NLP技术:基于PCFG的CYK算法统计句法分析
Posted 陆海潘江小C
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP技术:基于PCFG的CYK算法统计句法分析相关的知识,希望对你有一定的参考价值。
目录
一、认识句法分析
首先,了解一下句法分析到底是什么意思?是做什么事情呢?顾名思义,感觉是学习英语时候讲的各种句法语法。没错!这里就是把分析过程交给计算机处理,让它分析一个句子的句法组成,然后更好理解句子的语义信息。这就是NLP的目的,也就是AI的目标。
句法分析(syntactic parsing)是自然语言处理中的关键技术之一,基本任务是确定句子的句法结构(syntactic structure)或句子中词汇之间的依存关系。句法分析分为:句法结构分析和依存关系分析。本博文将详细介绍句法结构分析的一种方法:基于概率上下文无关文法(PCFG)的统计句法分析,使用的算法是CYK算法,对输入的单词序列(句子)分析出合乎语法规则的句子语法结构,自然语言处理重要技术实践之一:句法分析。本篇详细记录学习总结和分享经验方法,python实现使用CYK算法对上下无关文法(PCFG)的句法分析,通过核心算法讲解深入理解统计句法分析的思想并掌握具体算法代码实现,得到一个句子的语法树。
这篇也是在NLP前两个任务的基础上,进一步让计算机理解人类自然语言的意义,前两个基础任务分别是:
二、CYK算法
在句法分析方法的细分中,结构分析有许多方法,这里采用概率上下文无关文法(PCFG)的统计句法分析,具体实现的算法选择了其中一个:CYK算法。顾名思义,由三位大牛(Cocke-Younger-Kasami)共同提出,算法的思想巧妙地运用了维特比动态规划的方法,实在佩服!来瞅瞅是什么厉害的算法。
给定一个句子s 和一个上下文无关文法PCFG,G=(T, N, S, R, P),定义一个跨越单词 i到j的概率最大的语法成分π: π(i,j,X)(i,j∈1…n ,X∈N),目标是找到一个属于π[1,n,S]的所有树中概率最大的那棵。
- T代表终端符集合
- N代表非终端符集合
- S代表初始非端结符
- R代表产生语法规则集
- P 代表每条产生规则的统计概率
下面是我根据算法思想整理写出的算法伪代码,比较容易理解:
function CKY(words, grammar) :
//初始化
score = new double[#(words)+1][#(words)+1][#(nonterms)]
back = new Pair[#(words)+1][#(words)+1][#nonterms]]
//填叶结点
for i=0; i<#(words); i++
for A in nonterms
if A -> words[i] in grammar
score[i][i+1][A] = P(A -> words[i])
//处理一元规则
boolean added = true
while added
added = false
//生成新的语法需要加入
for A, B in nonterms
if score[i][i+1][B] > 0 && A->B in grammar
prob = P(A->B)*score[i][i+1][B]
if prob > score[i][i+1][A]
score[i][i+1][A] = prob
back[i][i+1][A] = B
added = true
//自底向上处理非叶结点
for span = 2 to #(words)
for begin = 0 to #(words)- span//该层结点个数
end = begin + span
for split = begin+1 to end-1
for A,B,C in nonterms
prob=score[begin][split][B]*score[split][end][C]*P(A->BC)
//计算每种分裂概率,保存最大概率路径
if prob > score[begin][end][A]
score[begin]end][A] = prob
back[begin][end][A] = new Triple(split,B,C)
//处理一元语法
boolean added = true
while added
added = false
for A, B in nonterms
prob = P(A->B)*score[begin][end][B];
