Zephyr RTOS -- Threads
Posted 搬砖-工人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zephyr RTOS -- Threads相关的知识,希望对你有一定的参考价值。
文章目录
- 前言
- Threads - (线程)
- 1. Lifecycle - (生命周期)
- 2. Thread States - (线程状态)
- 3. Thread Stack objects - (线程堆栈对象)
- 4. Thread Priorities - (线程优先级)
- 5. Thread Options - (线程选项)
- 6. Thread Custom Data - (线程自定义数据)
- 7. Implementation - (实现)
- 8. Runtime Statistics - (运行时统计信息)
- 9. Suggested Uses - (建议用途)
- 10. Configuration Options - (配置选项)
- 11. API Reference - (API 参考)
- 参考链接
本笔记基于 Zephyr 版本 2.6.0-rc2
前言
本人正在学习 Zephyr,一个可移植性较强,可以兼容多种开发板及物联网设备的操作系统,如果你感兴趣,可以点此查看我的 学习笔记总述 进行了解!
Threads - (线程)
线程是内核对象,用于太长或太复杂而无法由 ISR 执行的应用程序处理。
应用程序可以定义任意数量的线程 (仅受可用 RAM 限制),每个线程都由生成该线程时分配的线程 ID 引用。
线程具有以下的属性:
- A stack area(堆栈区域),其是用于所述线程的堆栈的存储器区域,可以调整堆栈区域的大小以符合线程处理的实际需求。存在特殊的宏来创建和使用堆栈存储区。
- A thread control block(线程控制块),用于线程的元数据的专用内核簿记。 这是类型 k_thread 的实例。
- An entry point function(入口函数),在线程启动时调用。最多可以将 3 个参数值传递给此函数。
- A scheduling priority(调度优先级),指示内核的调度如何分配CPU时间线程。参考 Scheduling。
- A set of thread options(线程选项),允许线程在特定情况下接受内核的特殊处理。参考 Thread Options。
- A start delay(启动延迟),它指定内核在启动线程之前应等待的时间。
- An execution mode(执行模式),可以是超级用户模式(supervisor mode)或用户模式(user mode)。 默认情况下,线程在超级用户模式下运行,并允许访问特权 CPU 指令,整个内存地址空间和外围设备。 用户模式线程的特权减少了。 这取决于
CONFIG_USERSPACE选项。 请参阅 User mode(用户模式)。
1. Lifecycle - (生命周期)
1.1 Thread Creation - (线程创建)
线程在被使用之前必须先被创建,内核初始化线程控制块以及堆栈部分的一端。 线程栈的其余部分通常未初始化。
可以指示内核通过指定超时值来延迟线程的执行,例如,允许线程使用的设备硬件变得可用。
指定启动延迟 K_NO_WAIT 会指示内核立即启动线程执行。
内核允许在线程开始执行之前取消延迟的启动。但是如果线程已经启动,则取消请求无效。延迟启动成功取消的线程,必须重新生成后才能使用。
1.2 Thread Termination - (线程终止)
线程一旦启动,通常将永远执行。但是,线程可以通过从其入口点函数返回来同步结束其执行。这称为终止。
终止线程负责在返回之前释放其可能拥有的任何共享资源 (例如互斥体和动态分配的内存),因为内核不会自动回收它们。
在某些情况下,一个线程可能要休眠,直到另一个线程终止。可以使用 k_thread_join() API 来完成。这将阻塞调用线程,直到超时到期,目标线程自行退出或目标线程异常中止(由于 k_thread_abort() 调用或触发致命错误)。
线程终止后,内核保证不会使用线程结构(k_thread)。 然后可以将这种结构的内存重新用于任何目的,包括产生新线程。
请注意,线程必须完全终止,这会在竞争状态下出现竞争情况,在该竞争情况下,一个线程自己的逻辑会发出信号完成信号,该信号在内核处理完成之前会被另一个线程看到。 在正常情况下,应用程序代码应使用 k_thread_join() 或 k_thread_abort() 来同步线程终止状态,而不应依赖于来自应用程序逻辑内部的信号。
原文:
Once a thread has terminated, the kernel guarantees that no use will be made of the thread struct. The memory of such a struct can then be re-used for any purpose, including spawning a new thread. Note that the thread must be fully terminated, which presents race conditions where a thread’s own logic signals completion which is seen by another thread before the kernel processing is complete. Under normal circumstances, application code should usek_thread_join()ork_thread_abort()to synchronize on thread termination state and not rely on signaling from within application logic.
