MySQL分页到了后面越来越慢,有什么好的解决办法?
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL分页到了后面越来越慢,有什么好的解决办法?相关的知识,希望对你有一定的参考价值。
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识其实这个也是最常问的面试题了
eg:面试官问了我一道题:mysql 单表上亿,怎么优化分页查询?
方案概述
方案一:优化现有mysql数据库。优点:不影响现有业务,源程序不需要修改代码,成本最低。缺点:有优化瓶颈,数据量过亿就玩完了。
方案二:升级数据库类型,换一种100%兼容mysql的数据库。优点:不影响现有业务,源程序不需要修改代码,你几乎不需要做任何操作就能提升数据库性能,缺点:多花钱
方案三:一步到位,大数据解决方案,更换newsql/nosql数据库。优点:扩展性强,成本低,没有数据容量瓶颈,缺点:需要修改源程序代码
以上三种方案,按顺序使用即可,数据量在亿级别一下的没必要换nosql,开发成本太高。三种方案我都试了一遍,而且都形成了落地解决方案。该过程心中慰问跑路的那几个开发者一万遍 :曹尼玛,这代码怎么写的?)
limit分页原理
当我们翻到最后几页时,查询的sql通常是:select * from table where column=xxx order by xxx limit 1000000,10。
查询非常慢。但是我们查看前几页的时候,速度并不慢。这是因为limit的偏移量太大导致的。
MySql使用limit时的原理是(用上面的例子举例):
MySql将查询出1000010条记录。
然后舍掉前面的1000000条记录。
返回剩下的10条记录。
上述的过程是在《高性能MySql》书中确认的。
今天直说SQL相关的优化!
1、表容量的问题
2、总页数的问题
2.1、页面不需要显示总页数,仅显示附近的页码,这样可以避免单表总行数的查询。
2.2需要显示总页数 :
使用 InnoDB 引擎,新建一张表记录业务表的总数,新增、删除各自在同一事务中增减总行数然后查询,保证事务的一致性和隔离性。当然,这里更新总行数要借助分布式锁或 CAS 方式更新记录总数的表。
不带条件 + 自增 id 字段连续
where id >= ? and id < ?
where id between
where id >= ? limit 10主键 id + 带查询条件
select * from table t1
join
(select id from table where condition limit 10) t2
on t1.id = t2.id
order by t1.id asc毕竟偏移量越大,花费时间越长!
优化偏移量大问题 采用子查询方式 我们可以先定位偏移位置的 id,然后再查询数据
SELECT * FROM `user_operation_log` LIMIT 1000000, 10
SELECT id FROM `user_operation_log` LIMIT 1000000, 1
SELECT * FROM `user_operation_log` WHERE id >= (SELECT id FROM `user_operation_log` LIMIT 1000000, 1)第一条花费的时间最大,第三条比第一条稍微好点
子查询使用索引速度更快
以上只适用于id递增的情况。
SELECT * FROM `user_operation_log` WHERE id IN (SELECT t.id FROM (SELECT id FROM `user_operation_log` LIMIT 1000000, 10) AS t)采用 id 限定方式
这种方法要求更高些,id必须是连续递增,而且还得计算id的范围,然后使用 between,sql如下
SELECT * FROM `user_operation_log` WHERE id between 1000000 AND 1000100 LIMIT 100
SELECT * FROM `user_operation_log` WHERE id >= 1000000 LIMIT 100总结
1.合理使用索引
索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率。现在大多数的数据库产品都采用IBM最先提出的ISAM索引结构。索引的使用要恰到好处,其使用原则如下:
●在经常进行连接,但是没有指定为外键的列上建立索引,而不经常连接的字段则由优化器自动生成索引。
●在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引。
●在条件表达式中经常用到的不同值较多的列上建立检索,在不同值少的列上不要建立索引。比如在雇员表的“性别”列上只有“男”与“女”两个不同值,因此就无必要建立索引。如果建立索引不但不会提高查询效率,反而会严重降低更新速度。
●如果待排序的列有多个,可以在这些列上建立复合索引(compound index)。
●使用系统工具。如Informix数据库有一个tbcheck工具,可以在可疑的索引上进行检查。在一些数据库服务器上,索引可能失效或者因为频繁操作而使得读取效率降低,如果一个使用索引的查询不明不白地慢下来,可以试着用tbcheck工具检查索引的完整性,必要时进行修复。另外,当数据库表更新大量数据后,删除并重建索引可以提高查询速度。
2.避免或简化排序
应当简化或避免对大型表进行重复的排序。当能够利用索引自动以适当的次序产生输出时,优化器就避免了排序的步骤。以下是一些影响因素:
●索引中不包括一个或几个待排序的列;
