Spark - OnYARN 模式搭建,并使用 ScalaJavaPython 三种语言测试
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark - OnYARN 模式搭建,并使用 ScalaJavaPython 三种语言测试相关的知识,希望对你有一定的参考价值。
一、SparkOnYarn搭建
安装前需要提前安装好 hadoop 环境,关于 HDFS 和 Yarn 集群的搭建可以参考下面我的博客:
下面是我 Hadoop 的安装结构
| 主机 | 规划设置主机名 | 角色 |
|---|---|---|
| 192.168.40.172 | node1 | NameNode、DataNode、ResourceManager、NodeManager |
| 192.168.40.173 | node2 | SecondaryNameNode、DataNode、NodeManager |
| 192.168.40.174 | node3 | DataNode、NodeManager |
开始前请确保 hadoop 已经成功启动起来。
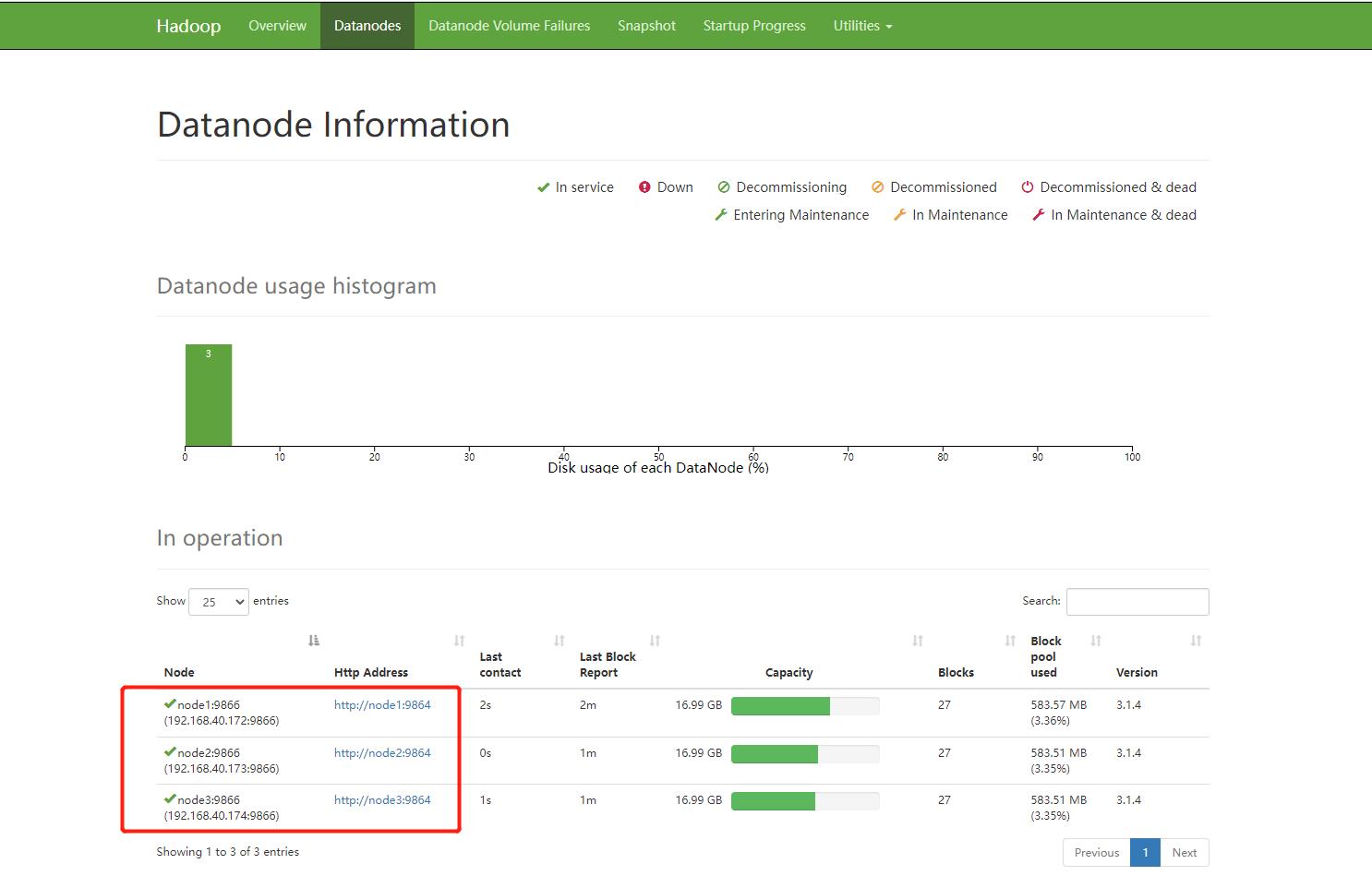
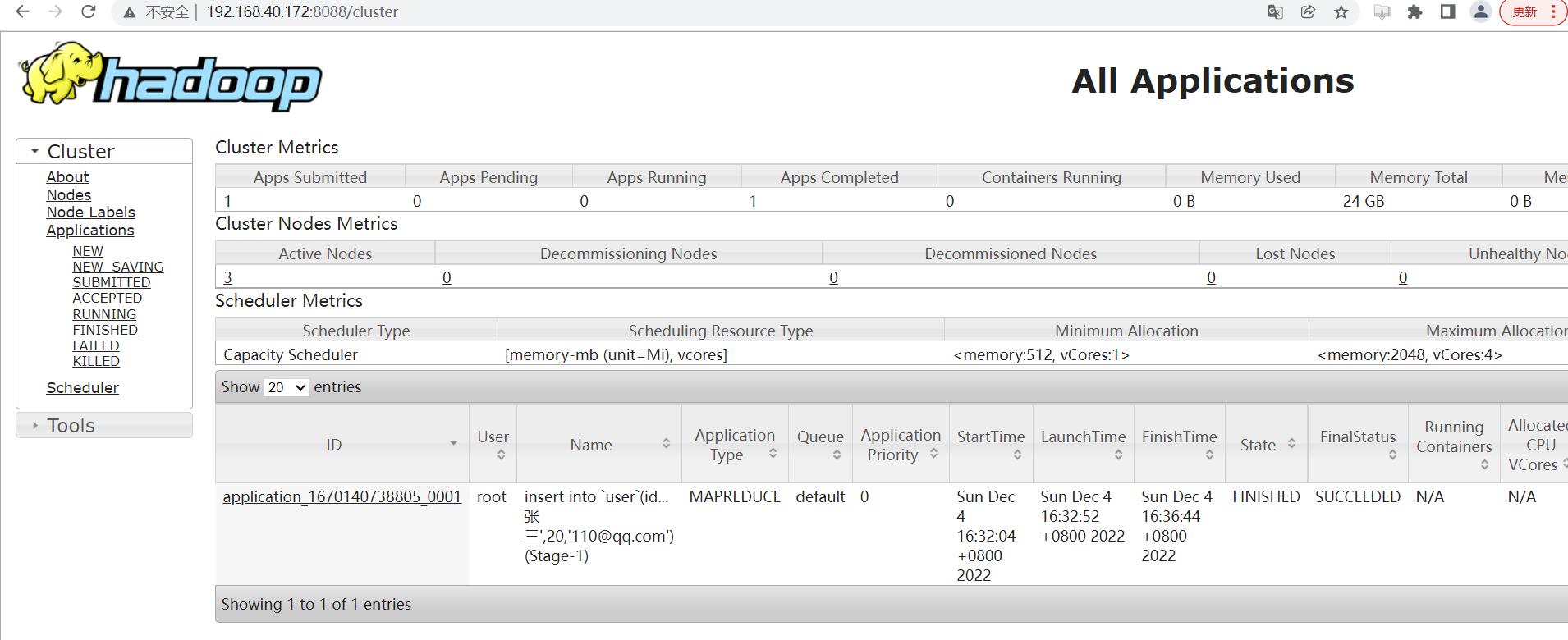
准备一台服务器,可以和 Hadoop 装在一台机子上,下面有需要读取 Hadoop 的配置,如果是台纯净的服务,需要将 Hadoop 的配置文件放上去。Yarn 需要配置历史服务器,如果没有配置通过修改下面文件开启:
修改 Hadoop 安装目录 etc/hadoop/yarn-site.xml 文件:
vim yarn-site.xml
添加下面配置:
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>

该需要同步到集群的其他节点:
