linux wa%过高,iostat查看io状况
Posted 乎合
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux wa%过高,iostat查看io状况相关的知识,希望对你有一定的参考价值。
在使用top命令的时候会看到这么一行:

翻译一下:
us:用户态使用的cpu时间比
sy:系统态使用的cpu时间比
ni:用做nice加权的进程分配的用户态cpu时间比
id:空闲的cpu时间比
wa:cpu等待磁盘写入完成时间
hi:硬中断消耗时间
si:软中断消耗时间
st:虚拟机偷取时间
如果一台机器看到wa特别高,那么一般说明是磁盘IO出现问题,可以使用iostat等命令继续进行详细分析。
1, 安装 iostat
yum install sysstat
之后就可以使用 iostat 命令了,
2,入门使用
iostat -d -k 2
参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;2表示,数据显示每隔2秒刷新一次。
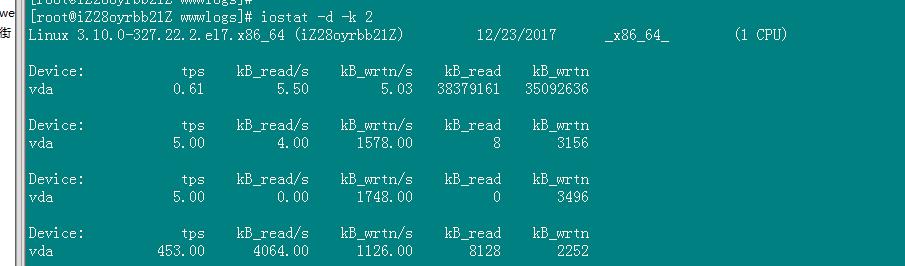
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。 kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量; kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
指定监控的设备名称为sda,该命令的输出结果和上面命令完全相同。
iostat -d sda 2
默认监控所有的硬盘设备,现在指定只监控sda。
3, -x 参数
iostat还有一个比较常用的选项-x,该选项将用于显示和io相关的扩展数据。
iostat -d -x -k 1 10
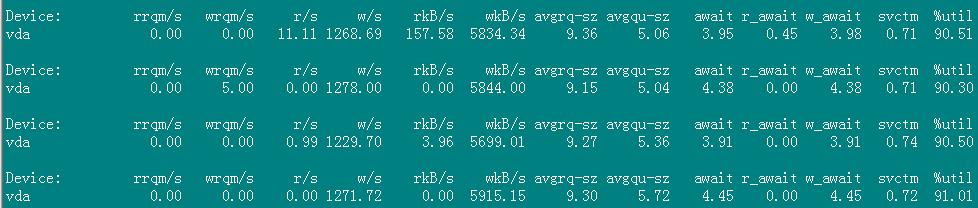
输出信息的含义
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,
FS会将这个请求合并Merge);
wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。 rsec/s:每秒读取的扇区数; wsec/:每秒写入的扇区数。 rKB/s:The number of read requests that were issued to the device per second; wKB/s:The number of write requests that were issued to the device per second; avgrq-sz 平均请求扇区的大小 avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。 await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。 这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。 svctm 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,
则表示I/O队列等待太长,
系统上运行的应用程序将变慢。
%util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,
而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,
所以该参数暗示了设备的繁忙程度
