Spark Streaming实时处理
Posted 皓洲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming实时处理相关的知识,希望对你有一定的参考价值。
Spark Streaming实时处理
实验内容
在本地或HDFS新建一个测试目录,编写一个简单程序,每随机间隔若干秒(5s以内)在该目录下新建一个文件,并写入若干行内容(每一行包含若干单词,单词之间以空格分隔)。现利用Spark Streaming分别完成如下单词统计:
(1)实时统计每10s新出现的单词数量(每10s统计1次);
(2)实时统计最近1分钟内每个单词的出现次数(每10s统计1次);
(3)实时统计每个单词的累积出现次数,并将结果保存到本地文件(每10s统计1次)
实验步骤
(1)实时统计每10s新出现的单词数量(每10s统计1次)
import org.apache.spark._
import org.apache.spark.streaming._
object WordCountStreaming
def main(args: Array[String])
val ssc = new StreamingContext(sc, Seconds(10))// 时间间隔为10秒
val lines = ssc.textFileStream("file:///home/hadoop/spark/logfile") //这里采用本地文件,当然你也可以采用HDFS文件
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()

问题原因
这是由于 被读取的文件必须存放在 Spark 集群的每一个 Worker 节点
解决方案
1)拷贝文件到每一个 Worker 节点
2)从 HDFS 中读取
结果:
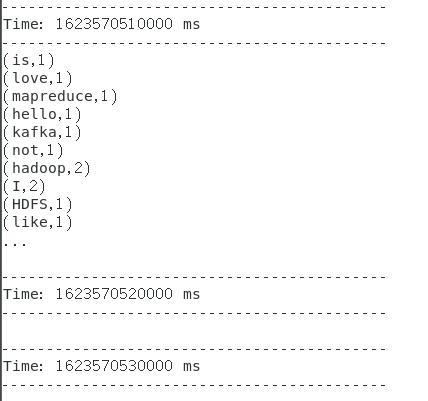
(2)实时统计最近1分钟内每个单词的出现次数(每10s统计1次)
import org.apache.spark.streaming._
object WordCountStreaming
def main(args: Array[String])
//设定每10s统计一次
val ssc = new StreamingContext(sc, Seconds(10))
//设置检查点,检查点具有容错机制
ssc.checkpoint("/checkpoint")
//填写要读取的文件流
val lines = ssc.textFileStream("file:///home/hadoop/spark/logfile")
val words = lines.flatMap(_.split(" "))
val pair = words.map(x=>(x, 1))
//设定滑动窗口长度为1分钟,统计间隔为10秒,对新进入滑动窗口的数据设定为相加函数,对离开滑动窗口的数据进行相减操作。
val wordCounts = pair.reduceByKeyAndWindow(_+_, _-_, Seconds(60), Seconds(10))
wordCounts.print()
ssc.start()
结果:
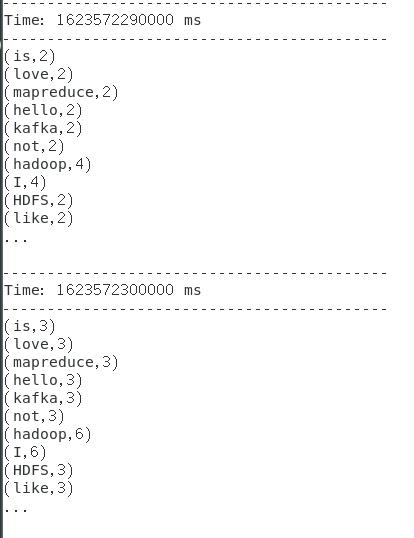
(3)实时统计每个单词的累积出现次数,并将结果保存到本地文件(每10s统计1次)
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.storage.StorageLevel
//设定状态更新函数
val updateFunc = (values: Seq[Int], state: Option[Int]) =>
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
val ssc = new StreamingContext(sc, Seconds(10))
//设置检查点
ssc.checkpoint("/check1")
val lines = ssc.textFileStream("file:///home/hadoop/spark/logfile")
val words = lines.flatMap(_.split(" "))
val pair = words.map(x => (x,1))
//由于是跨批次之间维护状态,所以需要调用updateStateByKey函数
val stateDstream = pair.updateStateByKey[Int](updateFunc)
stateDstream.print()
//将结果存储到本地文件中
stateDstream.saveAsTextFiles("file:///home/hadoop/spark/output.txt")
ssc.start()
结果:

以上是关于Spark Streaming实时处理的主要内容,如果未能解决你的问题,请参考以下文章