scp /export/server/hadoop-3.1.4/etc/hadoop/yarn-site.xml root@node2:/export/server/hadoop-3.1.4/etc/hadoop/yarn-site.xml
scp /export/server/hadoop-3.1.4/etc/hadoop/yarn-site.xml root@node3:/export/server/hadoop-3.1.4/etc/hadoop/yarn-site.xml
重启 Hadoop 集群:
stop-all.sh
start-all.sh
下载 Spark 安装包,这里我用的 3.0.1 版本:
先将下载后的安装包上传至 node1 节点,解压安装包:
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz
进入到加压目录下的 conf 下,修改配置:
修改 spark-defaults.conf:
mv spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
添加内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address node1:18080
spark.yarn.jars hdfs://node1:8020/spark/jars/*
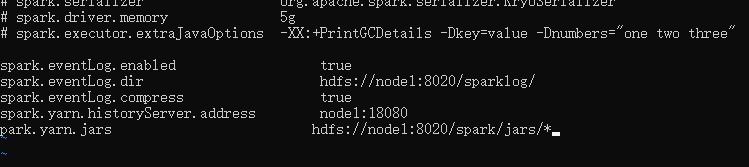
修改 spark-env.sh :
vi spark-env.sh
## 设置JAVA安装目录
JAVA_HOME=/usr/lib/jvm/java-1.8.0
## HADOOP软件配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需要
HADOOP_CONF_DIR=/export/server/hadoop-3.1.4/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop-3.1.4/etc/hadoop
