Metabase 使用指南
Posted FesonX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Metabase 使用指南相关的知识,希望对你有一定的参考价值。

一. 为什么从 ELK 迁移到 Metabase + OLAP
1.1 ELK 的问题
- 扩展性不强:Kibana 只能应用在 ElasticSearch 上
- 管理不便:在阿里云等平台,一个 ElasticSearch 集群对应一个 Kibana,难以统一管理
- 开发成本:无法将图表嵌入到其他应用中,需要二次开发图形展示
- 性能一般:ElasticSearch 擅长全文搜索,在数据分析功能上的性能不如 OLAP 数据库,并且存在一些限制,例如去重的精度不足,上限只有40000(默认准确度保证仅有3000)
- 运维成本:抛开搜索优化,仍需要维护好一套索引生命周期管理、索引模板,以及应对字段变更时的 reindex。此外,相同数据量下,Elastic 的压缩比不如列式数据库,内存占用也更高,相应的成本也要高出不少。
1.2 Metabase + 其他DB 的优势
- 扩展性: JDBC + Clojure multi-method 实现 Driver 扩展,即使开发新 Driver 的成本也不高。
- 统一入口: 使用相同后端存储的 Metabase 可以同时管理多个不同的 DB
- 开发成本: 在 Metabase 开发的 Dashboard 可以直接嵌套到其他前端应用,并且维护有 JWT 认证。其他人员开发的 Question、Model、Metric 可以相互引用。
至于性能和运维成本,则由所选择的后端 DB 所决定。Metabase 本身不需要进行多复杂的维护,单个 DB 故障并不会引起 Metabase 崩溃。
 Metabase
Metabase
二. 提问
2.1 数据源
数据源有三种
-
Raw Data,即源数据,任一数据库表都是源数据。可以直接点开任一 raw 表以表格方式查看数据。
 示例订单数据
示例订单数据
Question,问题,已存储的问题也可以成为数据源,例如这样一个问题:查询过去一年内每天不同来源的消息量,我们可以基于这个问题构建一个过去6个月每周的消息量问题。
Model,模型,可以由 Question 或 SQL 提问后转化,Model 某种程度上是一种物化视图,物化不存储数据,通常不直接用来可视化。例如有个人信息和订单两张实体表,可以把用户名和用户常买的物品、购买时间等组合为一个新的模型。
2.2 构建问题
2.2.1 组成部分
- Data 部分即前面的数据源
- 可以选择需要的列,在查询数据时减少干扰,提升速度。
- 可以 JOIN 三种数据源,但必须在同一个数据库,当然,也要是同一种数据库。也有例外,ClickHouse 可以使用 mysql、Postgres、MongoDB 等外表。在 Metabase 上展示为同一种数据库,但实际类型不同。 JOIN 的不同模式(
LEFT JOIN、RIGHT JOIN)可以点击图标切换。 - Custom Column 类似于数据库函数的接口抽象,不是所有驱动都支持该实现。一般用在统计阶段。
- (可选)Filter 部分即过滤器,选择合适的 Filter 可以提速,也可以排除无关的结果。在数据表格预览时可以直接在列上方过滤数据,例如这里只看有折扣的客单价:
 过滤数据
过滤数据
 过滤效果
过滤效果
- (可选)Summarize 部分即统计相关,需要结合分组操作。常用的例如 sum、count,如果需要构建更复杂的计算,可以使用 Custom Column,包含其他的数学函数和字符串函数,未必所有函数都可用
 比较有无折扣的商品总价
比较有无折扣的商品总价
- (可选)Sort 和 Limit 即 排序和返回数量,排序在图表上的展示区别不大,最好限制返回的数量(默认 10000)特别是在源表上。
2.2.2 调试 Question
每个阶段都可以点击小三角形预览数据
- 在最终结果无法展示时,可以逐个阶段预览调试
- 在 JOIN 数据时,可以检查是否 JOIN 模式存在错误,导致结果缺少或者重复
如果仍然无法解决问题,可以点击右边的 SQL 语句按钮,由开发同学协助调试。
2.3 使用 SQL 构建问题
用 SQL 构建问题除了可以自由选择函数外,也可以使用变量作为过滤器。
使用变量的两个关键语法是 variable 和 [[variable]] ,第一个为一般变量,第二个为可选变量,使用变量时不需要使用 where table.a = variable 方式,直接用 where = variable 使用可选变量时,不需要用 AND 连接。
有点绕?
