黄佳《零基础学机器学习》chap3笔记
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了黄佳《零基础学机器学习》chap3笔记相关的知识,希望对你有一定的参考价值。
黄佳 《零基础学机器学习》 chap3笔记
第3课 线性回归——预测网店的销售额
文章目录
- 黄佳 《零基础学机器学习》 chap3笔记
- 第3课 线性回归——预测网店的销售额
- 3.1 问题定义:小冰的网店广告该如何投放
- 3.2 数据的收集和预处理
- 3.3 选择机器学习模型
- 3.4 通过梯度下降找到最佳参数
- 3.5 实现一元线性回归模型并调试超参数
- 3.6 实现多元线性回归模型
- 3.7 本课内容小结
- 3.8 练习题
-
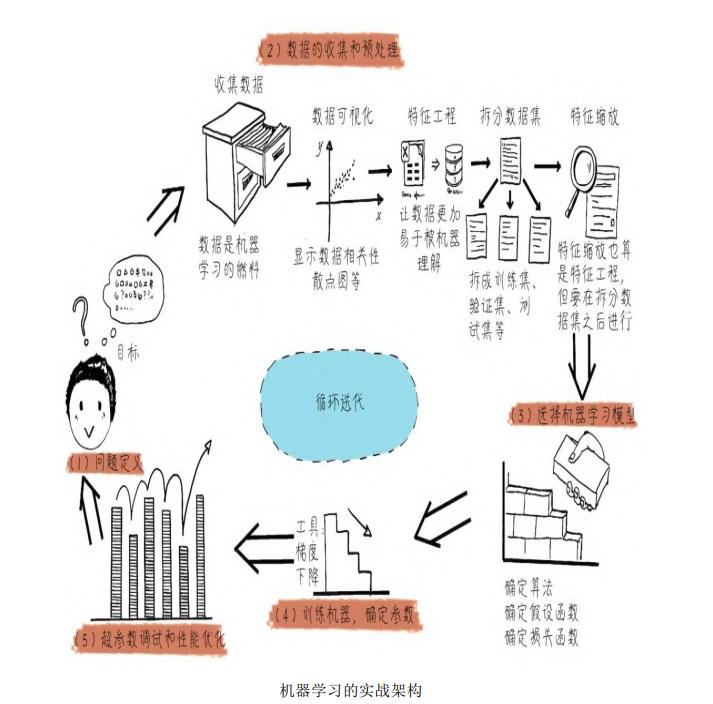
回顾chap1所学的机器学习的实战架构
-
本课重点
-
情景引入
-
明确定义所要解决的问题—网店销售额的预测。
-
在数据的收集和预处理环节,分5个小节完成数据的预处理工作,分别如下。
- 收集数据─需要小冰提供网店的相关记录。
- 将收集到的数据可视化,显示出来看一看。
- 做特征工程,使数据更容易被机器处理。
- 拆分数据集为训练集和测试集。
- 做特征缩放,把数据值压缩到比较小的区间。
-
选择机器学习模型的环节,其中有3个主要内容。
- 确定机器学习的算法—这里也就是线性回归算法。
- 确定线性回归算法的假设函数。
- 确定线性回归算法的损失函数。
-
通过梯度下降训练机器,确定模型内部参数的过程。
-
进行超参数调试和性能优化。
为了简化模型,上面的5个机器学习环节,将先用于实现单变量(仅有一个特征)的线性回归,在本课最后,还会扩展到多元线性回归。此处,先看看本课重点。
-
3.1 问题定义:小冰的网店广告该如何投放
-
小冰已经准备好了她的问题。这些问题都与广告投放金额和商品销售额有关,她希望通过机器学习算法找出答案。
- (1)各种广告和商品销售额的相关度如何?
- (2)各种广告和商品销售额之间体现出一种什么关系
- (3) 哪一种广告对于商品销售额的影响最大?