## 配置spark历史日志存储地址
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
这里的 sparklog 需要手动创建:
hadoop fs -mkdir -p /sparklog
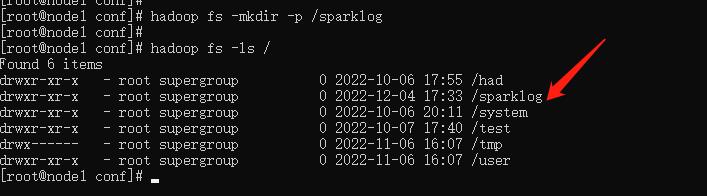
修改日志的级别:
mv log4j.properties.template log4j.properties
vi log4j.properties

配置Spark 的依赖 jar 包,将 jar 都上传到 HDFS 中:
在HDFS上创建存储spark相关jar包的目录:
hadoop fs -mkdir -p /spark/jars/
上传$SPARK_HOME/jars所有jar包到HDFS:
hadoop fs -put /export/spark/spark-3.0.1-bin-hadoop2.7/jars/* /spark/jars/
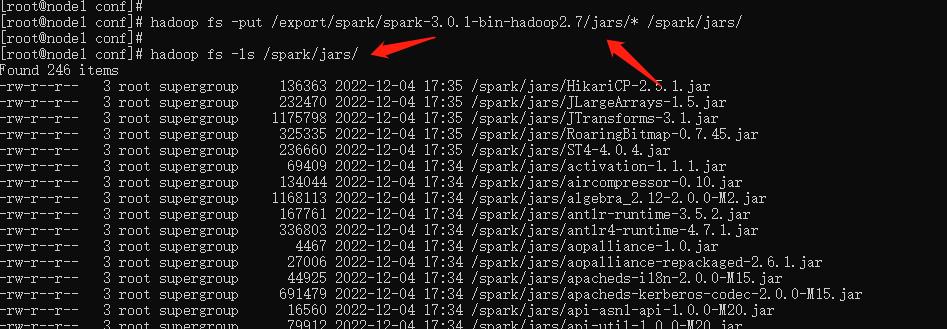
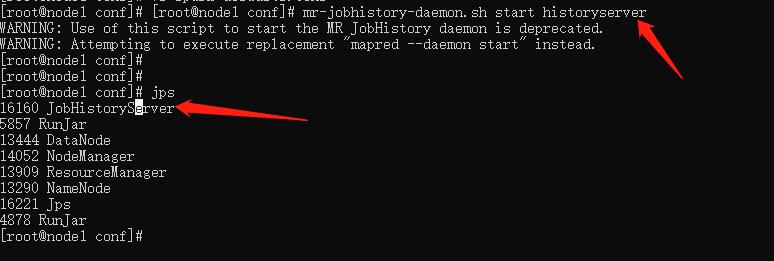
启动MRHistoryServer服务,在node1执行命令
mr-jobhistory-daemon.sh start historyserver
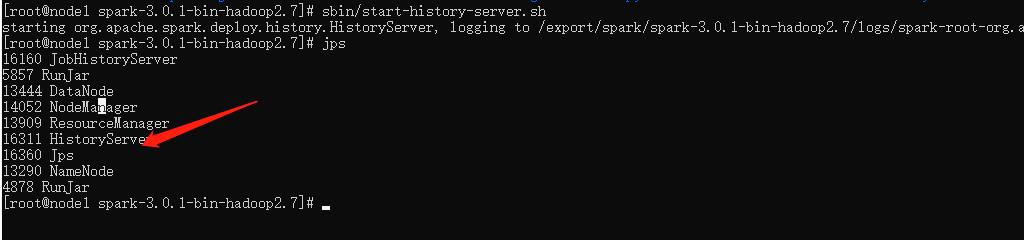
进入到 Spark 解压目录,启动Spark HistoryServer服务:
sbin/start-history-server.sh
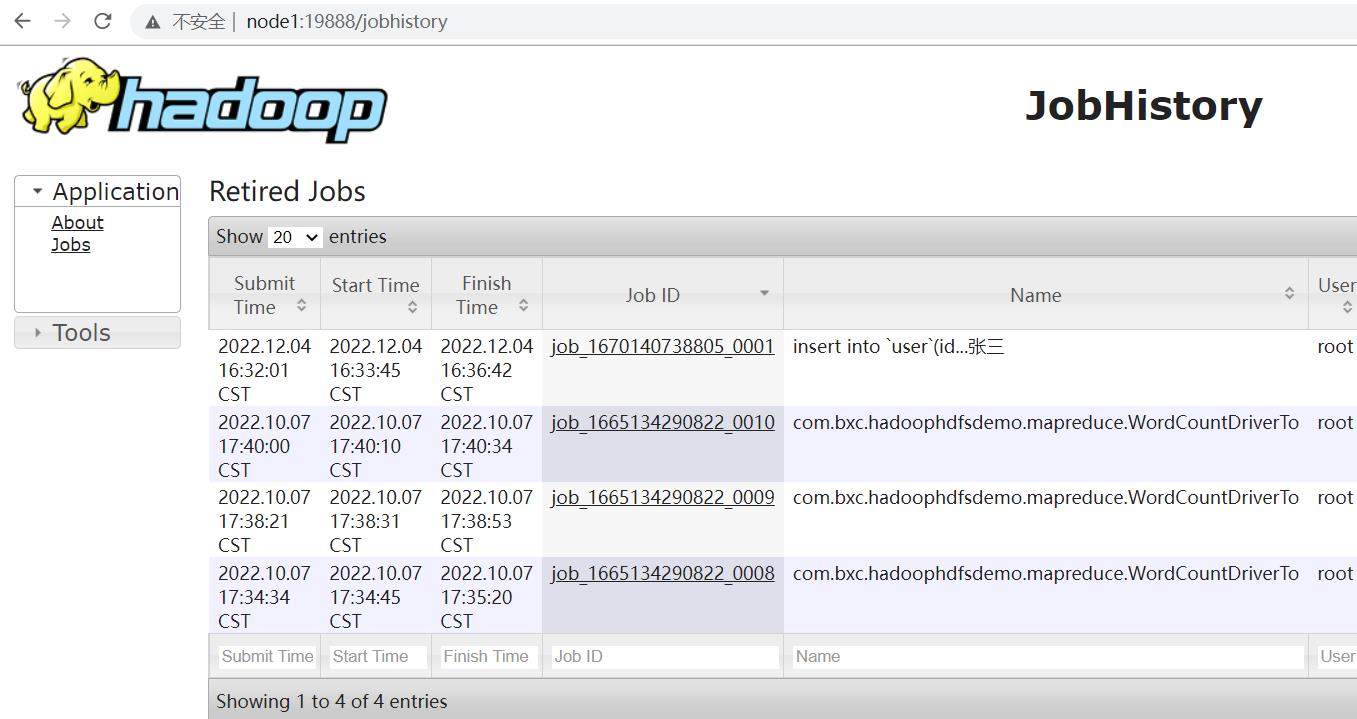