看看例子:这是一个统计不同 HTTP 方法的 SQL,将 create_time 和 method 作为过滤器,其中 create_time 是可选变量。
SELECT `inner_api_log`.`method` AS `method`,
toDate(`inner_api_log`.`create_time`) AS `create_time`, count(*) AS `count`
FROM `inner_api_log` where method [[create_time]]
GROUP BY `inner_api_log`.`method`, toDate(`inner_api_log`.`create_time`)
ORDER BY `inner_api_log`.`method` ASC, toDate(`inner_api_log`.`create_time`) ASC过滤器可以进一步设置,例如作为下拉框(需要映射原始表,且差异值有限)或者作为搜索框等等。
 SQL变量
SQL变量
- 要进一步分析,将 SQL 保存的问题作为数据源再次引用即可。
- 使用变量的 SQL 不可作为 Model 使用
2.4 选择可视化图表
点击可视化图形选择面板选择可用的图表,部分图表未必适合当前数据,可能点击后仍不可用。
 可视化界面操作
可视化界面操作
 部分图表未必适用当前数据
部分图表未必适用当前数据
2.5 设置图表
2.5.1 通用设置
点击 Question 显示通用菜单,可以添加描述、添加到 Dashboard、移动或归档等。
左下角的 History 按钮可以查看版本历史,每次保存或者回滚均会产生一条版本记录。

2.5.2 折线、柱状图
- Data:即数据源,用来选择展示的数据。数据旁边的设置按钮,可以用来格式化数据,例如数字的展示可以设置小数点,或者表示为货币,日期的格式等等
- Display:即展示效果,例如设置数据的颜色,设置目标线
- Axes:刻度,用来设置数据的呈现方式,例如大小分布很不均匀的数据(通常数据中的最大数字比最小数字大数百甚至数千倍)可以使用对数刻度(Log)或者幂次刻度(Power),遗憾的是,Metabase 不能选择对数的底数大小。
下图是分布不均的典型案例,由于某种数据暴涨,掩盖了其他数据的趋势展示,改为对数刻度就可以很好地展示:
 线性刻度
线性刻度
 对数刻度
对数刻度
Labels:标签,或称图例标签(Legend Label),可以添加备注
可视化界面(右侧):除了点击图例筛选、鼠标悬停查看具体值之外,还可以点击图形上的点,弹出的窗口可以做进一步值的筛选、或者分组操作。例如原问题是按 Category 分组,这里可以进一步按时间查看趋势
 快速操作数据
快速操作数据
当 X 轴为时间轴,鼠标可以选中区间查看对应时间范围的数据分布。
 选中时间范围
选中时间范围
2.5.3 表格
 表格设置面板
表格设置面板
左侧设置面板:
- Columns:列属性,点击设置按钮设置列名,对于数值类型,支持以迷你条形图方式展示,对于时间类型,支持格式化时间。
 列格式化
列格式化
