从GPU硬件架构看渲染流水线
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从GPU硬件架构看渲染流水线相关的知识,希望对你有一定的参考价值。
参考技术A以 nVidia MaxWell 为例,分析 GPU 的硬件架构
SP 是GPU 的最小运算单元,相当于一个微型 CPU,也叫 CudaCore。
PolyMorph Engine 是用来执行固定渲染步骤的硬件,一般包括这几个成部分
线程束(warp) 是 GPU 进行任务调度的基本单位,一个 warp 包含 32 个线程,也就是说 GPU 的调度,是以32个线程为单位的,即使只处理3个顶点,也会调度 32 个线程,占用 32 个 SP 进行计算,其中 29 个将会被 mask 为不可用状态
(1) 图形 API (OpenGL/DirectX/Metal) 发出DrawCall 时,指令被推送到驱动程序,对指令进行合法性检查后,指令被推送到 GPU 可以读取的 pushbuffer 中。
(2) 一段时间或显式调用 flush 指令时,驱动程序将 pushbuffer 中的指令发送给 GPU,GPU 中的主机接口 (HostInterface) 接受命令,通过 FrontEnd 进行处理。
(3) 图元分配器(Primitive Distributor) 处理 indexbuffer 中的顶点数据,产生三角形的批次,发送给多个 GPC 处理
(4) 指令到达 GPC 后,每个 SM 中 Poly Morph Engine 中的 Vertex Fetch 模块负责通过三角形索引取出三角形数据。
(5) 获取数据后,SM中的 Warp Scheduler 开始以 32 个线程为一组的线程束 warp 来调度,处理顶点数据。warp 是单指令多线程(SIMT, Single Intruction Multiple Thread) 的实现,32个线程同时执行同样的指令,但是各线程的数据不一样,比如 32 个顶点同时执行顶点着色器的指令。
(6) 单个 warp 中的线程会 锁步(lock step) 执行指令,没有分配到数据的线程将会被打上掩码,线程不能独立调度,必须以 warp 为单位,但不同 warp 之间是独立的。
(7) 指令执行时间长短不一样,特别是内存加载比较耗时,warp 调度器可能会直接切换到另外一个没有内存等待的 warp 执行,GPU 因此能够克服内存读取延迟。warp 在寄存器堆 RegisterFile 中都有属于自己的寄存器。
(8) 当 warp 执行完了顶点着色器的指令后,运算结果会传递给 Poly Morph Engine 中的 Viewport Transform 模块进行处理,通常顶点着色器输出的是裁剪空间的坐标,Viewport Transform 对顶点进行 裁剪 并进行 视口变换 ,也就是 屏幕映射 ,将顶点坐标变换为 屏幕坐标 。
