走进并行时代之GPU篇
Posted threepigs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走进并行时代之GPU篇相关的知识,希望对你有一定的参考价值。
并行计算一直以来都是比较高端的一个东东,对于普通的程序员还是不容易接触。不过如今多核开始流行,用自己的一台PC机都可以来实现并行算法了,多核从结构上来看就和SMP差不多。只是现在主流的也就2核,体现不出并行计算的强大。另一方面,GPU现在是越做越强大,nv发布G80的时候的一个口号就是打造个人的超级计算机。GPU和CPU的设计理念不同,GPU是计算密集型的,因为它的最初设计就是为了图形处理,并不需要很复杂的控制逻辑,而需要处理大量的计算,所以也不需要想CPU那样花很多的晶体管在控制器上面,省下来都用来设计ALU了。另外对于访存,CPU和GPU都需要上百时钟周期,CPU用的是Cache机制来避免过多的访存影响程序性能,所以CPU内部Cache占了很多的晶体管数量。而GPU里面没多少Cache,它主要利用多线程,在线程之间的切换来掩藏这个延迟。GPU的计算单元很多,所以线程也多,这种线程和我们常说的线程不同,它是一种硬件的多线程。GPU上面并没有OS来管理,线程之间主要就是靠寄存器组来隔离,所以线程之间的切换也不需要什么太多的上下文切换,这使得线程之间切换基本能达到零开销。这样如果某个线程被访存阻塞了,马上就切到另外的线程。GPU就靠这种方式来减小访存对程序的影响,减少用于Cache的那部分晶体管来给计算单元。正因为GPU有如此多的计算单元,才使得它用于通用计算有着很好的加速比。
GPU的发展
传统的GPU就是专为图形处理而设计,只不过随着它的处理能力的越来越强,继续局限于图形领域的话有点浪费,当你不玩3D游戏的话,你的显卡就是个摆设。因此显卡厂商方面当然是希望扩充市场,而程序员也是不想浪费自己的硬件资源。于是GPU这么多年的发展都是朝着通用化这个大方向来的,首先是显卡厂商慢慢把以前的固定的硬件单元设计可编程,可以让程序员自己设计函数功能,于是出现了GPGPU。到后来出现质变,出现了今天的统一渲染架构,这种架构基本上就是一种通用化的设计,把不同的流水级统一成一套计算单元,在逻辑层面上由线程调度器来区分不同的功能。再到后来,出现了未来
的Larrabee,虽然Intel的这款显卡还没上市,不过今年8月份的siggraph会议上,已经公布了技术细节。这款显卡彻彻底底的就是一款通用的CPU,利用多核做显卡,所有的图形流水线由软件模拟。接下来打算分三部分简单介绍一下GPU。第一部分传统的GPU,第二部分统一渲染架构,第三部分Larrabee。
传统的GPU
介绍这类GPU其实就是介绍图形流水线,因为它的内部硬件模块就是完全按照图形流水线来分级设计的。下图是图形流水线的各级。
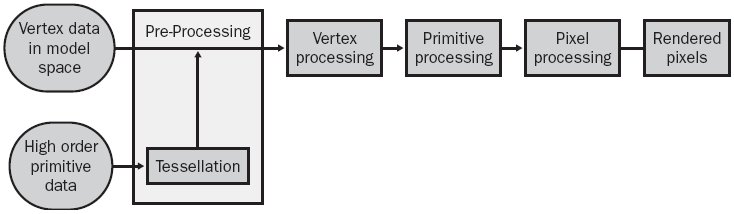
第一部分是数据汇集阶段,通过OGL或者DX的接口把3D图元的各顶点通过DMA方式,由PCIE总线传进GPU。3D的场景的基本图元是三角片,用三角片来逼近物体,通过绘制三角片来绘制三维物体。第二部分是顶点处理模块,对图元的顶点进行几何变换,这个阶段处理的数据对象是三角片的顶点,主要进行平移、旋转、投影等变换,这里主要是介绍GPGPU,这些图形领域的具体细节就不详细介绍了。第三部分是光栅化过程,绘制一个三维场景你不可能只画顶点吧,因此需要对三角片的