- Conditional Formating:即条件格式化。可以对满足条件的值高亮显示,高亮支持单色或颜色范围展示
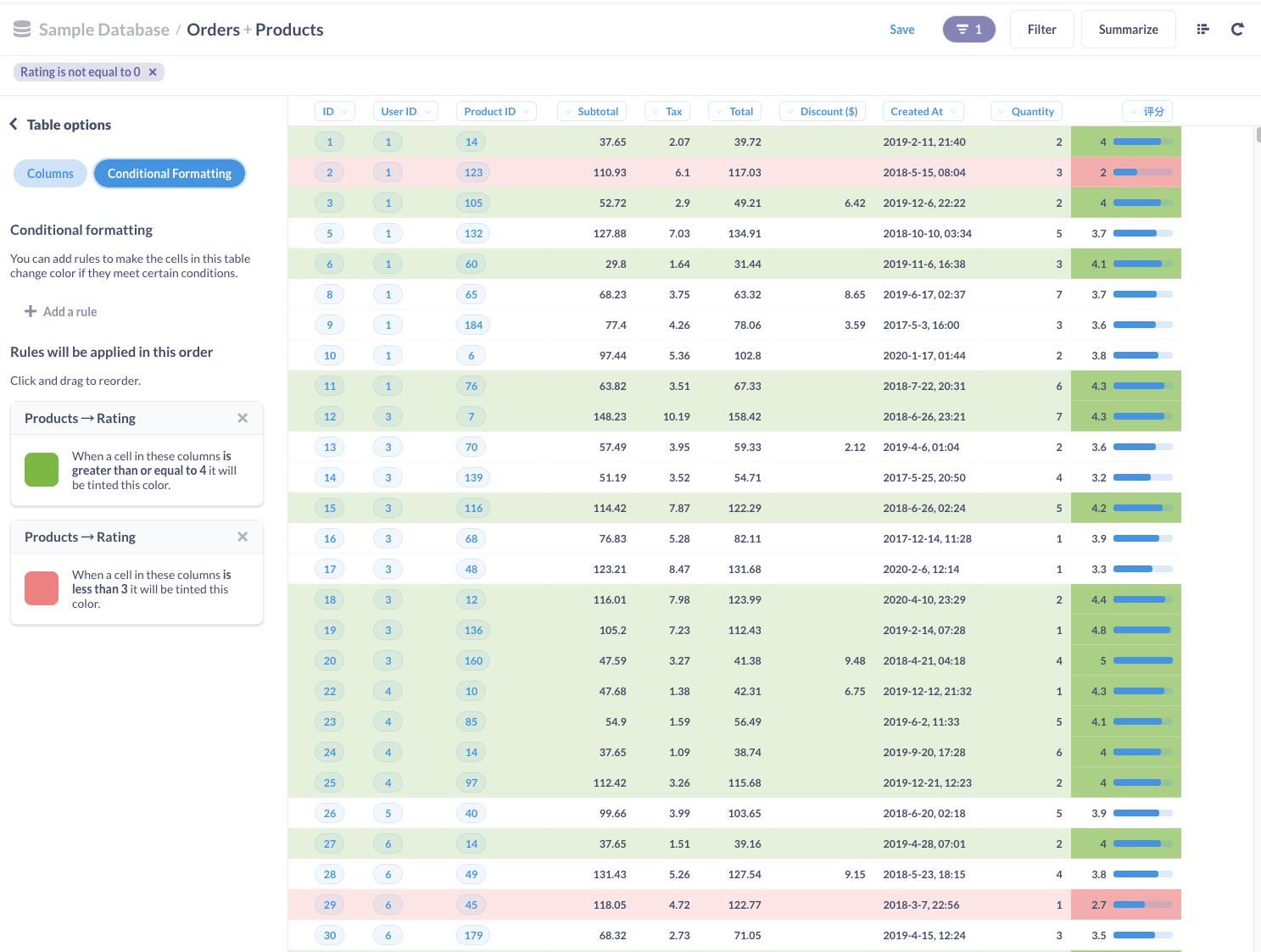 条件格式化
条件格式化
 颜色范围高亮
颜色范围高亮
右侧展示面板
-
点击列名弹出快速操作,可以进行排序、过滤、或进一步统计
 快速操作表格
快速操作表格
- 点击具体值弹出快速筛选窗口
- 右下角支持下载源数据到本地(JSON、Excel 或 CSV)如设置提醒,则会定时接收到该表格的邮件。
三. Dashboard 管理
3.1 编辑 Dashboard
- 右上角三个按钮分别可以添加已保存的问题、添加文本(Markdown)和添加过滤器
- 鼠标悬停在任一组件上,可以移动位置,组件右下角可以拖动改变大小
- 非编辑模式,点击任一问题标题,进入到相应问题详情

- 对于地图类型,支持设置默认展示区域

Tips: 默认提供了世界地图和美国地图,如果不能满足你,可以在 AdminSetting 添加其他 Geojson 格式的地图。
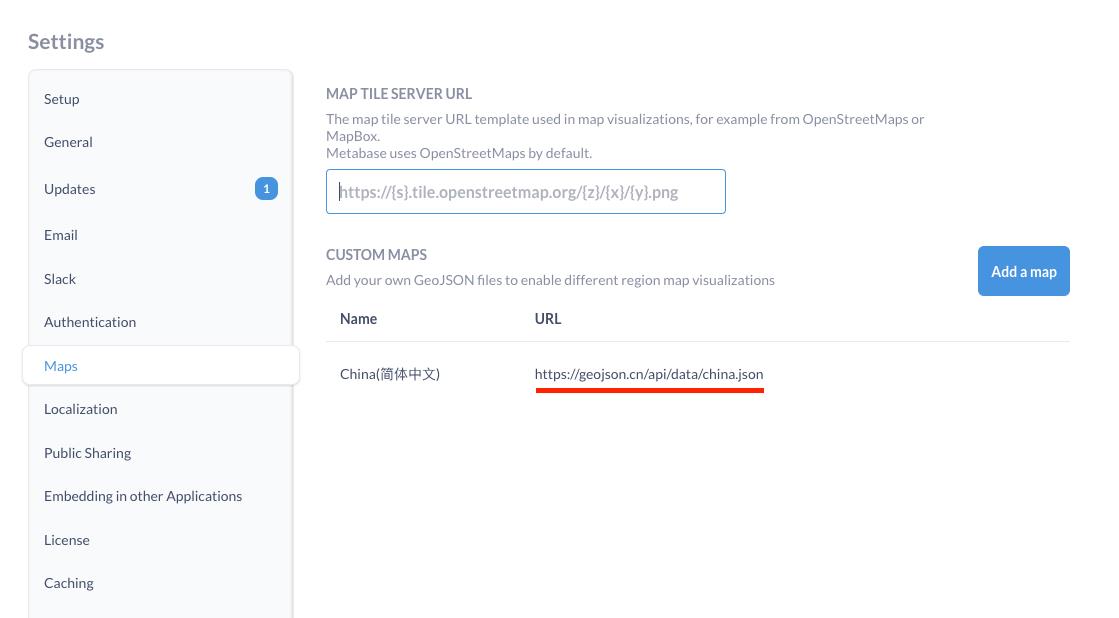 添加自定义地图
添加自定义地图
3.2 过滤器
过滤器支持几种不同类型
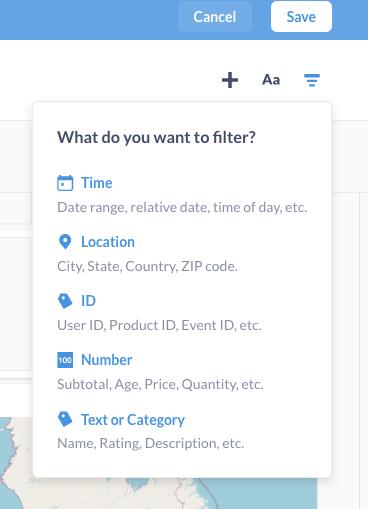 过滤器类型
过滤器类型
添加过滤器后会固定在 Dashboard 上方,不随页面移动(Binding Top),拖动过滤器改变位置
- 设置联动的图表