1.3 Thread Aborting - (线程中止)
线程可以通过 中止 异步结束其执行。如果线程触发致命错误条件 (例如,取消引用空指针),内核会自动中止线程
线程也可以通过另一个线程 (或由其自身) 调用 k_thread_abort() 被中止。但是,通常最好是发信号通知线程适当地终止自身,而不是中止该线程。
和 线程终止 一样,内核不会回收异常中止线程所拥有的共享资源
1.4 Thread Suspension - (线程挂起/暂停)
如果线程被挂起,可以无限期地阻止其执行。该函数 k_thread_suspend() 可用于挂起任何线程,包括已经调用的线程。一旦挂起,就无法调度线程,直到另一个线程调用 k_thread_resume() 以取消挂起。
挂起已被挂起的线程不会产生任何其他影响。
Note: 线程可以在指定的时间段内阻止自己执行,通过使用 k_sleep() 。 但是,这与挂起线程不同,因为达到时间限制时,休眠线程会自动执行。
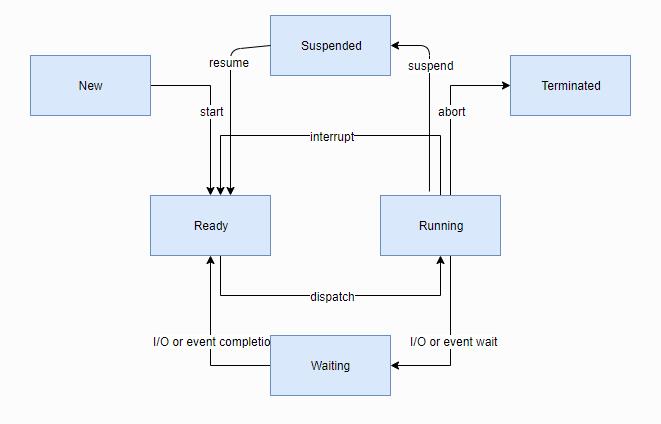
2. Thread States - (线程状态)
没有任何妨碍其执行的因素的线程被视为准备就绪态 (ready),并且有资格被选择为当前线程。
具有一个或多个阻止其执行的因素的线程被视为未就绪态 (unready),并且不能被选择为当前线程。
以下的因素使一个线程处于 unready 状态:
- 线程未被启动
- 线程正在等待内核对象完成操作 (例如:该线程正在使用不可用的信号量)
- 线程正在等待超时发生
- 线程已被挂起
- 线程被终止或中止
线程状态切换图:
3. Thread Stack objects - (线程堆栈对象)
每个线程都需要自己的堆栈缓冲区,CPU 才能推送内容。根据配置,必须满足几个约束条件:
- 可能需要为内存管理结构保留额外的内存
- 如果启用了基于保护的堆栈溢出检测,则必须在堆栈缓冲区之前立即设置一个小的写保护存储器管理区域,以捕获溢出。
- 如果启用了用户空间,则必须保留一个单独的固定大小的特权提升堆栈,以用作处理系统调用的专用内核堆栈。
- 如果启用了用户空间,则线程的堆栈缓冲区的大小必须适当调整并对齐,以便可以对内存保护区域进行编程以使其完全适合。
对齐约束可能非常严格,例如,某些 MPU 要求其区域的大小为 2 的幂,并且要与其自身的大小对齐。
因此,可移植代码无法简单地将任意字符缓冲区传递给 k_thread_create()。存在特殊的宏以实例化堆栈,并以K_KERNEL_STACK 和前缀 K_THREAD_STACK。
3.1 Kernel-only Stacks - (仅内核堆栈)
如果已知线程永远不会在用户模式下运行,或者堆栈用于特殊内容 (例如处理中断),则最好使用 K_KERNEL_STACK 宏定义堆栈。
这些堆栈可节省内存,因为无需对MPU区域进行编程即可覆盖堆栈缓冲区本身,并且内核无需为特权提升堆栈或仅与用户模式线程相关的内存管理数据结构保留额外的空间
如果 CONFIG_USERSPACE 未启用,则 K_THREAD_STACK 宏的作用与 K_KERNEL_STACK 宏相同。
3.2 Thread stacks - (线程堆栈)
如果已知某个堆栈需要托管用户线程,或者无法确定该线程,请使用 K_THREAD_STACK 宏定义该堆栈。这可能会使用更多的内存,但是堆栈对象适合于承载用户线程。
如果 CONFIG_USERSPACE 未启用,则 K_THREAD_STACK 宏的作用与 K_KERNEL_STACK 宏相同。
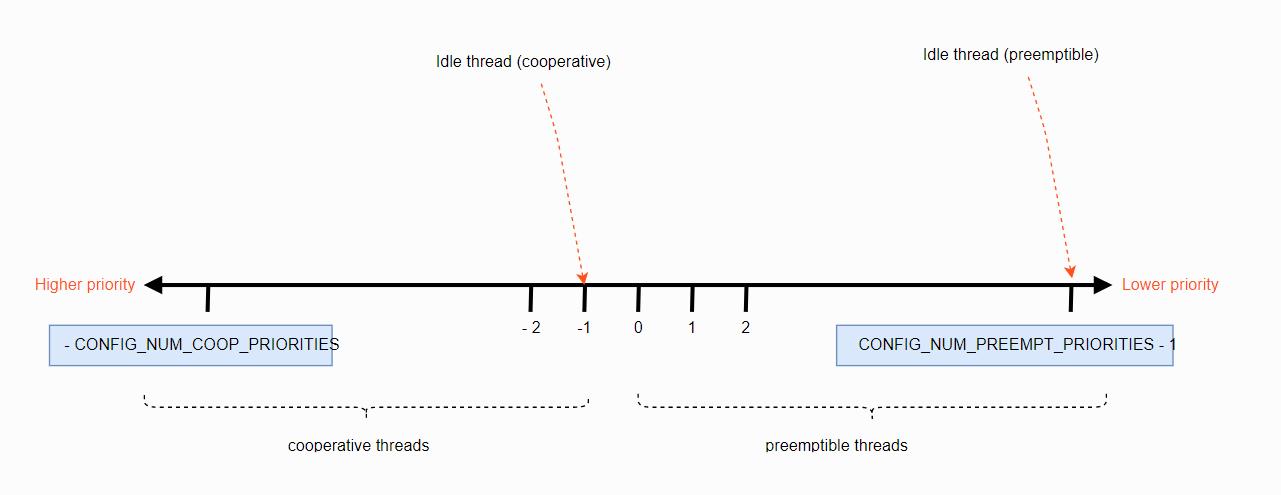
4. Thread Priorities - (线程优先级)