- (4)分配特定的广告投放金额,预测出未来的商品销售额。
-
机器学习算法正是通过分析已有的数据,发现两者之间的关系,也就是发现一个能由“此”推知“彼”的函数。本课通过回归分析来寻找这个函数。
-
所谓回归分析(regression analysis),是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,也就是研究当自变量x变化时,因变量y以何种形式在变化。在机器学习领域,回归应用于被预测对象具有连续值特征的情况(如客流量、降雨量、销售量等), 所以用它来解决小冰的这几个问题非常合适。
-
最基本的回归分析算法是线性回归,它是通过线性函数对变量间定量关系进行统计分析。比如,一个简单函数y=2x+1,就体现了一个一元 (只有一个自变量)的线性回归,其中2是斜率,1是y轴上的截距。
-
我们初学者常常见到的入门案例就是房价预测
不难理解,房屋的售价与某些因素呈现比较直接的线性关系,比如房屋面积越大,售价越高。如下图所示,线性函数对此例的拟合效果比较好。
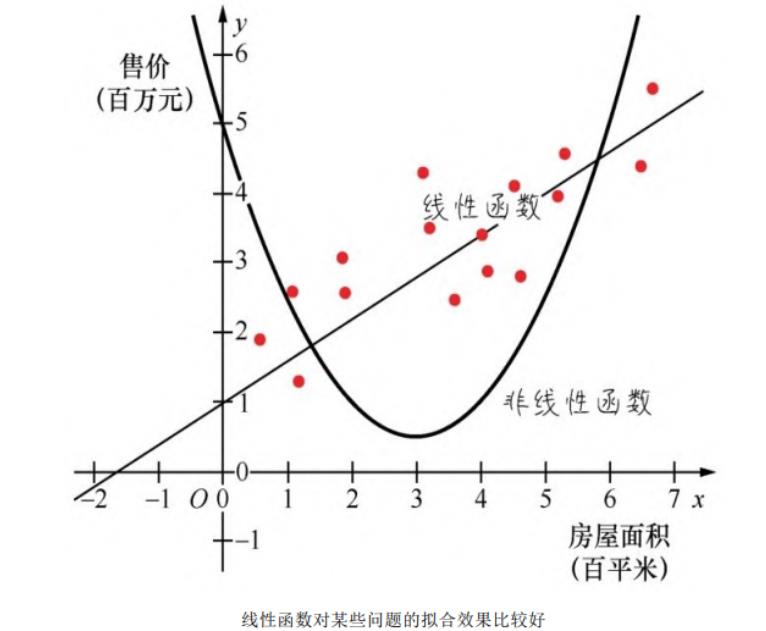
- 在机器学习的线性回归分析中,如果只包括一个自变量(特征x) 和一个因变量(标签y),且两者的关系可用一条直线近似表示,这种回归分析就称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析 。
3.2 数据的收集和预处理
3.2.1 收集网店销售额数据
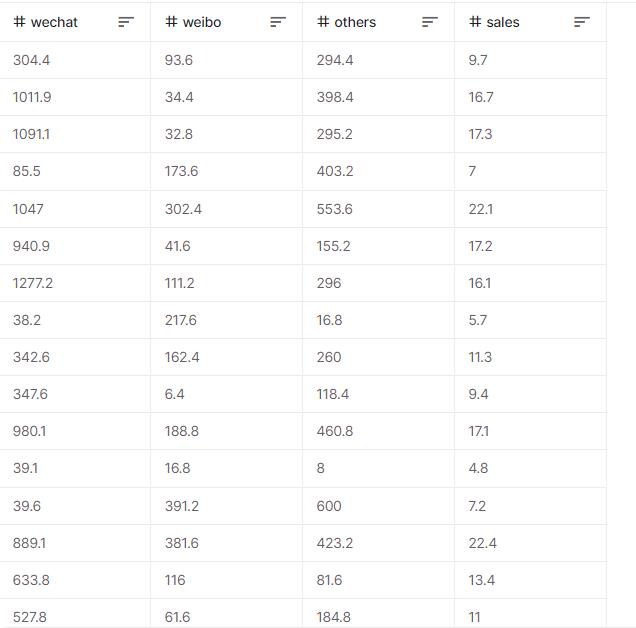
- 小冰把过去每周的广告投放金额和销售额数据整理成一个Excel表格(如下图所示),并保存为advertising.csv文件(这是以逗号为分隔符的一种文件格式,比较容易被Python读取)。基本上每周的各种广告投放金额和商品销售额都记录在案。
3.2.2 数据读取和可视化
import numpy as np #导入NumPy数学工具箱
import pandas as pd #导入Pandas数据处理工具箱