MRHistoryServer服务WEB UI页面:
Spark HistoryServer服务WEB UI页面:

二、使用三种语言测试环境
1. java 和 Scala 项目
创建一个普通的Maven项目,在 pom 中添加 Scala 和 Spark 的依赖:
<!--依赖Scala语言-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.11</version>
</dependency>
<!--SparkCore依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.1</version>
</dependency>
在 main 下面创建 scala 包,专门存放 scala 程序,java 下专门存放 java 程序:
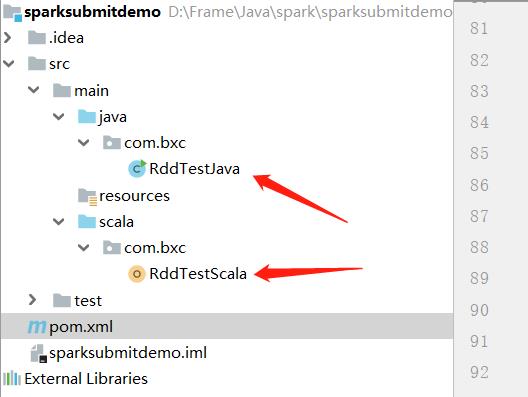
Scala 测试程序
object RddTestScala
def main(args: Array[String]): Unit =
val conf = new SparkConf().setAppName("spark")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val texts= sc.parallelize(Seq("abc", "abc", "ff", "ee", "ff"))
val counts = texts.map((_,1)).reduceByKey(_ + _)
println(counts.collectAsMap())
Java 测试程序
public class RddTestJava
public static void main(String[] args)
SparkConf conf = new SparkConf().setAppName("spark");