线程的优先级是整数值,可以为负或非负。数字上较低的优先级优先于数字上较高的值。
例如,调度程序为优先级为 4 的线程 A 高于优先级为 7 的线程 B 的优先级。
同样,优先级为 -2 的线程 C 的优先级高于线程 A 和线程 B。
调度程序根据每个线程的优先级来区分两类线程:
- 一个协作线程的优先级值为负。 一旦成为当前线程,协作线程将保留为当前线程,直到它执行操作使它变为未就绪态 (unready)。
- 一个可抢占线程具有非负的优先级值,一旦成为当前线程,如果协作线程或具有更高或同等优先级的可抢占线程准备就绪,则可随时替换可抢占线程。
启动线程后,可以向上或向下更改线程的初始优先级值。因此,通过更改优先级,可抢占线程有可能变为协作线程,反之亦然。
内核几乎支持无限数量的线程优先级。配置选项,CONFIG_NUM_COOP_PRIORITIES 和 CONFIG_NUM_PREEMPT_PRIORITIES 指定每种线程类的优先级级别数,从而产生以下可用的优先级范围:
- 协作线程:(-
CONFIG_NUM_COOP_PRIORITIES) to -1 - 抢占线程:0 to (
CONFIG_NUM_PREEMPT_PRIORITIES- 1)
5. Thread Options - (线程选项)
内核支持一小组线程选项,这些选项允许线程在特定情况下获得特殊待遇。生成线程时,将指定与线程关联的选项集。
不需要任何线程选项的线程的选项值为零。需要线程选项的线程通过名称指定,如果需要多个选项,则使用 | 字符作为分隔符。(即使用按位或运算符组合选项)
支持的线程选项:
K_ESSENTIAL:此选项将线程标记为必要线程(essential thread),这指示内核将线程的终止或中止视为致命的系统错误。默认情况下,该线程不被视为必不可少的线程。K_SSE_REGS:此特定于x86的选项表示线程使用CPU的SSE寄存器。 另请参阅K_FP_REGS。默认情况下,内核在调度线程时不尝试保存和恢复该寄存器的内容。K_FP_REGS:此选项表明线程使用 CPU 的浮点寄存器(CPU’s floating point registers)。这指示内核在调度线程时采取其他步骤来保存和恢复这些寄存器的内容。(有关更多信息,请参见浮点服务(Floating Point Services)) 默认情况下,内核在调度线程时不尝试保存和恢复该寄存器的内容。K_USER:如果CONFIG_USERSPACE启用,则该线程将在用户模式下创建,并具有减少的特权。请参阅用户模式(User Mode)。否则,此标志不执行任何操作。K_INHERIT_PERMS:如果CONFIG_USERSPACE启用,则该线程将继承父线程具有的所有内核对象许可权,但父线程对象除外。请参阅用户模式(User Mode)
6. Thread Custom Data - (线程自定义数据)
每个线程都有一个 32 位的自定义数据区,只能由线程本身访问,并且可以由应用程序出于其选择的任何目的使用。线程的默认自定义数据值为零。
Note: 自定义数据支持不适用于 ISR,因为它们在单个共享的内核中断处理上下文中运行。
默认情况下,线程自定义数据支持是禁用的。配置选项 CONFIG_THREAD_CUSTOM_DATA 可用于启用支持。
k_thread_custom_data_set() 和 k_thread_custom_data_get() 函数分别用于写入和读出的线程的自定义数据。一个线程只能访问自己的自定义数据,而不能访问另一个线程的自定义数据。
以下代码使用自定义数据功能来记录每个线程调用特定例程的次数。
Note: 显然,只有一个例程可以使用此技术,因为它垄断了自定义数据功能的使用。
int call_tracking_routine(void)