if prob > score[begin][end][A]
score[begin][end][A] = prob
back[begin][end][A] = B
added = true
//返回最佳路径树
return buildTree(score, back)score存放最大概率,back存放分裂点信息以便回溯,在接下来的具体算法实现,将用特别的数据结构实现数据信息的存储。
| score[0][0] | |||
| score[1][1] | |||
| score[2][2] | |||
| score[3][3] |
用矩阵的方式存储信息,以每个单词作为对角线上的元素,也就是树结构的叶结点。运用动态规划的思想进行填表,直到右上角计算出来,整棵树的结点信息就全部计算处理。
三、python实现:核心CYK算法
1、数据结构的选择及初始化
利用了python语言的优势,将字典和列表两种数据结构结合,实现概率的存储和路径信息的保存。
word_list = sentence.split()
best_path = [[ for _ in range(len(word_list))] for _ in range(len(word_list))]
# 初始化
for i in range(len(word_list)): # 下标为0开始
for j in range(len(word_list)):
for x in non_terminal: # 初始化每个字典,每个语法规则概率及路径为None,避免溢出和空指针
best_path[i][j][x] = 'prob': 0.0, 'path': 'split': None, 'rule': None2、叶结点的计算
这里还需提前普及一下语法规则的形式,形如:◼VP→VP PP ◼ S → Aux NP VP ◼ NP->astronomers 等就是一条语法规则,可以发现左边只有一个非终端符(词性),指向右边一个/多个非终端符或终端符(单词)。为了保证算法处理的统一性,我们要将语法规则通过某种方式统一起来,这就引申出CNF(乔姆斯基范式)。
如果一个上下文无关文法的每个产生式的形式为:A->BC或A->a,即规则的右部或者是两个非终端符或者是一个终端符。所以,本次实验数据给出了CNF的语法规则,方便了计算过程。
关键部分是,要实现①非终端符-单词的规则,然后再一次扫描语法规则集,将“新规则”②非终端符--①非终端符加入该叶结点的语法集合。
# 填叶结点,计算得到每个单词所有语法组成的概率
for i in range(len(word_list)): # 下标为0开始
for x in non_terminal: # 遍历非终端符,找到并计算此条非终端-终端语法的概率
if word_list[i] in rules_prob[x].keys():
best_path[i][i][x]['prob'] = rules_prob[x][word_list[i]] # 保存概率
best_path[i][i][x]['path'] = 'split': None, 'rule': word_list[i] # 保存路径
# 生成新的语法需要加入
for y in non_terminal:
if x in rules_prob[y].keys():
best_path[i][i][y]['prob'] = rules_prob[x][word_list[i]] * rules_prob[y][x]
best_path[i][i][y]['path'] = 'split': i, 'rule': x3、非叶结点
这是CYK算法的核心部分,填非叶结点。注释比较详细解释了每步的作用。
for l in range(1, len(word_list)):
# 该层结点个数
for i in range(len(word_list) - l): # 第一层:0,1,2
j = i + l # 处理第二层结点,(0,j=1),(1,2),(2,3) 1=0+1,2=1+1.3=2+1
for x in non_terminal: # 获取每个非终端符
tmp_best_x = 'prob': 0, 'path': None
for key, value in rules_prob[x].items(): # 遍历该非终端符所有语法规则
if key[0] not in non_terminal:
break
# 计算产生的分裂点概率,保留最大概率
for s in range(i, j): # 第一个位置可分裂一个(0,0--1,1)
# for A in best_path[i][s]
if len(key) == 2:
tmp_prob = value * best_path[i][s][key[0]]['prob'] * best_path[s + 1][j][key[1]]['prob']
else:
tmp_prob = value * best_path[i][s][key[0]]['prob'] * 0
if tmp_prob > tmp_best_x['prob']:
tmp_best_x['prob'] = tmp_prob
tmp_best_x['path'] = 'split': s, 'rule': key # 保存分裂点和生成的可用规则
best_path[i][j][x] = tmp_best_x # 得到一个规则中最大概率
# print("score[", i, "][", j, "]:", best_path[i][j])
best_path = best_path扩展的CYK算法需要处理一元语法规则,所以我用了一个判断语句,避免一元规则计算时候的数组越界。
for s in range(i, j): # 第一个位置可分裂一个(0,0--1,1)
# for A in best_path[i][s]
if len(key) == 2:
tmp_prob = value * best_path[i][s][key[0]]['prob'] * best_path[s + 1][j][key[1]]['prob']
else:
tmp_prob = value * best_path[i][s][key[0]]['prob'] * 0此步骤结束之后得到上三角每个结点的最大概率语法规则和分裂点路径,用于接下来路径回溯得到语法树。
4、回溯构建语法树
这步骤花了不少debug时间,遇到了树结点遍历为空的情况,很明显边界没有处理好。这是我开始先序遍历树的方法,递归得到语法树。
# 回溯路径,先序遍历树
def back(best_path, left, right, root, ind=0):
node = best_path[left][right][root]
if node['path']['split'] is not None: # 判断是否存在分裂点,值为下标
print('\\t' * ind, (root,))
# 递归调用
back(best_path, left, node['path']['split'], node['path']['rule'][0], ind + 1) # 左子树
back(best_path, node['path']['split'] + 1, right, node['path']['rule'][1], ind + 1) # 右子树
else:
print('\\t' * ind, (root,))
print('--->', node['path']['rule'])出错如图:TypeError: 'NoneType' object is not subscriptable

我排查了许久,发现是递归遍历了不存在的结点。成功解决之后修改程序如下:
def back(best_path, left, right, root, ind=0):
node = best_path[left][right][root]
if node['path']['split'] is not None: # 判断是否存在分裂点,值为下标
print('\\t' * ind, (root,node['prob'])) # self.rules_prob[root].get(node['path']['rule']
# 递归调用
if len(node['path']['rule']) == 2: # 如果规则为二元,递归调用左子树、右子树,如 NP-->NP NP
back(best_path, left, node['path']['split'], node['path']['rule'][0], ind + 1) # 左子树
back(best_path, node['path']['split'] + 1, right, node['path']['rule'][1], ind + 1) # 右子树