#读入数据并显示前面几行的内容,确保已经成功的读入数据
#注意路径 如当数据集和代码文件位于相同本地目录,路径名应为'./advertising.csv',或直接放'advertising.csv'亦可
df_ads = pd.read_csv('../input/text3adverse/advertising.csv')
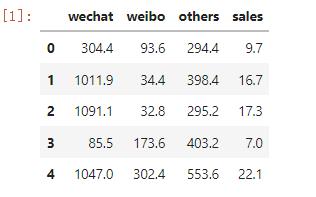
df_ads.head()
-
这里的变量命名为df_ads,df代表这是一个Pandas Dataframe格式数据,ads是广告的缩写。
-
输出结果(如下图所示)显示数据已经成功地读入了Dataframe
3.2.3 数据的相关分析
-
然后对数据进行相关分析correlation analysis。相关分析后我们可以通过相关性系数了解数据集中任意一对变量(a,b)之间的相关性。相关性系数是一个-1~1的值,正值表示正相关,负值表示负相关。数值越大,相关性越强。
- 如果a和b的相关性系数是1,则a和b总是相等的。
- 如果a和b的相关性系数是0.9,则b会显著地随着a的变化而变化,而且变化的趋势保持一致。
- 如果a和b的相关性系数是0.3,则说明两者之间并没有什么明显的联系。
-
在Python中,相关分析用几行代码即可实现,并可以用热力图 (heatmap)的方式非常直观地展示出来:
import matplotlib.pyplot as plt import seaborn as sns #Seaborn – 统计学数据可视化工具库 #对所有的标签和特征两两显示其相关性的热力图(heatmap) sns.heatmap(df_ads.corr(), cmap="YlGnBu", annot = True) plt.show() #plt代表英文plot,就是画图的意思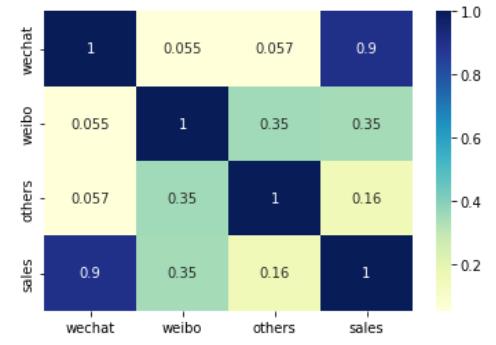
-
运行代码之后,3个特征加一个标签共4组变量之间的相关性系数全部以矩阵形式显示,而且相关性越高,对应的颜色越深。此处相关性分析结果很明确地向我们显示—将有限的金钱投放到微信公众号里面做广告是最为合理的选择