。一般地,如果该参数是100%表示设备已经接近满负荷运行了
(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
4, 常见用法
iostat -d -k 1 10 #查看TPS和吞吐量信息(磁盘读写速度单位为KB) iostat -d -m 2 #查看TPS和吞吐量信息(磁盘读写速度单位为MB) iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await) iostat -c 1 10 #查看cpu状态
5, 实例分析
iostat -d -k 1 | grep vda Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda10 60.72 18.95 71.53 395637647 1493241908 sda10 299.02 4266.67 129.41 4352 132 sda10 483.84 4589.90 4117.17 4544 4076 sda10 218.00 3360.00 100.00 3360 100 sda10 546.00 8784.00 124.00 8784 124 sda10 827.00 13232.00 136.00 13232 136
上面看到,磁盘每秒传输次数平均约400;每秒磁盘读取约5MB,写入约1MB。
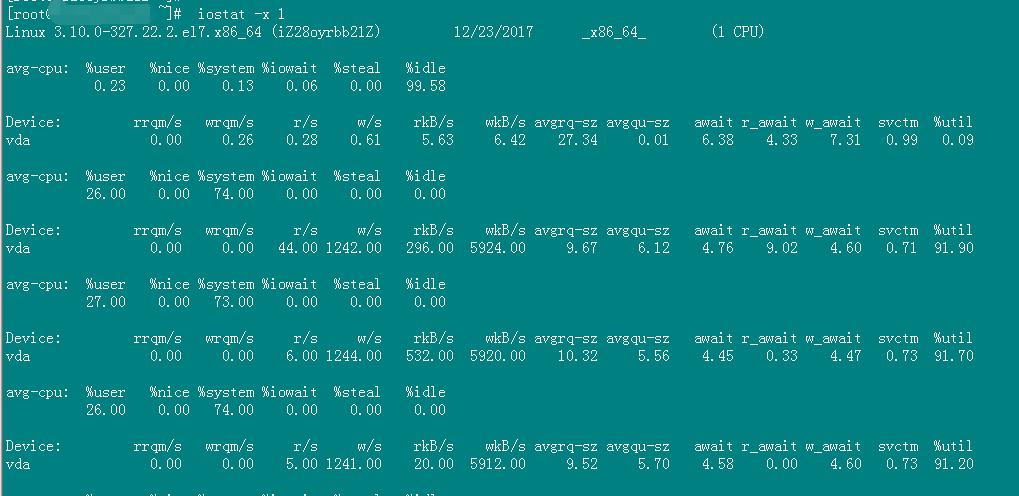
iostat -d -x -k 1 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util sda 1.56 28.31 7.84 31.50 43.65 3.16 21.82 1.58 1.19 0.03 0.80 2.61 10.29 sda 1.98 24.75 419.80 6.93 13465.35 253.47 6732.67 126.73 32.15 2.00 4.70 2.00 85.25 sda 3.06 41.84 444.90 54.08 14204.08 2048.98 7102.04 1024.49 32.57 2.10 4.21 1.85 92.24
可以看到磁盘的平均响应时间<5ms,磁盘使用率>80。磁盘响应正常,但是已经很繁忙了。
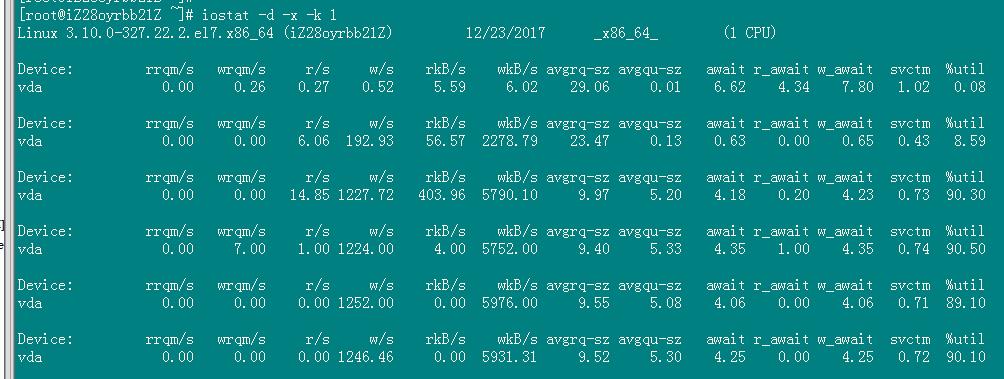
可以看到磁盘的平均响应时间<5ms,磁盘使用率>90。磁盘响应正常,但是已经很繁忙了。
await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了
svctm 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,
如果await的值远高于svctm的值,则表示I/O队列等待太长, 系统上运行的应用程序将变慢。
%util: 在统计时间内所有处理IO时间,除以总共统计时间
所以该参数暗示了设备的繁忙程度
。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
也可以使用下面的命令,同时显示cpu和磁盘的使用情况
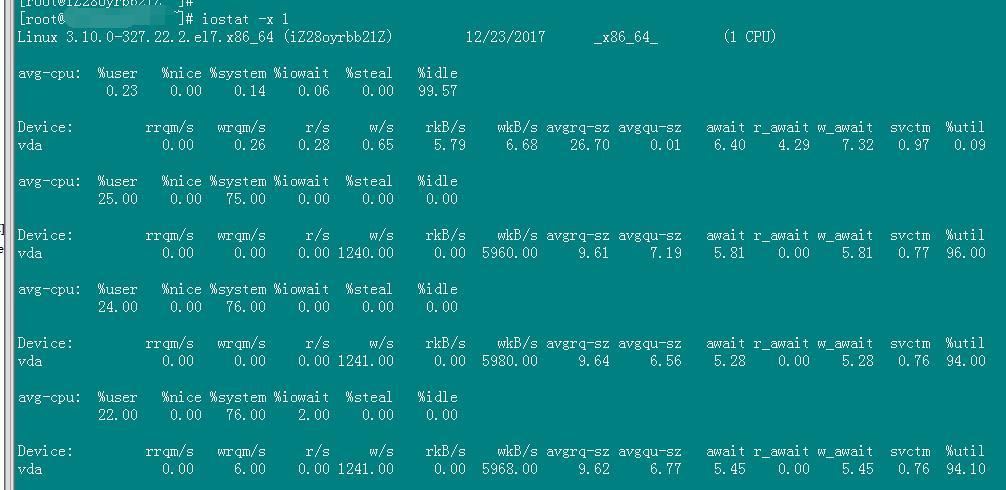
等待时间超过5ms, 磁盘io有问题
以上是关于linux wa%过高,iostat查看io状况的主要内容,如果未能解决你的问题,请参考以下文章
linux负载过高 排查方法及说明 附:Centos安装iostat
监控io性能/free命令/ps命令/查看网络状况/linux下抓包