uint32_t call_count;
if (k_is_in_isr())
/* ignore any call made by an ISR */
else
call_count = (uint32_t)k_thread_custom_data_get();
call_count++;
k_thread_custom_data_set((void *)call_count);
/* do rest of routine's processing */
...
使用线程自定义数据,通过将自定义数据用作指向线程拥有的数据结构的指针,可以使例程访问线程特定的信息。
7. Implementation - (实现)
7.1 Spawning a Thread - (创建线程)
通过定义线程的堆栈区域和线程控制块,然后调用 k_thread_create() 来生成线程。
必须使用 K_THREAD_STACK_DEFINE 或 K_KERNEL_STACK_DEFINE 定义堆栈区域,以确保在内存中正确设置了堆栈区域。
堆栈的大小参数必须是以下三个值之一:
- 原始请求的堆栈大小传递给
K_THREAD_STACK或K_KERNEL_STACK堆栈实例化宏系列。 - 对于使用
K_THREAD_STACK宏系列定义的堆栈对象,该对象的返回值K_THREAD_STACK_SIZEOF()。 - 对于使用
K_KERNEL_STACK宏系列定义的堆栈对象,该对象的返回值K_KERNEL_STACK_SIZEOF()。
线程产生函数返回其线程 ID,该 ID 可用于引用线程。
示例: 以下代码产生一个立即启动的线程
#define MY_STACK_SIZE 500
#define MY_PRIORITY 5
extern void my_entry_point(void *, void *, void *);
K_THREAD_STACK_DEFINE(my_stack_area, MY_STACK_SIZE);
struct k_thread my_thread_data;
k_tid_t my_tid = k_thread_create(&my_thread_data, my_stack_area,
K_THREAD_STACK_SIZEOF(my_stack_area),
my_entry_point,
NULL, NULL, NULL,
MY_PRIORITY, 0, K_NO_WAIT);
或者,可以在编译时通过调用 K_THREAD_DEFINE 来声明线程。该宏会自动定义堆栈区域,控制块和线程 ID 变量。上面的代码可改为下面这种方式:
#define MY_STACK_SIZE 500
#define MY_PRIORITY 5
extern void my_entry_point(void *, void *, void *);
K_THREAD_DEFINE(my_tid, MY_STACK_SIZE,
my_entry_point, NULL, NULL, NULL,
MY_PRIORITY, 0, 0);
Note: k_thread_create() 的延时参数是一个 k_timeout_t 值,因此 K_NO_WAIT 意味着立即启动线程。K_THREAD_DEFINE 的对应参数是持续时间(以整数毫秒为单位),因此等效参数为 0。
User Mode Constraints - (用户模式限制)
本部分仅在 CONFIG_USERSPACE 启用后才适用,并且一个用户线程尝试创建一个新线程。该 k_thread_create() API 仍在使用,但必须满足其他约束条件,否则调用线程将被终止:
- 调用线程必须在子线程和堆栈参数上均具有授予的权限;两者都由内核作为内核对象进行跟踪。