3.2.4 数据的散点图
- 下面,通过散点图(scatter plot)两两一组显示商品销售额和各种广告投放金额之间的对应关系,来将重点聚焦。
- 散点图是回归分析中, 数据点在直角坐标系平面上的分布图,它是相当有效的数据可视化工具。
#显示销量和各种广告投放量的散点图
sns.pairplot(df_ads,
x_vars=['wechat', 'weibo', 'others'],
y_vars='sales',
height=4, aspect=1, kind='scatter')
plt.show()
代码运行之后输出的散点图清晰地展示出了销售额随各种广告投放金额而变化的大致趋势,根据这个信息,就可以选择合适的函数对数据点进行拟合。
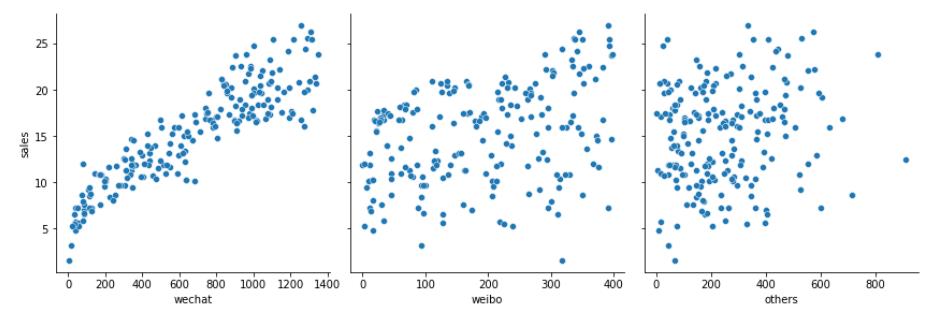
3.2.5 数据集清洗和规范化
通过观察相关性和散点图,发现在本案例的3个特征中,微信广告投放金额和商品销售额的相关性比较高。因此,为了简化模型,我们将暂时忽略微博广告和其他类型广告投放金额这两组特征,只留下微信广告投放金额数据。这样,就把多变量的回归分析简化为单变量的回归分析。
数据清洗
-
下面的代码把df_ads中的微信公众号广告投放金额字段读入一个 NumPy数组X,也就是清洗了其他两个特征字段,并把标签读入数组y:
X = np.array(df_ads.wechat) #构建特征集,只含有微信广告一个特征 y = np.array(df_ads.sales) #构建标签集,销售金额 print ("张量X的阶:",X.ndim) print ("张量X的形状:", X.shape) print ("张量X的内容:", X)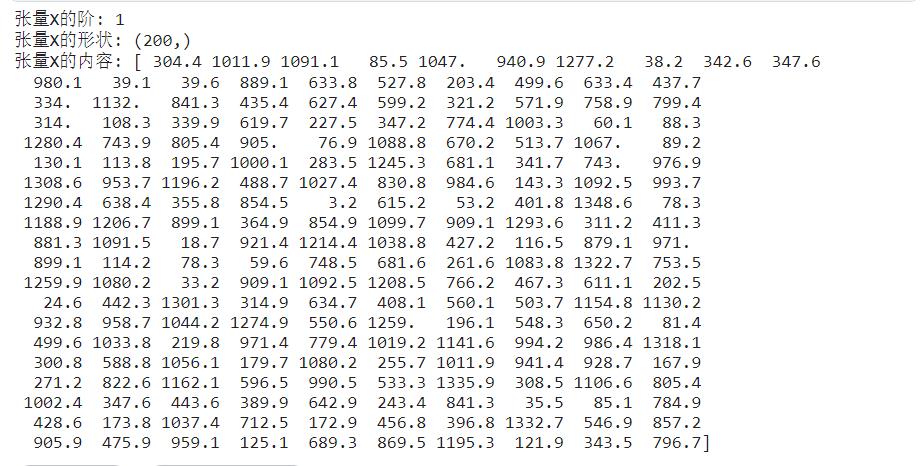
数据规范化
-
(200,)这种表述形式代表一个有200个样本数据为1阶的张量数组,也就是一个向量。
目前X数组中只有一个特征,张量的阶为1,那么这个1D的特征张量,是机器学习算法能够接受的格式吗?