JavaSparkContext sc = new JavaSparkContext(conf);
sc.setLogLevel("WARN");
JavaRDD<String> texts= sc.parallelize(Arrays.asList("abc", "abc", "ff", "ee", "ff"));
JavaPairRDD<String, Integer> counts = texts.mapToPair(s -> new Tuple2<>(s, 1)).reduceByKey(Integer::sum);
System.out.println(counts.collectAsMap());
由于默认情况下使用 maven 编译不会编译 scala 程序,在 build 中添加 scala 的插件:
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<plugins>
<!-- 指定编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>$project.build.directory/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.bxc.RddTestJava</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
打成 jar 包:
mvn clean package
将打包后的jar包上传至 node1 节点,进到 Spark 解压目录下:
运行 Scala 脚本
bin/spark-submit \\
--master yarn \\
--deploy-mode client \\
--driver-memory 512m \\
--driver-cores 1 \\
--executor-memory 512m \\
--num-executors 1 \\
--executor-cores 1 \\
--class com.bxc.RddTestScala \\
/export/spark/spark-submit-demo-1.0-SNAPSHOT.jar

运行 Java 脚本
bin/spark-submit \\
--master yarn \\
--deploy-mode client \\
--driver-memory 512m \\
--driver-cores 1 \\
--executor-memory 512m \\
--num-executors 1 \\
--executor-cores 1 \\
--class com.bxc.RddTestJava \\
/export/spark/spark-submit-demo-1.0-SNAPSHOT.jar

2. Python项目
编写 Python 脚本:
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName('spark')
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
texts = sc.parallelize(["abc", "abc", "ff", "ee", "ff"])
counts = texts.map(lambda s:(s, 1)).reduceByKey(lambda v1,v2:v1+v2)
print(counts.collectAsMap())
将脚本上传至 node1 节点,,进到 Spark 解压目录下:
bin/spark-submit \\
--master yarn \\
--deploy-mode client \\
--driver-memory 512m \\
