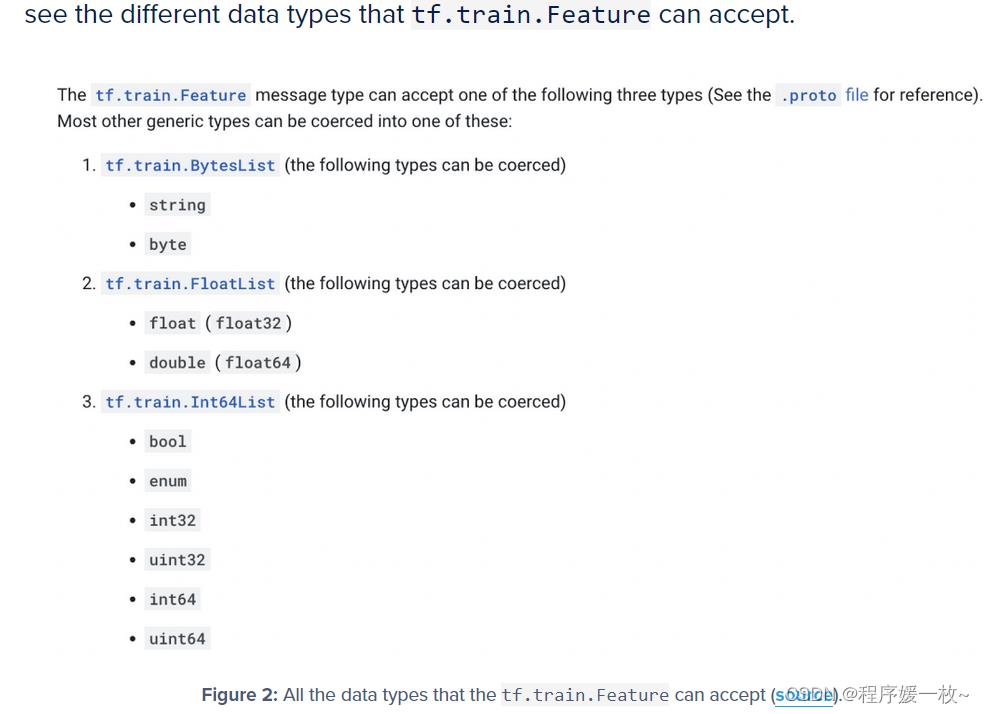
通过使用tf.train.Feature进行数据的序列化和反序列化,支持的类型如下:
2.4 DIV2K数据集
DIVerse 2K分辨率高质量图像
- 1000张2K分辨率的图像分为:800张用于训练的图像、100张用于验证的图像和100张用于测试的图像
- 对于每个挑战赛道(具有1.双三次或2.未知降级运算符),
- 高分辨率图像:0001.png,0002.png,…,1000.png
- 缩小的图像:YYYYx2.png表示缩小因子x2;其中YYYY是图像ID;
YYYYx3.png,缩小因子x3;
YYYYx4.png;缩小因子x4 - DIV2K forder结构如下:
DIV2K/–DIV2K数据集
DIV2K/DIV2K_train_HR/–0001.png,0002.png,…,0800.png列车HR图像(提供给参与者)
DIV2K/DIV2K_train_LR_bicubic/——使用Matlab调大小函数获得的具有默认设置的相应低分辨率图像(双三次插值)
3. 源代码
3.1 example_tf_record.py
# utils.py 从磁盘加载和保存图像到磁盘
# config.py 单个数据tfrecord示例的配置文件
# advance_config.py div2k数据集示例的配置文件
# single_tf_record.py 处理单个二进制记录并显示如何将其保存为TFRecord格式的脚本
# serialization.py 解释数据序列化重要性的脚本
# example_tf_record.py 保存和加载单个图片为TFRecord,如何从磁盘加载原始图像并以TFRecord格式对其进行序列化,以及如何加载序列化的TFRecord并对图像进行反序列化。
# create_tfrecords.py 生成高级TFRecords,保存和加载整个div2k数据集为TFRecords。将使用tfds(表示tensorflow_datasets,一组现成数据集)加载div2k数据集,对其进行预处理,然后将预处理的数据集序列化为TFRecords。
# DIV2K数据集:DIVerse 2K分辨率高质量图像
# 1000张2K分辨率的图像分为:800张用于训练的图像、100张用于验证的图像和100张用于测试的图像
# 对于每个挑战赛道(具有1.双三次或2.未知降级运算符),
# 高分辨率图像:0001.png,0002.png,…,1000.png
# 缩小的图像:YYYYx2.png表示缩小因子x2;其中YYYY是图像ID;
# YYYYx3.png,缩小因子x3;
# YYYYx4.png;缩小因子x4
# DIV2K forder结构如下:
# DIV2K/--DIV2K数据集
# DIV2K/DIV2K_train_HR/--0001.png,0002.png,…,0800.png列车HR图像(提供给参与者)
# DIV2K/DIV2K_train_LR_bicubic/——使用Matlab调大小函数获得的具有默认设置的相应低分辨率图像(双三次插值)
# USAGE
# python example_tf_record.py
import os
# 导入必要的包
import tensorflow as tf
from tfrecords_demo import config
from tfrecords_demo import utils
# 结构化的数据示例包括图片和图片名
# 从特定的url下载图像并将图像保存到磁盘。
imagePath = tf.keras.utils.get_file(
config.IMAGE_FNAME,
config.IMAGE_URL,
)
# 使用load_image函数从磁盘加载图像作为tf.Tensor
image = utils.load_image(pathToImage=imagePath)
class_name = config.IMAGE_CLASS
# 检查输出文件夹是否存在,不存在则创建
if not os.path.exists(config.OUTPUT_PATH):
os.makedirs(config.OUTPUT_PATH)
# 保存缩放后的照片
utils.save_image(image=image, saveImagePath=config.RESIZED_IMAGE_PATH)
# 构建图片tf.train.Feature和类名tf.train.Feature
imageFeature = tf.train.Feature(
bytes_list=tf.train.BytesList(value=[
# 注意序列化图像的方法
tf.io.serialize_tensor(image).numpy(),
])
)
classNameFeature = tf.train.Feature(
bytes_list=tf.train.BytesList(value=[
class_name.encode(),
])
)
# 包装图片和类名feature到一个feature字典中,并将其作为参数初始化一个类
features = tf.train.Features(feature=
"image": imageFeature,
"class_name": classNameFeature,
)
example = tf.train.Example(features=features)
# 序列化整个实例 使用SerializeToString函数直接序列化
serialized = example.SerializeToString()
# 将序列化实例写入 TFRecord
with tf.io.TFRecordWriter(config.TFRECORD_EXAMPLE_FNAME) as recordWriter:
recordWriter.write(serialized)
# 构建feature模式和 TFRecord数据
featureSchema =