-
对于回归问题的数值类型数据集,机器学习模型所读入的规范格式应该是2D张量,也就是矩阵,其形状为 (样本数,标签数)。其中的行是数据,而其中的列是特征。
-
那么就现在的特征张量X而言,则是要把它的形状从(200,)变成(200,1),然后再进行机器学习。
-
因此需要用 reshape方法给上面的张量变形:
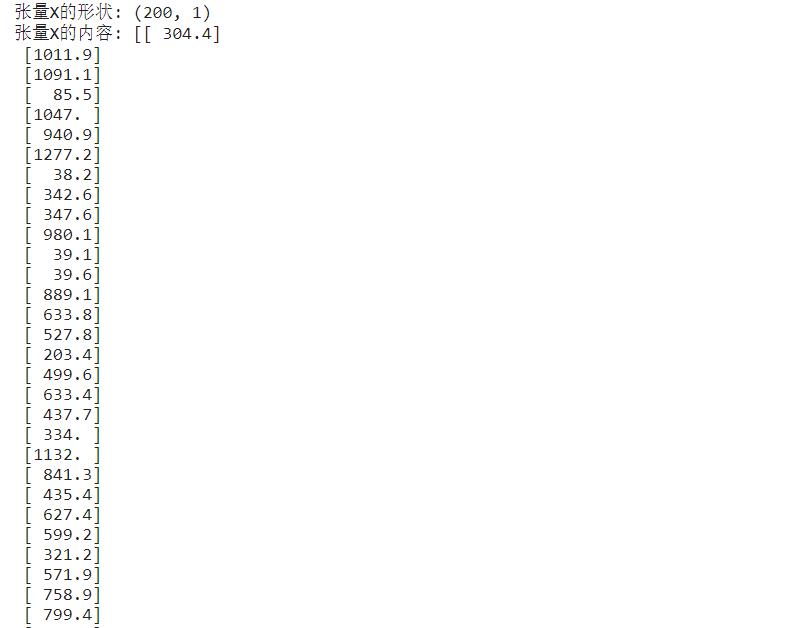
X = X.reshape((len(X),1)) #通过reshape函数把向量转换为矩阵,len函数返回样本个数 y = y.reshape((len(y),1)) #通过reshape函数把向量转换为矩阵,len函数返回样本个数print ("张量X的阶:",X.ndim) print ("张量X的形状:", X.shape) print ("张量X的内容:", X)
-
现在数据格式从(200,)变成了(200,1)。尽管还是200个数字,但是数据的结构从一个1D数组变成了有行有列的矩阵。再次强调,对于常见的连续性数值数据集(也叫向量数据集),输入特征集是 2D矩阵,包含两个轴。
-
第一个轴是样本轴(NumPy里面索引为0),也叫作矩阵的行, 本例中一共200行数据。
-
第二个轴是特征轴(NumPy里面索引为1),也叫作矩阵的列, 本例中只有1个特征。 对于标签张量y,第二个轴的维度总是1,因为标签值只有一个。这里也可以把它转换为2阶张量。
-
3.2.6 拆分数据集为训练集和测试集
-
在开始建模之前,还需要把数据集拆分为两个部分:训练集和测试集。
- 在普通的机器学习项目中,至少要包含这两个数据集,一个用于训练机器,确定模型,另一个用于测试模型的准确性。
- 不仅如此,往往还需要一个验证集,以在最终测试之前增加验证环节。目前这个问题比较简单,数据量也少,我们简化了流程,合并了验证和测试环节。
-
这两个数据集需要随机分配,两者间不可以出现明显的差异性。因此,在拆分之前,要注意数据是否已经被排序或者分类,如果是,还要先进行打乱。
-
使用下面的代码段将数据集进行80%(训练集)和20%(测试集) 的分割:
#将数据集进行80%(训练集)和20%(测试集)的分割 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)- Sklearn中的train_test_split函数,是机器学习中拆分数据集的常用工具
- test_size=0.2,表示拆分出来的测试集占总样本量的20%。
- 用print语句输出拆分之后的新数据集(如X_train、 X_test)的内容,会发现这个工具已经为数据集进行了乱序(重新随机 排序)的工作,因为其中的shuffle参数默认值为True。
- 而其中的random_state参数,则用于数据集拆分过程的随机化设定。如果指定了一个整数,那么这个数叫作随机化种子,每次设定固定的种子能够保证得到同样的训练集和测试集,否则进行随机分割。
