从Opencv之图像直方图源码,探讨高性能计算设计思想
Posted Briwisdom
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Opencv之图像直方图源码,探讨高性能计算设计思想相关的知识,希望对你有一定的参考价值。
前言
纸上得来终觉浅,绝知此事要躬行。学会算法的理论很重要,但是把理论高效的实现也是需要一点点练习的。
图像直方图的理论很简单,就是把一个图像的像素区间划分为几个子区间,然后统计图像中的像素包含在子区间内的个数。这里,我们可以很容易想到,图像每个像素之间对结果的影响是独立的,所以,代码实现时候可以考虑并行化设计。
- 输入:image[h][w], bins, low, hign
- 输出: hist[bins]
Opencv的实现
opencv的实现流程,以uint8编码的图像为例
1,建立0-255到bins子区间的映射table。
即table[256], index是0-255, table[index]是在histogram[bins]中的index。
opencv建立table的接口函数
static void calcHistLookupTables_8u( const Mat& hist,
const SparseMat& shist,
int dims, const float** ranges,
const double* uniranges,
bool uniform, bool issparse,
vector<size_t>& _tab )
关键逻辑代码:
double t = bins/(high - low);
double a = t
double b = -t*low
for (int j=low; j<high; j++)
int idx =cvFloor( j*a +b);
table[j-low]=idx;
2,统计图像上0-255各像素值对应的个数。
opencv每次统计四个相邻位置的像素,好像为利用了CPU流水线加速的原理,即同一指令,不同空间可以并行执行。
opencv接口函数:
static void calcHist_8u( vector<uchar*>& _ptrs,
const vector<int>& _deltas,
Size imsize, Mat& hist, int dims,
const float** _ranges,
const double* _uniranges, bool uniform )
关键逻辑代码:
int matH[256] = 0, ;
for( x = 0; x <= imsize.width - 4; x += 4 )
int t0 = p0[x], t1 = p0[x+1];
matH[t0]++; matH[t1]++;
t0 = p0[x+2]; t1 = p0[x+3];
matH[t0]++; matH[t1]++;
p0 += x;
for( ; x < imsize.width; x++, p0 += step)
matH[*p0]++;3,合并matH和table,得到最终hist的输出。
OUT_OF_RANGE =bins;
uchar* H = hist.data;
for(int i = 0; i < 256; i++ )
size_t hidx = tab[i];
if( hidx < OUT_OF_RANGE )
*(int*)(H + hidx) += matH[i];
整体流程关系:
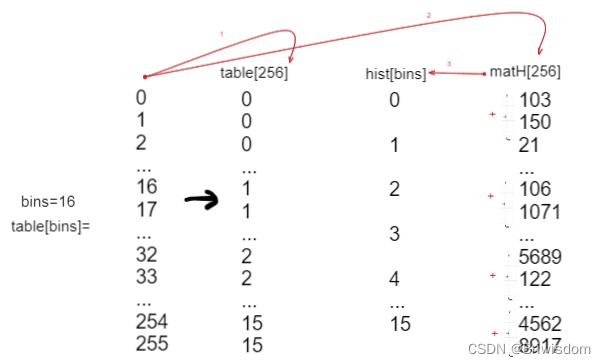
设计思路探讨
1,为什么要拆分成三步完成呢?这样的时间复杂度=O(256+256+h*w)
在遍历一次图像时候,为什么不同时完成hist的统计呢?可能opencv的映射查表用时更短,拆分步骤中1,2步可以同时完成。
for i in range(Height):
for j in range(width):
scale=bins/(high-low)
index=image[i][i]*scale
hist[index]+=12,在实现遍历图像,每个点对结果的影响又是独立的,那么软件层面如何进行并行化加速?
是不是能够分成多个线程读写image,在读取了image的像素值后,要对hist[pixes]或者matH[pixes]同一位置写数时候,加一个锁保护,即同一位置一次只能一个线程写数,只能串行,不能并行。
以上是关于从Opencv之图像直方图源码,探讨高性能计算设计思想的主要内容,如果未能解决你的问题,请参考以下文章