点击要设置的过滤器,然后在图表上选择联动的列,选择过滤条件就会联动设置的图表。如下图所示,过去 30 天的过滤条件会应用在四个图表上。 - (可选)设置默认的过滤选项、过滤器名称
 过滤器设置
过滤器设置
- 联动过滤器,一般用在多级分组上,例如省-市等多级分类,选择大一级分类会影响子分类选项。
 选择州会影响城市级别过滤器选项
选择州会影响城市级别过滤器选项
3.3 可视化
如果修改图表的标题、微调展示的颜色等操作,需要回到问题页修改再保存,会使操作变得繁琐,并增加不必要的新问题。
Dashboard 编辑模式下,支持在不修改图表展示类型的情况下,修改该类型图表几乎所有参数,例如下图所示,仅数据源不支持修改。
点击 reset to default 会恢复到原问题的设置。
 Dashboard编辑模式下的图表设置页
Dashboard编辑模式下的图表设置页
3.4 叠加图表
在需要横向对比的场景,有时因为条件难以用单个 SQL 表达。
可以考虑下面的方式:
- 分别创建若干个问题。如果需要永久保存,可以再添加一个问题,JOIN 几个问题实现图表叠加。如果需要合并,查看 SQL 再转化为新的问题即可。
 横向对比 2020 及 2019 一季度销售额
横向对比 2020 及 2019 一季度销售额
- 若不需要,在 Dashboard 编辑模式下,添加 Add Series,搜索已保存的问题,如果问题存在感叹号,则可能不兼容当前的图表。叠加的图表同样支持在编辑模式下分别设置图表。
 添加图表
添加图表
 叠加图表下的设置页
叠加图表下的设置页
3.5 点击行为