"image": tf.io.FixedLenFeature([], dtype=tf.string),
"class_name": tf.io.FixedLenFeature([], dtype=tf.string),
# 读取数据构建TFRecord
dataset = tf.data.TFRecordDataset(config.TFRECORD_EXAMPLE_FNAME)
# 遍历数据
for element in dataset:
# 获取序列化实例数据,并根据feature模式解析
# 注意如何使用这里的特征示意图来解析示例。(序列化和反序列化时的数据类型是一样的)
element = tf.io.parse_single_example(element, featureSchema)
# 获取序列化后的类名和图像
className = element["class_name"].numpy().decode()
image = tf.io.parse_tensor(
element["image"].numpy(),
out_type=tf.dtypes.float32
)
# 使用图片名和图片保存反序列化后的图像
utils.save_image(
image=image,
saveImagePath=config.DESERIALIZED_IMAGE_PATH,
title=className
)
3.2 create_tfrecords.py
# USAGE
# python create_tfrecords.py
# 导入必要的包
import os
import tensorflow as tf
import tensorflow_datasets as tfds
from tfrecords_demo import config
# 定义自动调频对象以优化过程
AUTO = tf.data.experimental.AUTOTUNE
def pre_process(element):
# 获取低、高分辨率图像
lrImage = element["lr"]
hrImage = element["hr"]
# 将低高分辨率图像从Tensor张量转换为序列化的张量TensorProto proto
lrByte = tf.io.serialize_tensor(lrImage)
hrByte = tf.io.serialize_tensor(hrImage)
# 返回低、高分辨率proto对象
return (lrByte, hrByte)
def create_dataset(dataDir, split, shardSize):
print(config.DATASET, dataDir, shardSize)
# 加载数据集,保存到磁盘,并处理
ds = tfds.load(name="div2k", split=split, data_dir=dataDir,download=True)
ds = (ds
.map(pre_process, num_parallel_calls=AUTO)
.batch(shardSize)
)
# 返回数据集TensorFlow dataset object
return ds
def create_serialized_example(lrByte, hrByte):
# 创建低、高分辨率图像字节list
lrBytesList = tf.train.BytesList(value=[lrByte])
hrBytesList = tf.train.BytesList(value=[hrByte])
# 从字节list构建低、高分辨率推向feature
lrFeature = tf.train.Feature(bytes_list=lrBytesList)
hrFeature = tf.train.Feature(bytes_list=hrBytesList)
# 构建低、高分辨率图像feature字典
featureMap =
"lr": lrFeature,
"hr": hrFeature,
# 构建一个features集合,构建features实例,序列化实例
features = tf.train.Features(feature=featureMap)
example = tf.train.Example(features=features)
serializedExample = example.SerializeToString()
# 返回序列化的实例
return serializedExample
def prepare_tfrecords(dataset, outputDir, name, printEvery=50):
# 检查输出路径是否存在
if not os.path.exists(outputDir):
os.makedirs(outputDir)
# 遍历数据集,创建 TFRecords
for (index, images) in enumerate(dataset):
# 获取分片数,构建名称
shardSize = images[0].numpy().shape[0]
tfrecName = f"index:02d-shardSize.tfrec"
filename = outputDir + f"/name-" + tfrecName
# 写入 tfrecords
with tf.io.TFRecordWriter(filename) as outFile:
# write shard size serialized examples to each TFRecord
for i in range(shardSize):
serializedExample = create_serialized_example(
images[0].numpy()[i], images[1].numpy()[i])
outFile.write(serializedExample)
# 打印进度
if index % printEvery == 0:
print("[INFO] wrote file containing records..."