- test_size=0.2,表示拆分出来的测试集占总样本量的20%。
- Sklearn中的train_test_split函数,是机器学习中拆分数据集的常用工具
3.2.7 把数据归一化
- 第1课中曾经介绍过几种特征缩放的方法,包括示准化、数据的压缩(也叫归一化),以及规范化等。
- 特征缩放对于机器学习特别重要,可以让机器在读取数据的时候感觉更“舒服”,训练起来效率更高。
- 这里就对数据进行归一化。归一化是按比例的线性缩放。数据归一化之后,数据分布不变,但是都落入一个小的特定区间,比如0~1或者-1~+1,如图所示。
-
一个常见的归一化的公式如下
X ′ = X − min ( X ) max ( X ) − min ( X ) X^\\prime=\\fracX-\\min (X)\\max (X)-\\min (X) X′=max(X)−min(X)X−min(X) -
通过Sklearn库中preprocessing(数据预处理)工具中的Min Max Scaler可以实现数据的归一化。
-
但是在此处,我们先用Python代码自己来手写定义一个归一化函数:
def scaler(train, test): #定义归一化函数,进行数据压缩 min = train.min(axis=0) #训练集最小值 max = train.max(axis=0) #训练集最大值 gap = max - min #最大值和最小值的差 train -= min #所有数据减最小值 train /= gap #所有数据除以大小值差 test -= min #把训练集最小值应用于测试集 test /= gap #把训练集大小值差应用于测试集 return train, test #返回压缩后的数据这个函数的功能等价于下面的伪代码
#数据的归一化 x_norm = (x_data - np.min(x_data))/(np.max(x_data)-np.min(x_data)).values- 上面的代码中,特别需要注意的是归一化过程中的最大值(max)、最小值(min),以及最大值和最小值之间的差(gap),全都来自训练集。不能使用测试集中的数据信息进行特征缩放中间步骤 中任何值的计算。
举例来说,如果训练集中的广告投放金额最大值是 350,测试集中的广告投放金额最大值是380,尽管380大于350,但归一化函数还是要以350作为最大值,来处理训练集和测试集的所有数据。
- 为什么非要这样做呢?因为,在建立机器学习模型时,理论上测试集还没有出现,所以这个步骤一定要在拆分数据集之后进行。有很多人先对整个数据集进行特征缩放,然后拆分数据集,这种做法是不谨慎的,会把测试集中的部分信息泄露到机器学习的建模过程之中。下面的代码使用刚才定义的归一化函数对特征和标签进行归一化。
X_train,X_test = scaler(X_train,X_test) #对特征归一化 y_train,y_test = scaler(y_train,y_test) #对标签也归一化 -