- 子线程和堆栈对象必须处于未初始化状态,即当前未运行,并且未使用堆栈内存。
- 传入的堆栈大小参数必须等于或小于声明时的堆栈对象范围。
K_USER必须使用该选项,因为用户线程只能创建其他用户线程。K_ESSENTIAL该选项不得被使用,否则用户线程可能不会被视为必要线程(essential threads)。- 子线程的优先级必须是有效的优先级值,并且等于或小于父线程的优先级。
7.2 Dropping Permissions - (降低权限)
如果启用了 CONFIG_USERSPACE,则在超级用户模式下运行的线程可以使用 k_thread_user_mode_enter() API 向用户模式进行单向转换。它将重置线程的堆栈内存并将其清零。该线程将被标记为非必需(non-essential)。
7.3 Terminating a Thread - (终止线程)
线程通过从其入口点函数返回而终止自身。
以下代码说明了线程可以终止的方式:
void my_entry_point(int unused1, int unused2, int unused3)
while (1)
...
if (<some condition>)
return; /* thread terminates from mid-entry point function */
...
/* thread terminates at end of entry point function */
如果启用了 CONFIG_USERSPACE,则中止线程将另外将该线程和堆栈对象标记为未初始化,以便可以重新使用它们。
8. Runtime Statistics - (运行时统计信息)
如果 CONFIG_THREAD_RUNTIME_STATS 启用,则可以收集和检索线程运行时统计信息 ,例如,线程的执行周期总数。
默认情况下,使用默认内核计时器来收集运行时统计信息。对于某些体系结构,SoC 或开发板,有些计时器可以通过计时功能提供更高的分辨率。这些计时器的使用可以通过启用 CONFIG_THREAD_RUNTIME_STATS_USE_TIMING_FUNCTIONS。
例如:
k_thread_runtime_stats_t rt_stats_thread;
k_thread_runtime_stats_get(k_current_get(), &rt_stats_thread);
printk("Cycles: %llu\\n", rt_stats_thread.execution_cycles);
9. Suggested Uses - (建议用途)
使用线程来处理 ISR 无法处理的进程。
使用单独的线程来处理可以并行执行的逻辑上不同的处理操作。
10. Configuration Options - (配置选项)
相关配置选项:
CONFIG_MAIN_THREAD_PRIORITYCONFIG_MAIN_STACK_SIZECONFIG_IDLE_STACK_SIZECONFIG_THREAD_CUSTOM_DATACONFIG_NUM_COOP_PRIORITIESCONFIG_NUM_PREEMPT_PRIORITIESCONFIG_TIMESLICINGCONFIG_TIMESLICE_SIZECONFIG_TIMESLICE_PRIORITYCONFIG_USERSPACE
11. API Reference - (API 参考)
参考链接
https://docs.zephyrproject.org/latest/reference/kernel/threads/index.html
以上是关于Zephyr RTOS -- Threads的主要内容,如果未能解决你的问题,请参考以下文章