●group by或order by子句中列的次序与索引的次序不一样;
●排序的列来自不同的表。
为了避免不必要的排序,就要正确地增建索引,合理地合并数据库表(尽管有时可能影响表的规范化,但相对于效率的提高是值得的)。如果排序不可避免,那么应当试图简化它,如缩小排序的列的范围等。
3.消除对大型表行数据的顺序存取
在嵌套查询中,对表的顺序存取对查询效率可能产生致命的影响。比如采用顺序存取策略,一个嵌套3层的查询,如果每层都查询1000行,那么这个查询就要查询10亿行数据。避免这种情况的主要方法就是对连接的列进行索引。例如,两个表:学生表(学号、姓名、年龄……)和选课表(学号、课程号、成绩)。如果两个表要做连接,就要在“学号”这个连接字段上建立索引。
4.避免相关子查询
一个列的标签同时在主查询和where子句中的查询中出现,那么很可能当主查询中的列值改变之后,子查询必须重新查询一次。查询嵌套层次越多,效率越低,因此应当尽量避免子查询。如果子查询不可避免,那么要在子查询中过滤掉尽可能多的行。
5.避免困难的正规表达式
MATCHES和LIKE关键字支持通配符匹配,技术上叫正规表达式。但这种匹配特别耗费时间。例如:SELECT * FROM customer WHERE zipcode LIKE “98_ _ _”
即使在zipcode字段上建立了索引,在这种情况下也还是采用顺序扫描的方式。如果把语句改为SELECT * FROM customer WHERE zipcode >“98000”,在执行查询时就会利用索引来查询,显然会大大提高速度。
另外,还要避免非开始的子串。例如语句:SELECT * FROM customer WHERE zipcode[2,3]>“80”,在where子句中采用了非开始子串,因而这个语句也不会使用索引。
6.使用临时表加速查询
把表的一个子集进行排序并创建临时表,有时能加速查询。它有助于避免多重排序操作,而且在其他方面还能简化优化器的工作。
临时表中的行要比主表中的行少,而且物理顺序就是所要求的顺序,减少了磁盘I/O,所以查询工作量可以得到大幅减少。
注意:临时表创建后不会反映主表的修改。在主表中数据频繁修改的情况下,注意不要丢失数据。
7.用排序来取代非顺序存取
非顺序磁盘存取是最慢的操作,表现在磁盘存取臂的来回移动。SQL语句隐藏了这一情况,使得我们在写应用程序时很容易写出要求存取大量非顺序页的查询。
有些时候,用数据库的排序能力来替代非顺序的存取能改进查询。
索引失效原因:
1、对索引列运算,运算包括(+、-、*、/、!、<>、%、like'%_'(%放在前面)
2、类型错误,如字段类型为varchar,where条件用number。
3、对索引应用内部函数,这种情况下应该建立基于函数的索引
如select * from template t where ROUND(t.logicdb_id) = 1
此时应该建ROUND(t.logicdb_id)为索引,mysql8.0开始支持函数索引,5.7可以通过虚拟列的方式来支持,之前只能新建一个ROUND(t.logicdb_id)列然后去维护
4、如果条件有or,即使其中有条件带索引也不会使用(这也是为什么建议少使用or的原因),如果想使用or,又想索引有效,只能将or条件中的每个列加上索引
5、如果列类型是字符串,那一定要在条件中数据使用引号,否则不使用索引;
6、B-tree索引 is null不会走,is not null会走,位图索引 is null,is not null 都会走
7、组合索引遵循最左原则
说到这里呢?怎么去找一些Mysql的实战案例:
实例说明:
我们在开发的过程中使用分页是不可避免的,通常情况下我们的做法是使用limit加偏移量:
select * from table where column=xxx order by xxx limit 1,50
当数据量比较小时(100万以内),无论你翻到哪一页,性能都是很快的。如果查询慢,只要在
where条件和order by 的列上加上索引就可以解决。但是,当数据量大的时候(小编遇到的情况
是500万数据),如果翻到最后几页,即使加了索引,查询也是非常慢的,这是什么原因导致的呢?我们该如何解决呢?
SELECT
*
FROM
table t
INNER JOIN (
SELECT
id
FROM
table
WHERE
xxx_id = 132381
LIMIT 800000,50
) t1 ON t.id = t1.id上述的sql可以写成如下方式,最后,没有优化过的sql,执行时间为2s多,优化后的sql执行时间是0.3秒多。
总之有以下的几个方式:
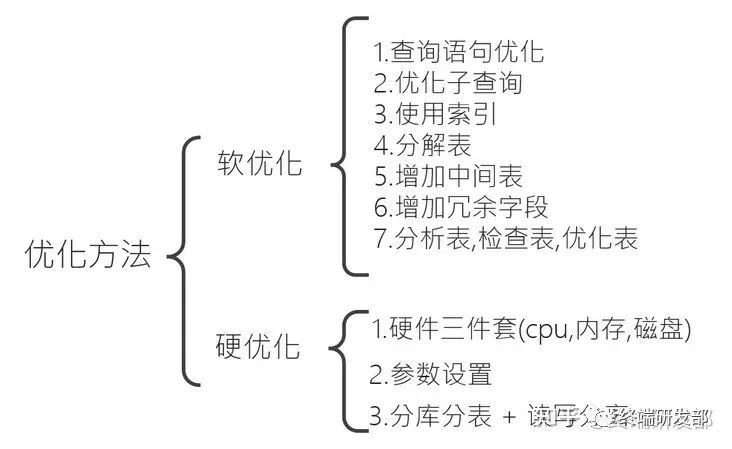
一个完整而复杂的高并发系统架构中,一定会包含:各种复杂的自研基础架构系统。各种精妙的架构设计.因此一篇小文顶多具有抛砖引玉的效果,但是数据库优化的思想差不多就这些了
PS:如果想学习技术,或者在学习技术的过程中有疑问,对编程方向的选择,可以来这里找小于哥,一个有思想有规划,被代码延误的心灵导师,可咨询offer的选择,职业规划,学习路线,技术开发中的问题
我是终端研发部的小于哥
天专注技术开发小技巧,技术教程进阶,职场经验,面试的分享,希望我的回答能够帮助到你哈,笔芯~

回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
用 Spring 的 BeanUtils 前,建议你先了解这几个坑!
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的
在这里获得的不仅仅是技术!


喜欢就给个“在看”
以上是关于MySQL分页到了后面越来越慢,有什么好的解决办法?的主要内容,如果未能解决你的问题,请参考以下文章