顶点进行插值得到三角片的内部的像素点坐标。这个阶段属于图形处理特有阶段,所以GPU基本上都是把他作为一个固定的专用不可编程模块。一来可以设计更高效的硬件来做光栅化处理,提高光栅化速度,二来可以跟其他模块并行执行。不过Larrabee则连光栅化阶段都用软件实现,可见其通用化程度多强,牺牲了部分图形处理的效率来换通用化设计。第四部分则是像素点处理模块,处理的数据对象是经过光栅化之后的各像素点,进行一系列的渲染,包含各种光照效果、纹理映射等。这个阶段的数据量非常大,需要大量的计算单元,是高并行性,高吞吐量的一个流水级。这个硬件模块是GPGPU的一个关键,它有大量计算单元并行执行,把它用于通用计算可以大大加速算法。最后就是像素的绘制,像素点被写入帧缓冲区显示在屏幕上。
GPU作为通用计算的历史就是各种流水级模块变成可编程单元的过程。一开始GPU专用于图形处理,所有的模块都是固定单元。随后开始引入顶点着色器,顶点处理模块可以编程,开始出现了早期的GPGPU。接着像素处理模块也变成可编程,出现顶点着色器。随着Geforce 6800的发布,这两种着色器支持分支,循环,子函数调用功能,于是GPGPU得到了极大的发展,各种各样的高并行性的通用计算都开始考虑用GPU来实现。
Geforce 6800 architecture
下图是选自GPU Gems2的6800的结构图。
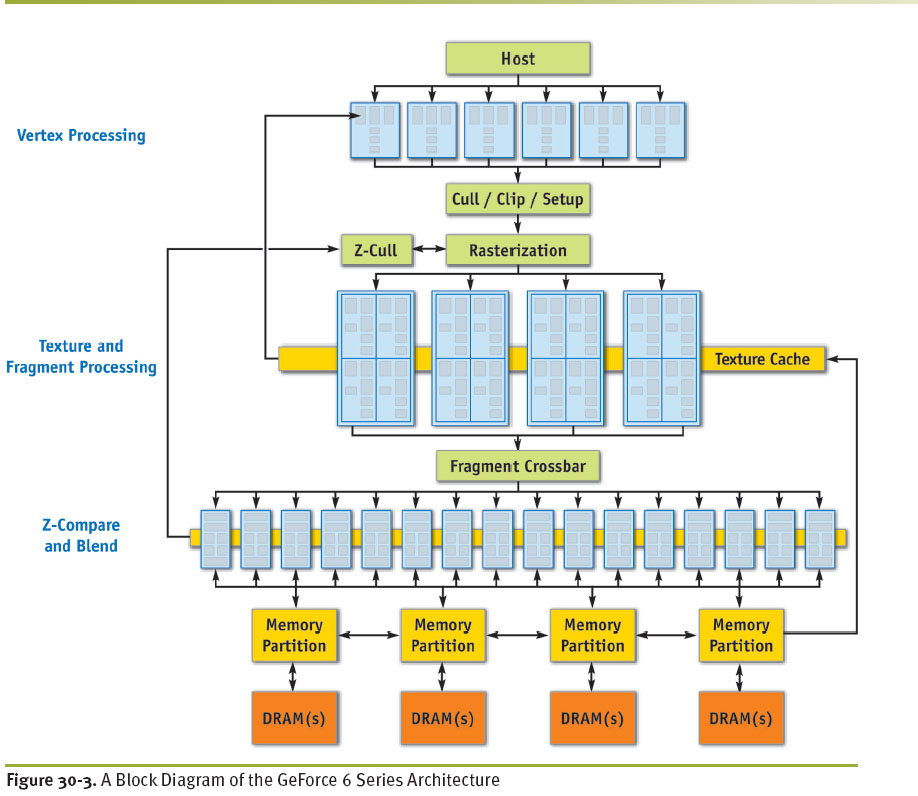
顶点处理和像素处理是可编程的,前者的Unit个数是6个,后者是16个。整个graphics pipeline是并行的,命令流和数据流由DX或者OGL驱动写入GPU,数据经过各级流水线最后写入显存,显存分为几个banks同时读写,增加了显存带宽。
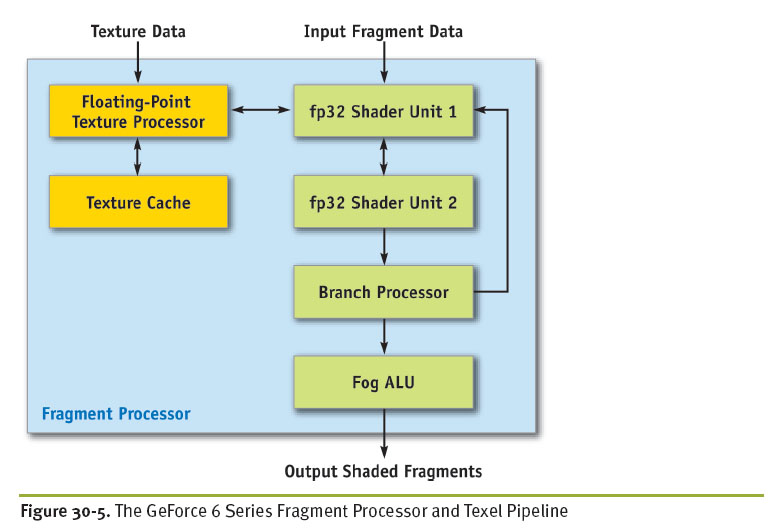
顶点处理器的ALU是一个fp32矢量单元加一个fp32的标量单元。

矢量单元是宽度为4的SIMD的乘加指令,标量单元是特定函数指令(指数,倒数,三角)。至于指令流的译码发射硬件,找了很多资料都没有介绍。像素处理器的ALU是两个fp32矢量单元,每个单元同样是宽度为4的乘加指令,不过这里硬件支持co-issue,可以四个分量的SIMD操作,也支持2:2,3:1这样的协同发射,使得向量可以同时进行两个不同的操作,再加上双发射可以填满两个像素着色器单元。这使得编译器可以把一些标量操作打包成矢量计算,类似于超长指令字。
{kind=link}
由于能找到的资料基本上都是对GPU体系结构功能性的介绍,因此很多具体的硬件实现细节还是不太清楚,如果哪位大牛熟悉硬件细节的话,望指教。
最后,这种传统的GPU体系结构的通用编程主要还是通过DX和OGL提供的着色器编程接口。最早的是通过直接写汇编作为着色器代码,后来为了可编程性出现了HLSL、GLSL和CG高级着色语言来对顶点处理器和像素处理器进行编程。相关的代码在运行时刻被即时编译成GPU代码,然后发射到GPU上执行。这是最主要的一种编程语言,它需要对图形流水线熟悉,把算法映射到流水线操作。另一种就是Stanford设计的brook流语言,这是最早的一种GPU通用语言,编程过程完全按照通用计算的模式来编程,不需要对图形流水线有了解。它用自己的编译器作为前端来编译该流语言,后端还是利用DX或者OGL,只不过这是对程序员透明的。为了编程的通用性,必然会造成一定程度的效率损失。
以上是关于走进并行时代之GPU篇的主要内容,如果未能解决你的问题,请参考以下文章