--driver-cores 1 \\
--executor-memory 512m \\
--num-executors 1 \\
--executor-cores 1 \\
/export/spark/RddTestPy.py

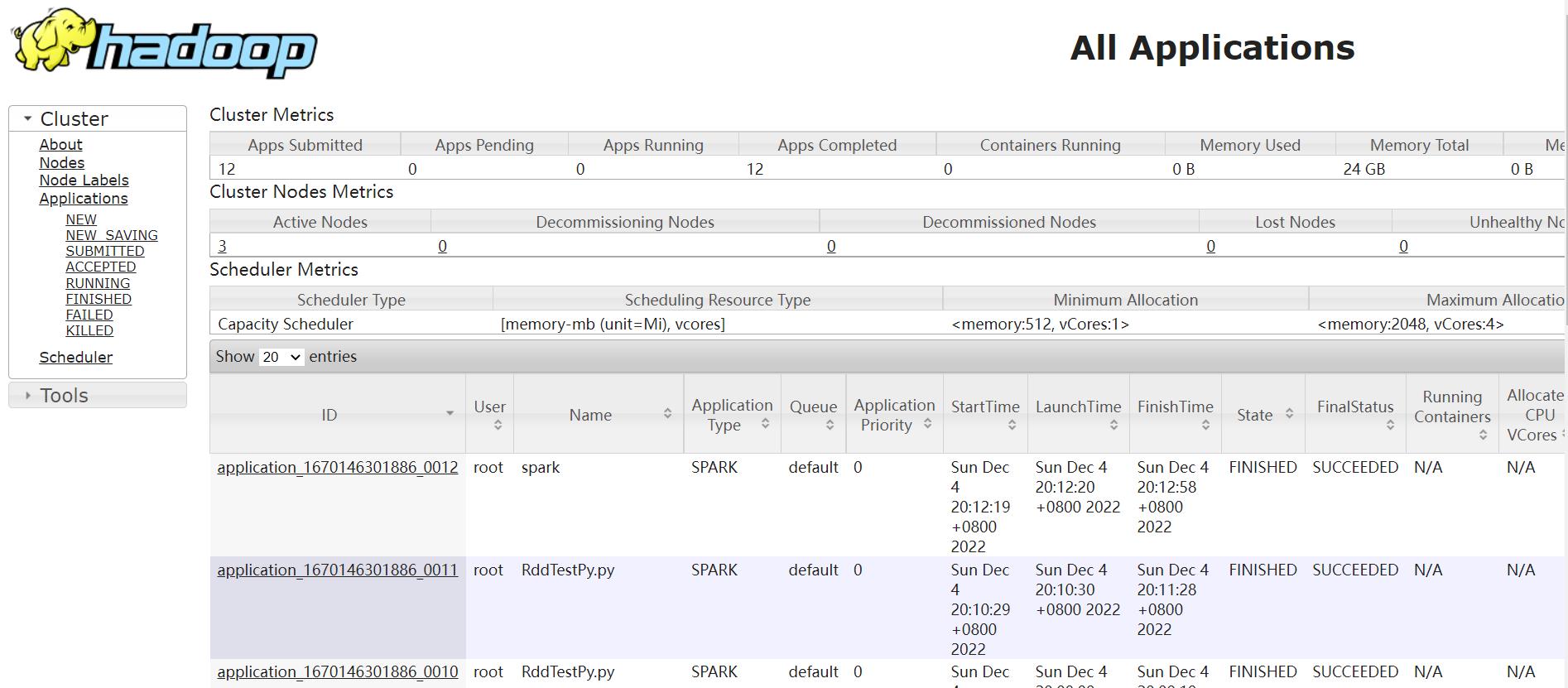
查看web界面:
三、YARN 模式下的两种运行模式
1. client

例如:
bin/spark-submit \\
--master client\\
--deploy-mode cluster \\
--driver-memory 512m \\
--driver-cores 1 \\
--executor-memory 512m \\
--num-executors 1 \\
--executor-cores 1 \\
--class com.bxc.RddTestJava \\
/export/spark/spark-submit-demo-1.0-SNAPSHOT.jar
2. cluster
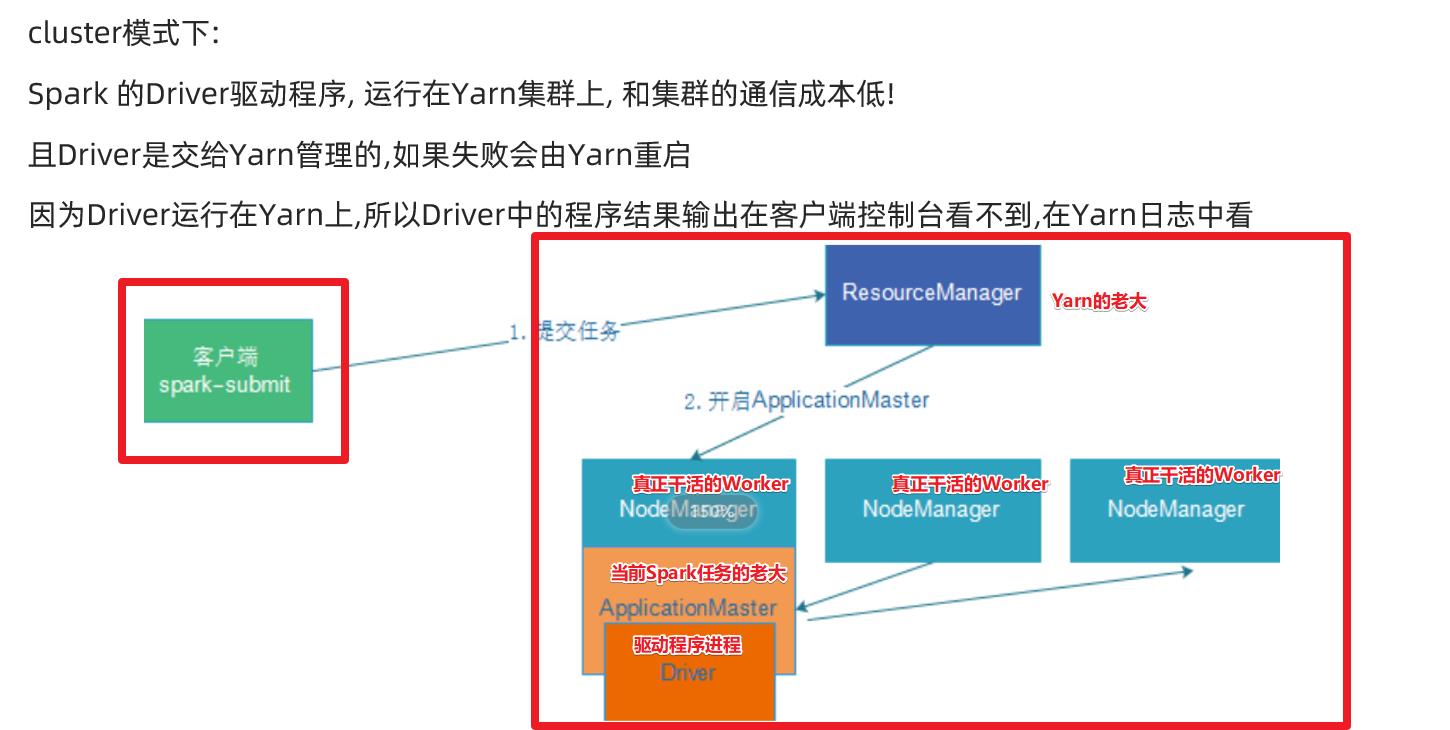
例如:
bin/spark-submit \\
--master cluster\\
--deploy-mode cluster \\
--driver-memory 512m \\
--driver-cores 1 \\
--executor-memory 512m \\
--num-executors 1 \\
--executor-cores 1 \\
--class com.bxc.RddTestJava \\
/export/spark/spark-submit-demo-1.0-SNAPSHOT.jar
以上是关于Spark - OnYARN 模式搭建,并使用 ScalaJavaPython 三种语言测试的主要内容,如果未能解决你的问题,请参考以下文章