.format(filename, shardSize))
# ds = tfds.load('mnist', split='train', shuffle_files=True)
# ds = tfds.load('div2k', split='train[:5%]', shuffle_files=True)
# 创建div2k images的训练和验证数据集
print("[INFO] creating div2k training and testing dataset...")
trainDs = create_dataset(dataDir=config.DIV2K_PATH, split="train[:5%]",
shardSize=config.SHARD_SIZE)
testDs = create_dataset(dataDir=config.DIV2K_PATH, split="validation",
shardSize=config.SHARD_SIZE)
# 创建训练和测试 TFRecords,并写入磁盘
print("[INFO] preparing and writing div2k TFRecords to disk...")
prepare_tfrecords(dataset=trainDs, name="train",
outputDir=config.GPU_DIV2K_TFR_TRAIN_PATH)
prepare_tfrecords(dataset=testDs, name="test",
outputDir=config.GPU_DIV2K_TFR_TEST_PATH)
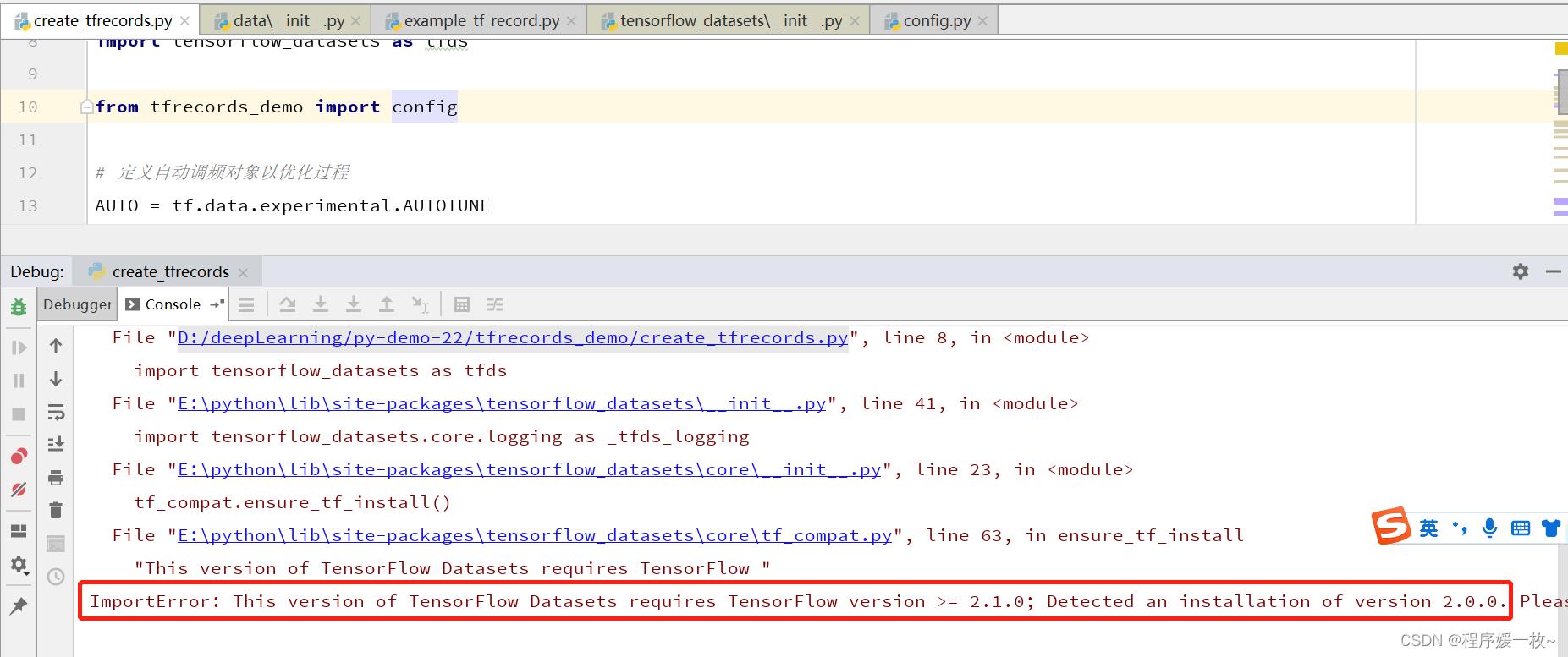
4. 报错及解决
- tf.data.experimental.AUTOTUNE
- tensorflow >=2.1.0
参考
以上是关于TensorFlow TFRecords简介的主要内容,如果未能解决你的问题,请参考以下文章
TensorFlow------TFRecords的读取实例