else: # 否则,只递归左子树,如 NP-->N
back(best_path, left, node['path']['split'], node['path']['rule'][0], ind + 1)
else:
print('\\t' * ind, (root,node['prob']))
print('--->', node['path']['rule'])四、句法分析详例解读
给定以下 PCFG,实现句子“fish people fish tanks ”最可能的统计句法树,并将最终树以串形式或树形式打印。
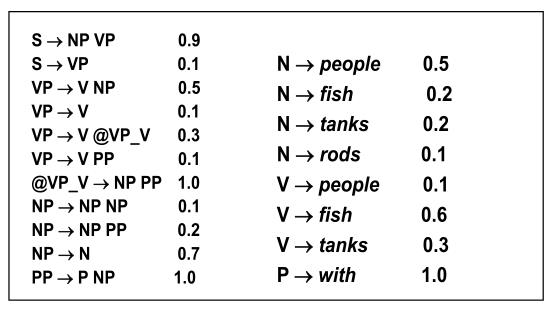
第一层,叶结点的计算结果,得到叶节点的语法概率以及分裂点。
fish----> 'V': 'prob': 0.6, 'path': 'split': None, 'rule': 'fish','N': 'prob': 0.2, 'path': 'split': None, 'rule': 'fish', 'NP': 'prob': 0.13999999999999999, 'path': 'split': 0, 'rule': 'N','VP': 'prob': 0.06, 'path': 'split': 0, 'rule': 'V'
people---> 'V': 'prob': 0.1, 'path': 'split': None, 'rule': 'people', 'N': 'prob': 0.5, 'path': 'split': None, 'rule': 'people', 'NP': 'prob': 0.35, 'path': 'split': 1, 'rule': 'N','VP': 'prob':0.010000000000000002, 'path': 'split': 1, 'rule': 'V'
fish---> 'V': 'prob': 0.6, 'path': 'split': None, 'rule': 'fish', 'N': 'prob': 0.2, 'path': 'split': None, 'rule': 'fish', 'NP': 'prob': 0.13999999999999999, 'path': 'split': 2, 'rule': 'N','VP': 'prob': 0.06, 'path': 'split': 2, 'rule': 'V'
tanks---> 'V': 'prob': 0.3, 'path': 'split': None, 'rule': 'tanks', 'N': 'prob': 0.2, 'path': 'split': None, 'rule': 'tanks', 'NP': 'prob': 0.13999999999999999, 'path': 'split': 3, 'rule': 'N','VP': 'prob': 0.03, 'path': 'split': 3, 'rule': 'V'直观地展示就是:




非叶节点层,通过CYK算法,自底向上计算非叶节点,保存了各个规则的最大概率以及分裂点。
score[ 0 ][ 1 ]: 'NP': 'prob': 0.004899999999999999, 'path': 'split': 0, 'rule': ('NP', 'NP'), 'S': 'prob': 0.0012600000000000003, 'path': 'split': 0, 'rule': ('NP', 'VP'), 'VP': 'prob': 0.105, 'path': 'split': 0, 'rule': ('V', 'NP')
score[ 1 ][ 2 ]: 'NP': 'prob': 0.004899999999999999, 'path': 'split': 1, 'rule': ('NP', 'NP'), 'S': 'prob': 0.0189, 'path': 'split': 1, 'rule': ('NP', 'VP'), 'VP': 'prob': 0.006999999999999999, 'path': 'split': 1, 'rule': ('V', 'NP')