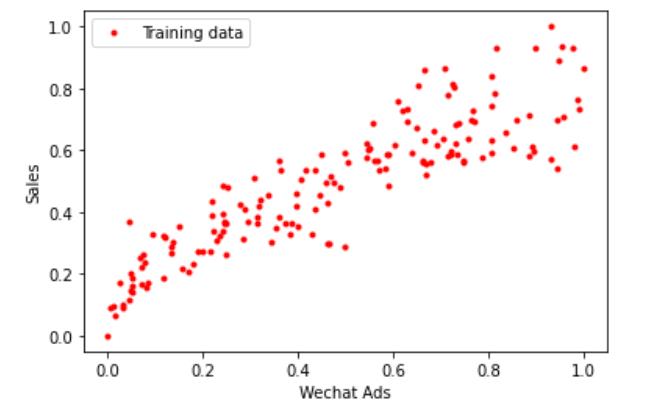
下面的代码显示数据被压缩处理之后的散点图,形状和之前的图完全一致,只是数值已被限制在一个较小的区间:
#用之前已经导入的matplotlib.pyplot中的plot方法显示散点图 plt.plot(X_train,y_train,'r.', label='Training data') plt.xlabel('Wechat Ads') # x轴Label plt.ylabel('Sales') # y轴Label plt.legend() # 显示图例 plt.show() # 显示绘图结果
3.3 选择机器学习模型
-
机器学习模型的确立过程中有两个主要环节。
-
确定选用什么类型的模型。
-
确定模型的具体参数。
下面我们先聚焦于第一个问题
-
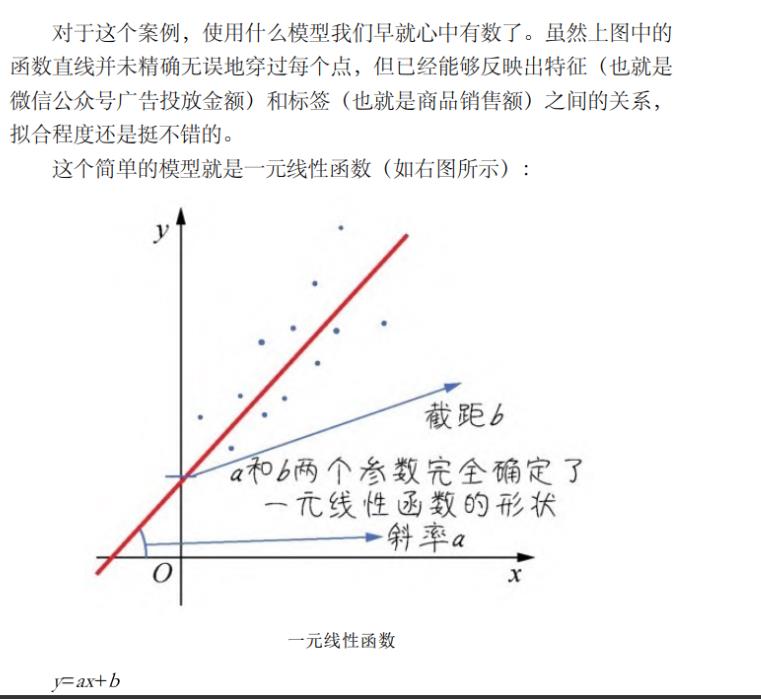
3.3.1 确定线性回归模型
-
其中,参数a的数学含义是直线的斜率(陡峭程度),b则是截距(与y轴相交的位置)。
-
在机器学习中,会稍微修改一下参数的代号,把模型表述为:y=wx+ b
-
此处,方程式中的a变成了w,在机器学习中,这个参数代表权重。因为在多元变量(多特征)的情况下,一个特征对应的w参数值越大,就表示权重越大。而参数b,在机器学习中称为偏置。
不要小看这个简单的线性函数,在后续的机器学习过程中,此函数会作为一个基本运算单元反复地发挥威力
其他很多资料写的 θ 0 、 θ 1 \\theta_0 、 \\theta_1 θ0、θ1 和这里的 w 、 b 其实是一回事儿
使用 w 和 b 来表示这些参数会使它们的意义更清晰一些: weight是权重, bias是偏置, 各取首字母
-
3.3.2 假设(预测)函数–h(x)
-
先来看一个与线性函数稍有差别的方程式 : y’=wx+b
-
也可以写成 :h (x)=wx+b
-
其中,需要注意以下两点
-
y’指的是所预测出的标签,读作y帽(y-hat)或y撇。
-
h(x)就是机器学习所得到的函数模型,它能根据输入的特征进行标签的预测
- 我们把它称为假设函数,英文是hypothesis function(所以选用首字母h作为函数符号)

-
-
-
所以,机器学习的具体目标就是确定假设函数h(x),也就是要确定w和b
- 确定b,也就是y轴截距,这里称为偏置,有些机器学习文档中, 称它为 w 0 w_0 w0(或 θ 0 θ_0 θ0)。
- 确定w,也就是斜率,这里称为特征x的权重,有些机器学习文档 中,称它为 w 1 w_1 w1(或 θ 1 θ_1 θ1)。 一旦找到了参数w和b的值,整个函数模型也就被确定了。那么这些参数w和b的具体值怎么得到呢?👇
3.3.3 损失(误差)函数–L(w,b)
-
在继续寻找最优参数之前,需要先介绍损失和损失函数。
-
如果现在已经有了一个假设函数,就可以进行标签的预测了。那么,怎样才能够量化这个模型是不是足够好?