(9) 得到屏幕坐标后,就可以进行 光栅化 了,三角形被分割,分配给多个 GPC(通常按照屏幕分 Tile 进行分配),三角形的范围决定了将会被分配给哪一个 GPC 的 Raster Engine,每个 Raster Engine 覆盖了屏幕的若干 Tile。
(10) GPC 上的 Raster Engine 对三角形数据进行光栅化,得到每个三角形所覆盖的像素信息,这里通常会进行背面剔除和 early-z 剔除操作。
(11) 一个三角形的三个顶点,每一个顶点都会执行一次顶点着色器和 Viewport Transform,处理后的信息传递给 Raster Engine 进行光栅化,得到若干个片元,那么每个片元的数据(位置、颜色、法线等)是怎么得来的呢?SM 上的 Attribute Setup 会根据顶点数据进行 插值 得到片元数据,L1&L2 缓存用来存放这些数据以确保 片元着色器 能够进行处理。
(12) 8个 2x2 的片元块(共32个)将会被 SM 中的 Warp Scheduler 分配到一个 warp 中执行片元着色器的指令。
(13) 片元着色器执行指令,完成片元颜色和深度计算,此时需要基于三角形的原始 API 提交顺序,将数据移交给渲染输出单元 ROP (Render Output Unit),一个 ROP 内部有很多 ROP 单元,ROP 单元中会处理 逐片元操作 如深度测试、与 FrameBuffer 中片元的混合等。
(14) ROP 拿到片元数据,通过访问 FrameBuffer 进行逐片元操作后,通过 Crossbar 将结果写入到 FrameBuffer,渲染流程结束。
GPU 中的内存分为若干类型,不同类型的内存读取速度相差比较大
Shader 中直接使用的寄存器内存速度很快,纹理和常常量内存以及全局内存的速度相对比较慢。
上述流程是 MaxWell 桌面 GPU 架构的渲染详细过程。然而移动端 GPU 的架构和桌面 GPU 是不同的。
移动端渲染流程是基于 Tile-Based 架构的,也叫 TBR(Tile-Based Render),针对一帧中的所有 DrawCall,先全部执行顶点着色器 VS,然后根据屏幕进行分块(Tile),基于 Tile 进行片元着色器(FS)的执行。
用一个例子来看。假如某一帧提交了两个DrawCall,每个DrawCall 包含了一个三角形,且两个三角形覆盖了全部屏幕。
第二章 渲染流水线 (下)
GPU流水线
上次已经说到GPU从CPU那里得到渲染命令,GPU渲染的过程就是GPU流水线。
虽然我们无法完全控制这两个?个阶段的实现细节,但GPU向开发者开放了很多控制权。
一.整体认识
这两个阶段可以分成若干个小的流水线
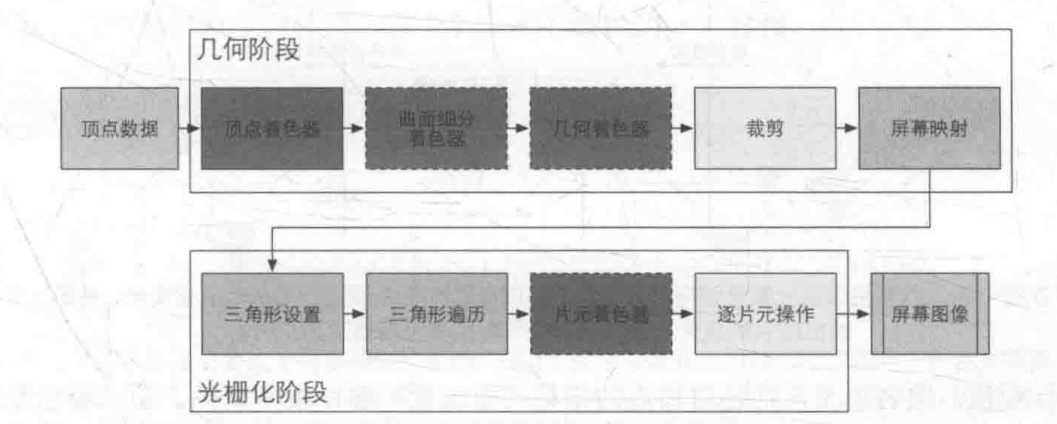
二.几何阶段(输出的信息是屏幕坐标系下的顶点位置以?及和它们相关的额外信息,如深度值(Z坐标)、法线方向、视角方向等。)