- 跳转到自定义链接:用来链接到外部的同一网址,或者跳转到带参数的指定详情页等。也可以跳转到指定的 Dashboard 或者问题页。
例如,在地图图表上添加搜索关键词,点击跳转到 Google 搜索页:
 跳转外部链接示例
跳转外部链接示例
- 联动页面过滤器:下拉过滤器可能不够直观,下面的地图例子,当点击对应州的图形时,会同步改变州(State)过滤器,其他引用的图表就会一起更新。
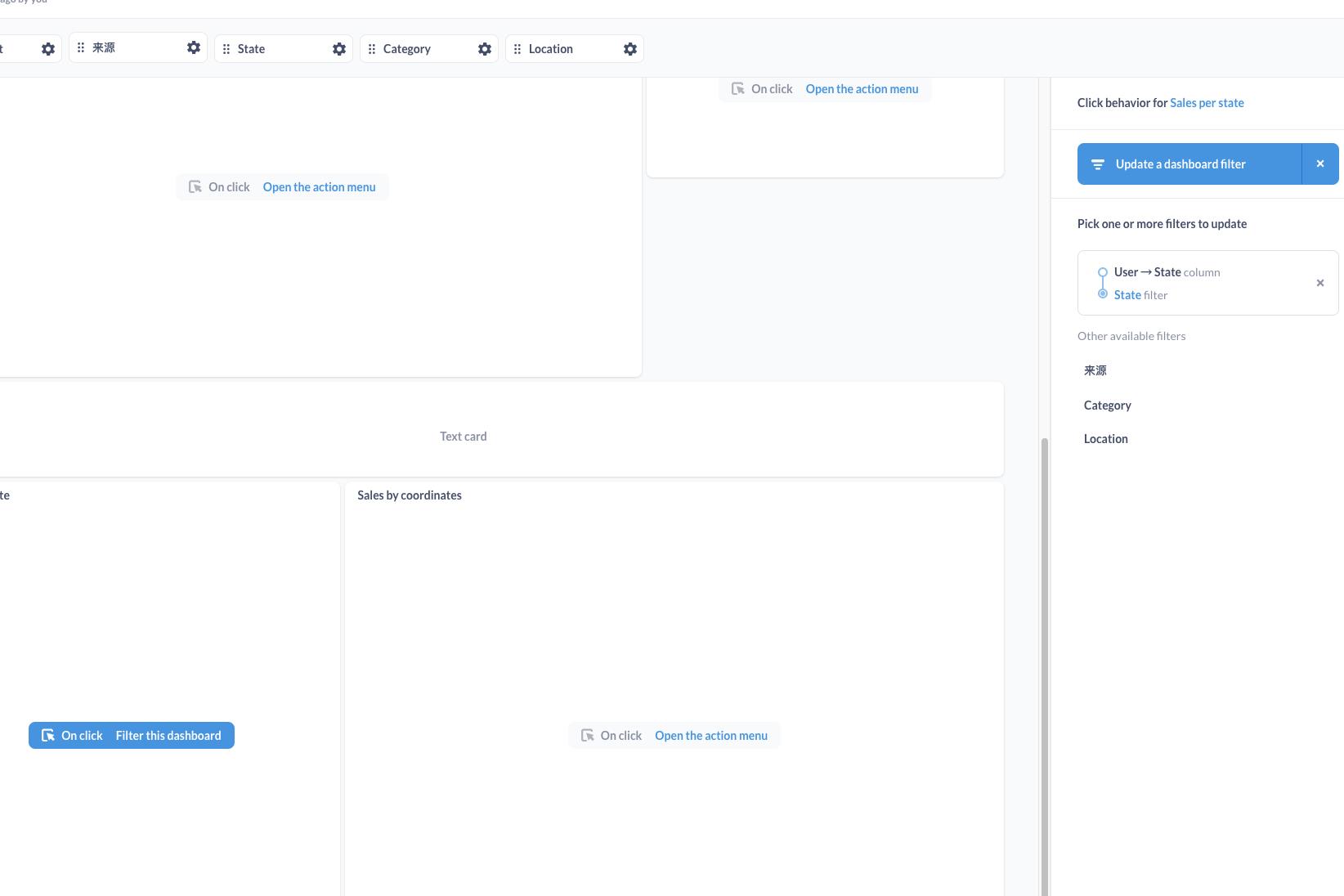 联动过滤器
联动过滤器
四. 管理数据
4.1 管理数据源
添加数据源时,管理员需要做好以下操作
- 限制数据源权限,设置好组员的查看和编辑权
- 隐藏不必要的数据,例如ClickHouse 的 Kafka Engine 表、导入详情表的物化表等对数据分析人员没有意义。
一些数据列只提供给开发人员调试,对其他人员没有意义的,同样也要隐藏。或者某些列不适合统计,聚合可能导致崩溃。 数据可见性.png
数据可见性.png
- 更改列属性,Metabase 有时存在列的属性推断错误,例如某些列我们希望它有下拉过滤,但被推断为其他类型,可以手动修改,再重新扫描该列。
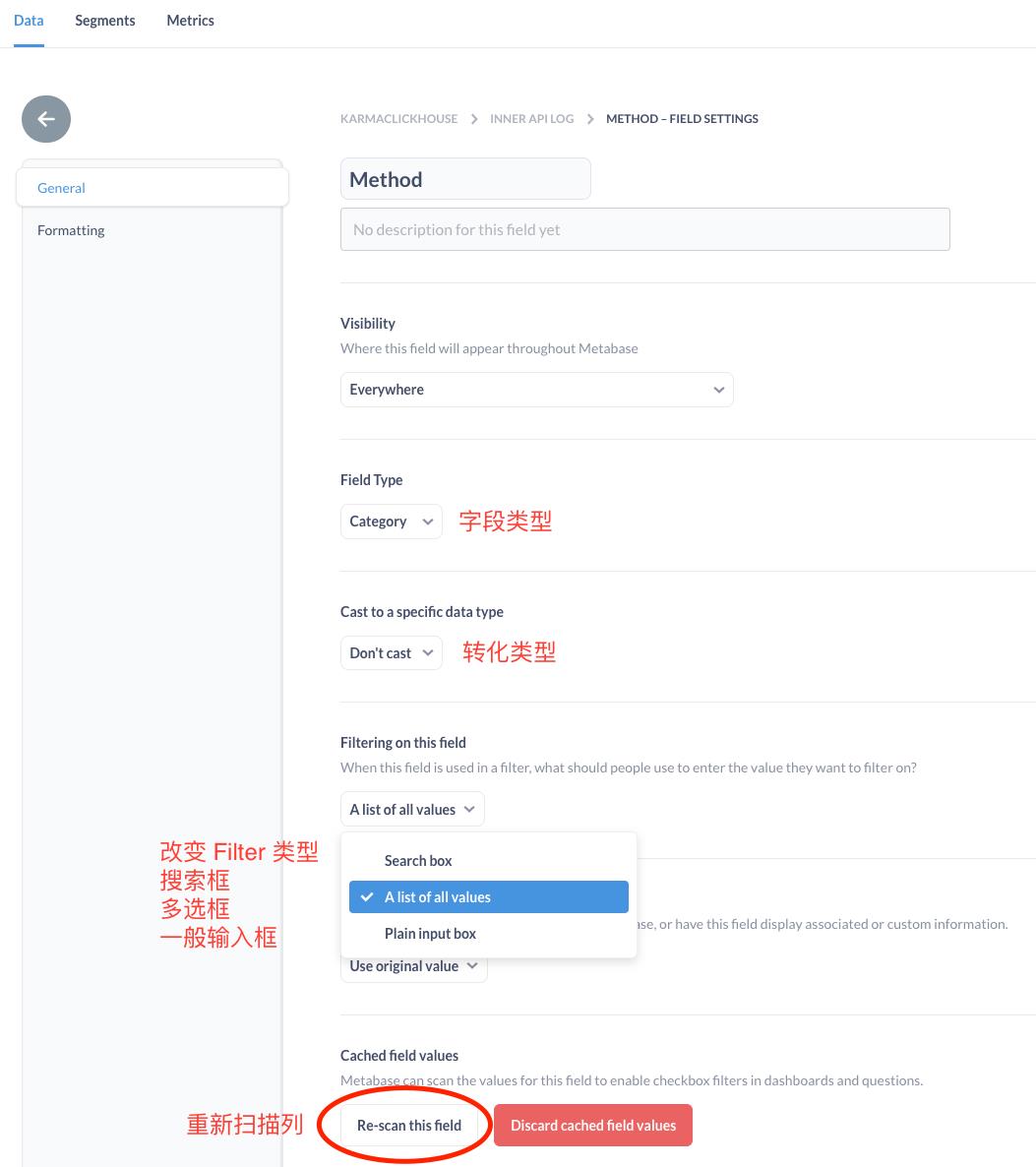 更改列属性
更改列属性
4.2 创建模型(Model)
同样是由表延展的数据,模型具有一定实体意义,通常不直接用来可视化,而是作为源数据,方便复用。
模型拥有和源数据一样丰富的列属性设置,这里不再赘述。
以上是关于Metabase 使用指南的主要内容,如果未能解决你的问题,请参考以下文章