- 比如,一个模型是3x+5, 另一个是100x+1,怎样评估哪一个更好? 这里就需要引入**损失(loss)**这个概念
-
损失,是对糟糕预测的惩罚。损失也就是误差,也称为成本 (cost)或代价。名字虽多,但都是一个意思,也就是当前预测值和真实值之间的差距的体现。它是一个数值,表示对于单个样本而言模型预测的准确程度。
- 如果模型的预测完全准确,则损失为0
- 如果不准确, 就有损失。在机器学习中,我们追求的当然是比较小的损失
-
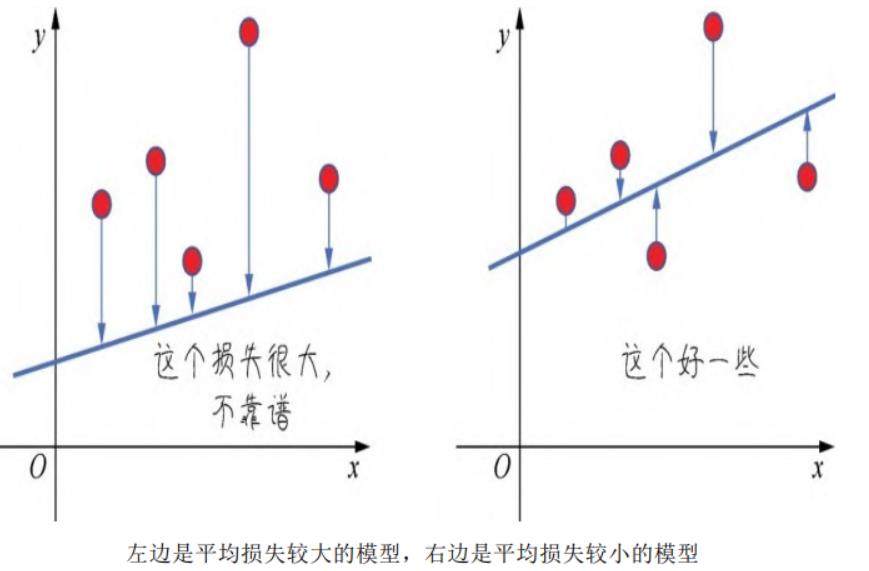
不过,模型好不好还不能仅看单个样本,而是要针对所有数据样本找到一组平均损失“较小”的函数模型。样本的损失的大小,从几何意义上基本上可以理解为y和y’之间的几何距离。平均距离越大,说明误差越大,模型越离谱。如下图所示,左边模型所有数据点的平均损失很明显大过右边模型。
-
因此,针对每一组不同的参数,机器都会针对样本数据集算一次平均损失。计算平均损失是每一个机器学习项目的必要环节。
-
损失函数(loss function) L ( w , b ) L(w, b) L(w,b) 就是用来计算平均损失的
-
有些地方把损失函数记作 J ( θ ) J(\\theta) J(θ), 也叫代价函数、成本函数 ( cost function)。刚才说过, θ \\theta θ 就是 w 和 b, J ( θ ) J(\\theta) J(θ) 就是 L ( w , b ) L(w, b) L(w,b), 符号有别, 但意思相同。
-
这里要强调一下: 损失函数 L 是参数 w 和 b 的函数, 不是针对 x 的函 数。我们会有一种思维定势, 总觉得函数一定是表示 x 和 y 之间的关系。
-
现在需要换一个角度去思考问题, 暂时忘掉 x 和 y, 聚焦于参数。对于一个给定的数据集来说, 所有的特征和标签都是已经确定的, 那么此时损失值的大小就只随着参数 w 和 b 而变。也就是说, 现在 x 和 y 不再是变 量, 而是定值, 而 w 和 b 在损失函数中成为了变量。
这里书上讲的真棒哇!
-
-
计算数据集的平均损失非常重要,简而言之就是:如果平均损失小,参数就好;如果平均损失大,模型或者参数就还要继续调整。 这个计算当前假设函数所造成的损失的过程,就是前面提到过的模型内部参数的评估的过程。
机器学习常用的一些损失函数
机器学习中的损失函数很多,主要包括以下几种。
-
用于回归的损失函数
- 均方误差(Mean Square Error, MSE)函数
- 也叫平方损失或L2损失函数误差
- 平均绝对误差(Mean Absolute Error, MAE)函数
- 也叫L1损失函数
- 平均偏差误差(mean bias error)函数
- 均方误差(Mean Square Error, MSE)函数
-
用于分类的损失函数
- 交叉熵损失(cross_entropy loss)函数
- 多分类SVM损失(hinge loss)函数
均方误差函数的实现过程MSE(Mean Square Error)
-
一般来说,选择最常用的损失函数就可以达到评估参数的目的。下面给出线性回归模型的常用损失函数—均方误差函数的实现过程。
-
首先,对于每一个样本,其预测值和真实值的差异为