score[ 2 ][ 3 ]: 'NP': 'prob': 0.0019599999999999995, 'path': 'split': 2, 'rule': ('NP', 'NP'), 'S': 'prob': 0.00378, 'path': 'split': 2, 'rule': ('NP', 'VP'), 'VP': 'prob': 0.041999999999999996, 'path': 'split': 2, 'rule': ('V', 'NP')
score[ 0 ][ 2 ]: 'NP': 'prob': 6.859999999999997e-05, 'path': 'split': 0, 'rule': ('NP', 'NP'), 'S': 'prob': 0.0008819999999999999, 'path': 'split': 0, 'rule': ('NP', 'VP'),'VP': 'prob': 0.0014699999999999997, 'path': 'split': 0, 'rule': ('V', 'NP')
score[ 1 ][ 3 ]: 'NP': 'prob': 6.859999999999997e-05, 'path': 'split': 1, 'rule': ('NP', 'NP'), 'S': 'prob': 0.013229999999999999, 'path': 'split': 1, 'rule': ('NP', 'VP'),'VP': 'prob': 9.799999999999998e-05, 'path': 'split': 1, 'rule': ('V', 'NP')
score[ 0 ][ 3 ]: 'NP': 'prob': 9.603999999999995e-07, 'path': 'split': 0, 'rule': ('NP', 'NP'), 'S': 'prob': 0.00018521999999999994, 'path': 'split': 1, 'rule': ('NP', 'VP'), 'V': 'prob': 0, 'path': None, 'VP': 'prob': 2.0579999999999993e-05, 'path': 'split': 0, 'rule': ('V', 'NP') 
从根节点的开始标志S出发,按照之前保留的路径找出概率最大句法树。下图为直观的回溯过程。
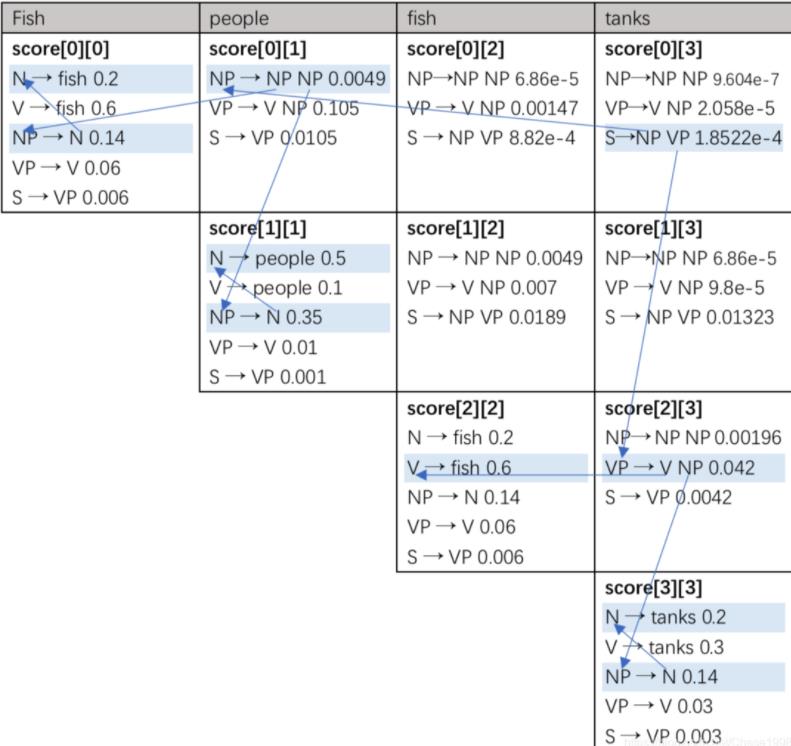
回看实际的数据存储结构,我们已经将路径path保存在字典中,以及回溯的rule和分裂点,这样就在程序实现操作比较容易实现。
五、实验结果:语法树结构
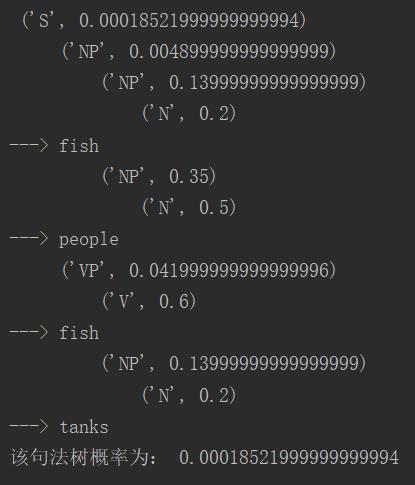
结果与实际手写推算一致,画出的语法树为:
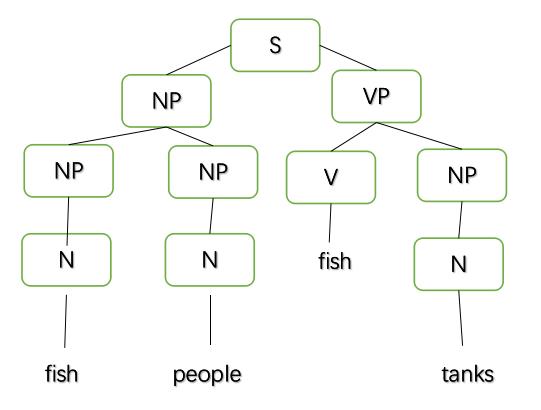
六、分析总结
本篇实现了基于概率上下文无关文法(PCFG)的统计句法分析,使用的算法是CYK算法。本篇记录详细步骤python实现使用CYK算法对上下无关文法(PCFG)的句法分析,通过核心算法讲解深入理解统计句法分析的思想并掌握具体算法代码实现,得到一个句子的语法树。
在给定的PCFG语法规则,实现对特定句子的句法分析,得到最可能的统计句法树,首先用程序实现,需要找到合适的数据结构对语法规则和概率,非终端符和终端符进行存储,所以我才用了字典和列表两种结果存储数据。第二步,核心算法CYK的具体实现,这也是对以上数据结构中数据的操作计算过程,对于本作业,还需处理一元规则,使用到扩展的CYK算法。第三步,通过CYK算法,得到了最佳路径,需要根据分裂点通过回溯输出最终的语法树。
在完成核心部分CYK的过程,遇到了许多问题,主要容易出错的地方包括:叶节点语法规则加入到字典中、非叶节点最大概率的规则加入和不同分裂点的保存、回溯路径树结构的结果输出。这三个部分重点在于边界处理,遇到过溢出和数组越界、值为空等问题,这导致在回溯树时候会出现问题,所以,为了解决以上问题,正确设置断点,单步调试程序是很重要有效的排错方法,我不断进行调试,在重要语句设置断点观察程序执行情况,修正程序的bug,优化算法结构,保证清晰的程序思路,最终得到正确的结果。相对来说,这次选择了程序实现方式,花费的时间较长,但是在不断调试debug过程,对整个CYK算法的思想有了更加深刻地理解。
我的博客:https://blog.csdn.net/Charzous/article/details/109671138
以上是关于NLP技术:基于PCFG的CYK算法统计句法分析的主要内容,如果未能解决你的问题,请参考以下文章