顶点着色器:
对象:输入进来的每一个顶点都要调用一次此着色器
权限:完全可编程,该shader必须由开发者编程完成
限制:无法创造和删除任何顶点,无法得到顶点之间的关系。
优点:速度快
作用:顶点空间变化(模拟水面和布料等,把顶点坐标从模型空间转换到齐次裁剪空间)顶点着色,逐顶点光照,
曲面细分着色器:
权限:可选着色器
作用:细分图元
几何着色器:
权限:可选着色器
作用:执行逐图元的着色操作,或产生更多的图元
裁剪:
权限:可配置
作用:剪掉不在摄影机视野范围内的顶点,可自定义裁剪平面配置裁剪区域(比如裁正面还是反面)
三种情况:
一个图元和摄像机视野的关系有3种:完全在视野内、部分在视野内、完全在视野外。完全
在视野内的图元就继续传递给下一个流水线阶段,完全在视野外的图元不会继续向下传递,因为
它们不需要被渲染。而那些部分在视野内的图元需要进行一个处理,这就是裁剪。例如,一条线
段的一个顶点在视野内,而另一个顶点不在视野内,那么在视野外部的顶点应该使用一个新的顶
点来代替,这个新的顶点位于这条线段和视野边界的交点处。
屏幕映射:
来源:三维坐标系的坐标
输出:屏幕坐标系
权限:不可配置和编程
作用:图元坐标转换成屏幕坐标
三.光栅化阶段(目的:计算每个图元覆盖了哪些像素,以及为这些像素计算它们的颜色。)
三角形设置:固定函数
解释:一个计算三角网格表示数据的过程
可以理解为将上个阶段的顶点,得到边界信息(变成三角形网格),方便以后判断像素是否被覆盖
三角形遍历:固定函数、
理解:扫描看哪些像素被覆盖
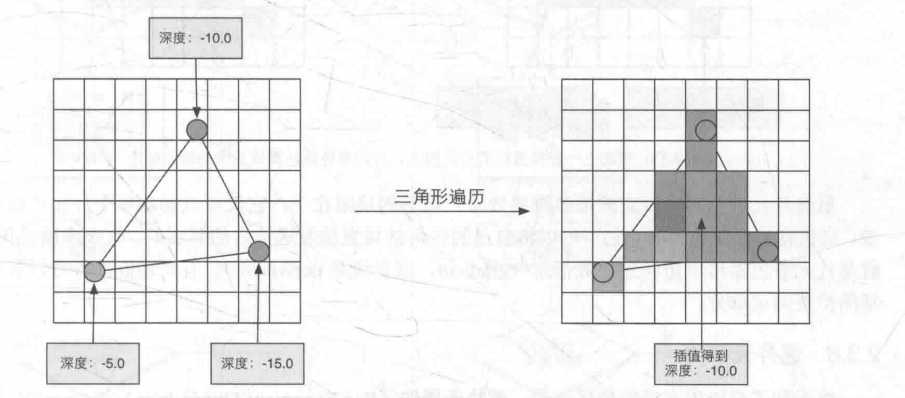
这一步的输出就是得到一个片元序列。需要注意的是,一个片元并不是真正意义上的像素,?而是包含了很多状态的集合,这些状态用于计算每个像素的最终颜色。这些状态包括了(但不限?于)它的屏幕坐标、深度信息,以及其他从几何阶段输出的顶点信息,例如法线、纹理坐标等。
片元着色器:
输入:上一个阶段对顶点信息插值得到的结果。
输出:一个或者多个颜色值
渲染技术:纹理釆样(其中最重要),
这一阶段可以完成很多重要的渲染技术,其中最重要的技术之一就是纹理釆样。为了在片元
着色器中进行纹理采样,我们通常会在顶点着色器阶段输出每个顶点对应的纹理坐标,然后经过
光栅化阶段对三角网格的3个顶点对应的纹理坐标进行插值后,就可以得到其覆盖的片元的纹理
权限:完全可编程
作用:逐片元着色。
逐片元操作:
任务:
(1) 决定每个片元的可见性。这涉及了很多测试工作,例如深度测试、模板测试等。
(2) 如果一个片元通过了所有的测试,就需要把这个片元的颜色值和已经存储在颜色缓冲区
中的颜色进行合并,或者说是混合。
权限:不可编程,但有很高的可配置性
作用:例如修改颜色,深度缓冲,进行混合等
以上是关于从GPU硬件架构看渲染流水线的主要内容,如果未能解决你的问题,请参考以下文章